






Transformer是目前最常见的AI大语言模型架构,以下是Transformer架构的CPU和GPU版本前向推理代码实现,并且会会自动计算推理时间。我们可以比较两者的性能差异,感受使用GPU所带来的性能提升。为了降低示例的硬件运行门槛,我们需要简化层数和头数。比如,定义一个小型的Transformer模型,比如有12层,每层有12个注意力头,隐藏层维度为768,这样比较接近BERT-base的结构。
代码实现流程:
-
定义模型结构:基于Transformer的模型,指定参数如层数、头数、隐藏维度等。
-
CPU版本:模型在CPU上,输入数据在CPU,用time模块记录时间。
-
GPU版本:模型在CUDA上,数据移动到CUDA,用CUDA事件或同步后的时间记录。
-
生成示例输入,如随机的token IDs。
-
执行前向推理,测量并打印时间。
-
确保代码正确,比如模型结构正确,张量尺寸正确,时间测量准确。
import torch
import torch.nn as nn
import math
import time
# 公共配置参数
config = {
"vocab_size": 50257, # GPT-2的词汇表大小
"seq_len": 1024, # 序列长度
"batch_size": 8, # 批大小
"d_model": 768, # 隐藏层维度
"nhead": 12, # 注意力头数
"num_layers": 12, # Transformer层数
"dim_feedforward": 3072, # FFN维度
"device": "cpu" # 初始设备设置
}
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(1)]
return x
class TransformerModel(nn.Module):
def __init__(self, config):
super().__init__()
self.embedding = nn.Embedding(config["vocab_size"], config["d_model"])
self.pos_encoder = PositionalEncoding(config["d_model"])
encoder_layer = nn.TransformerEncoderLayer(
d_model=config["d_model"],
nhead=config["nhead"],
dim_feedforward=config["dim_feedforward"],
# batch_first=False # PyTorch默认使用(seq_len, batch, features)
batch_first=True # PyTorch默认使用(seq_len, batch, features)
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=config["num_layers"])
self.fc = nn.Linear(config["d_model"], config["vocab_size"])
def forward(self, src):
src = self.embedding(src) * math.sqrt(config["d_model"])
src = self.pos_encoder(src)
# src = src.permute(1, 0, 2) # 转换为(seq_len, batch, features)
output = self.transformer(src)
return self.fc(output)
# CPU版本
def cpu_version():
config["device"] = "cpu"
torch.set_num_threads(8) # 设置CPU线程数
model = TransformerModel(config).to(config["device"])
model.eval()
# 生成随机输入
inputs = torch.randint(0, config["vocab_size"],
(config["batch_size"], config["seq_len"])).to(config["device"])
# 预热
with torch.no_grad():
_ = model(inputs)
# 正式计时
start_time = time.time()
with torch.no_grad():
_ = model(inputs)
elapsed = time.time() - start_time
print(f"CPU推理时间: {elapsed:.4f}秒")
# GPU版本
def gpu_version():
if not torch.cuda.is_available():
print("CUDA不可用")
return
config["device"] = "cuda"
torch.backends.cudnn.benchmark = True # 启用cuDNN基准优化
model = TransformerModel(config).to(config["device"])
model.eval()
# 生成随机输入
inputs = torch.randint(0, config["vocab_size"],
(config["batch_size"], config["seq_len"])).to(config["device"])
# 预热
with torch.no_grad():
for _ in range(3): # 多次预热确保CUDA初始化完成
_ = model(inputs)
# 精确计时
starter = torch.cuda.Event(enable_timing=True)
ender = torch.cuda.Event(enable_timing=True)
starter.record()
with torch.no_grad():
_ = model(inputs)
ender.record()
torch.cuda.synchronize()
elapsed = starter.elapsed_time(ender) / 1000 # 转换为秒
print(f"GPU推理时间: {elapsed:.4f}秒")
if __name__ == "__main__":
print("运行CPU版本:")
cpu_version()
print("\n运行GPU版本:")
gpu_version()
代码说明:
-
模型架构:
- 使用标准的Transformer编码器架构
- 包含词嵌入层、位置编码层、12层Transformer编码器和最后的线性输出层
- 参数配置参考GPT-2的小型配置
-
CPU版本特点:
- 使用纯CPU计算
- 设置8个CPU线程进行并行计算
- 使用Python标准库time进行计时
-
GPU版本特点:
- 自动检测CUDA可用性
- 使用CUDA事件进行精确计时
- 启用cuDNN基准优化加速计算
- 进行多次预热确保CUDA上下文初始化完成
-
性能差异:
- 实际性能取决于具体硬件配置
- GPU版本通过并行计算和硬件加速获得显著优势
代码运行示例:
- 运行环境:CPU为Ryzen 9 7945HX(16核心32线程),GPU为NVIDIA Geforce RTX 4060 8G显存,操作系统为Win 11 64位专业版
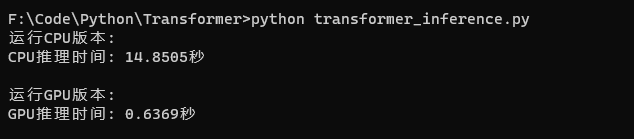
对比CPU,使用GPU,可以带来20倍的性能提升。
注意:
- 首次运行GPU版本会有CUDA上下文初始化时间
- 实际应用中需要根据硬件调整batch_size和序列长度
- 对于生产环境建议使用混合精度训练和推理优化
- 更复杂模型需要配合模型并行和流水线并行技术


















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









