









为什么要对数据进行归一化?
在喂给机器学习模型的数据中,对数据要进行归一化的处理。
为什么要进行归一化处理,下面从寻找最优解这个角度给出自己的看法。
假定为预测房价的例子,自变量为面积,房间数两个,因变量为房价。
那么可以得到的公式为:

首先我们祭出两张图代表数据是否均一化的最优解寻解过程。
未归一化:
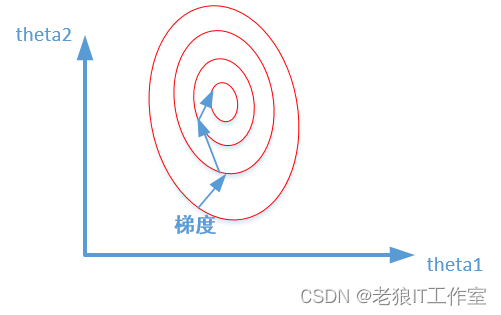
归一化之后:
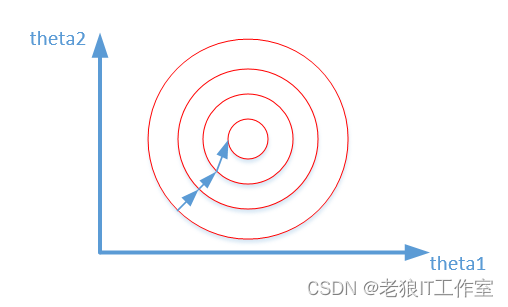
为什么会出现上述两个图,并且它们分别代表什么意思。
我们在寻找最优解的过程也就是在使得损失函数值最小的theta1,theta2。
上述两幅图代表的是损失函数的等高线。
我们很容易看出,当数据没有归一化的时候,面积数的范围可以从0~1000,房间数的范围一般为0~10,可以看出面积数的取值范围远大于房间数。
这样造成的影响就是在画损失函数的时候,
数据没有归一化的表达式,可以为:

造成图像的等高线为类似椭圆形状,最优解的寻优过程就是像下图所示:
而数据归一化之后,损失函数的表达式可以表示为:
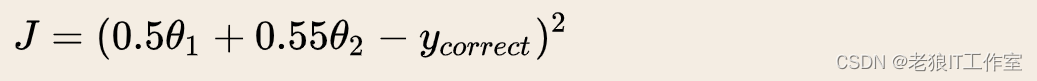 其中变量的前面系数几乎一样,则图像的等高线为类似圆形形状,最优解的寻优过程像下图所示:
其中变量的前面系数几乎一样,则图像的等高线为类似圆形形状,最优解的寻优过程像下图所示:
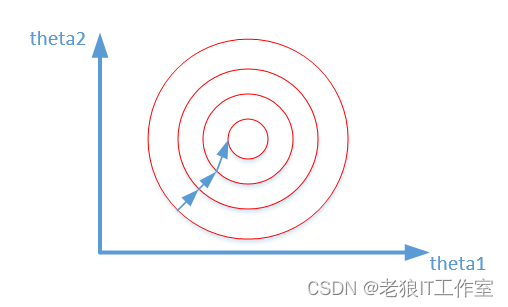
从上可以看出,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
这也是数据为什么要归一化的一个原因。
特别说明:这部分内容来自参考资料的“为什么要对数据进行归一化处理?”。
如何理解归一化?
在机器学习领域中,不同评价指标(即特征向量中的不同特征就是所述的不同评价指标)往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,
为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。其中,最典型的就是数据的归一化处理。
简而言之,归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。
奇异样本数据是指相对于其他输入样本特别大或特别小的样本矢量。
比如,下面为具有两个特征(列向量)的样本数据x1、x2、x3、x4、x5、x6,其中x6这个样本的两个特征相对其他样本而言相差比较大,因此,x6认为是奇异样本数据。

奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛,因此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在奇异样本数据时,则可以不进行归一化。
归一化的前后对比
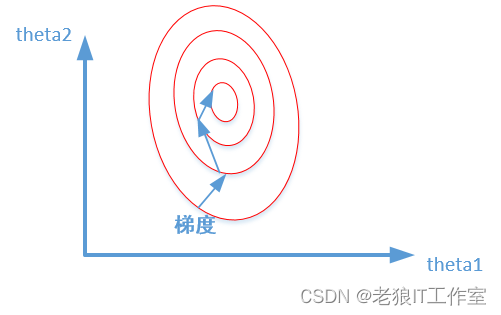
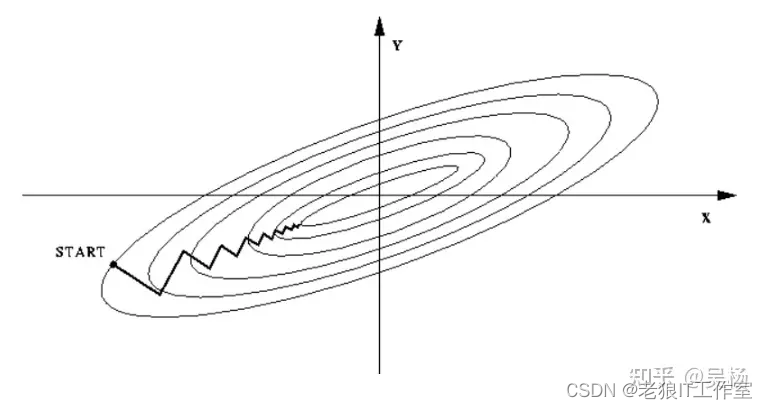
如果不进行归一化,那么由于特征向量中不同特征的取值相差较大,会导致目标函数变“扁”。这样在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路,即训练时间过长,如下图所示:
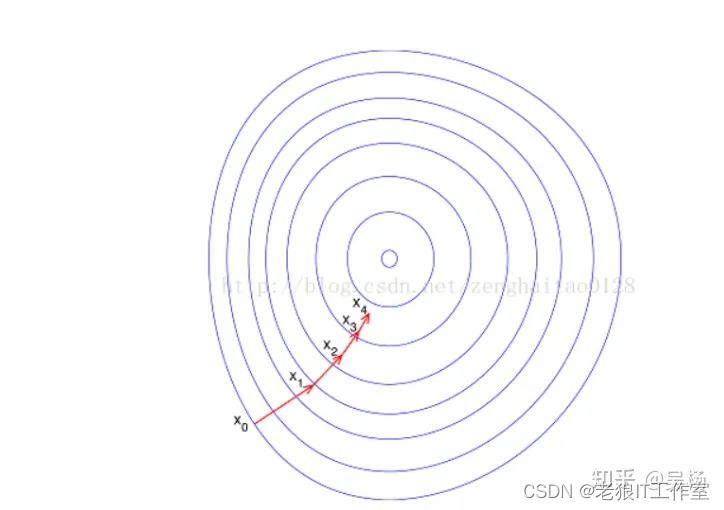
如果进行归一化以后,目标函数会呈现比较“圆”,这样训练速度大大加快,少走很多弯路,如下图所示:
综上可知,归一化有如下好处,即
1)归一化后加快了梯度下降求最优解的速度,也即加快训练网络的收敛性;
2)归一化有可能提高精度。
特别说明:这部分内容来自参考资料的“如何理解归一化(normalization)?”。
几种常用的归一化或标准化的方法
标准化和归一化是特征缩放(feature scaling)的主要手段,其核心原理可以简单地理解为:让所有元素先减去同一个数,然后再除以另一个数,在数轴上呈现的效果就是:先将数据集整体平移到有某个位置,然后按比例收缩到一个规定的区间内(范数归一化除外)。各种特征缩放手段的不同之处在于:他们减去和除以的数字不同,这决定了它们平移后的位置和缩放后的区间。特征缩放的目的是去除数据单位(量纲)的影响,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
最大最小标准化(Min-Max Normalization)

(1) 线性函数将原始数据线性化的方法转换到[0 1]的范围, 计算结果为归一化后的数据,X为原始数据
(2) 本归一化方法比较适用在数值比较集中的情况;
(3) 缺陷:如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量来替代max和min。
应用场景:在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用此方法或其他归一化方法(不包括Z-score方法)。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
z-score 标准化

其中,μ、σ分别为原始数据集的均值和方差。
(1) 将原始数据集归一化为均值为0、方差1的数据集
(2) 该种归一化方式要求原始数据的分布可以近似为高斯分布(正太分布),否则归一化的效果会变得很糟糕。
应用场景:在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score 标准化表现更好。
PCA技术(Principal Component Analysis)是一种常用的数据降维方法,它可以将高维数据映射到低维空间中,同时保留尽可能多的数据信息。
神经网络归一化
本归一化方法经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。
该方法包括 log,正切等,需要根据数据分布的情况,决定非线性函数的曲线:
(1)log对数函数归一化
y = log10(x)
即以10为底的对数转换函数,对应的归一化方法为:
x' = log10(x) /log10(max)
其中max表示样本数据的最大值,并且所有样本数据均要大于等于1。
numpy.log10 — NumPy v1.26 Manual
(2)反正切函数归一化
x' = atan(x)*(2/pi)
使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上。
numpy.arctan — NumPy v1.26 Manual
L2范数归一化
定义:特征向量中每个元素均除以向量的L2范数:

范数归一化和z-score标准差归一化、Min-Max归一化等其他归一化方法是完全不同的缩放手段,它缩放的是向量。
scikit-learn库中标准化或归一化的方法
MinMaxScaler类 - “最大最小标准化(Min-Max Normalization)
MinMaxScaler类是scikit-learn中常用的数据预处理方法之一,对应前面的“最大最小标准化(Min-Max Normalization)”。它可以将数据按比例缩放到一个指定的范围(通常是[0,1])内。具体来说,对于每个特征,它会找到该特征的最小值和最大值,然后将最小值的数据设为0,最大值的数据设为1,其他数据则按比例缩小到0和1之间。



下面是一个使用MinMaxScaler进行数据预处理的示例代码:
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 创建一个10x1随机数组
data = np.random.rand(10, 1)
# 创建MinMaxScaler对象并对数据进行拟合和转换
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data)
print("Original data:\n", data)
print("Scaled data:\n", scaled_data)输出:
Original data:
[[0.31024664]
[0.85718579]
[0.06955117]
[0.9609241 ]
[0.89061671]
[0.80214054]
[0.50784165]
[0.34568602]
[0.35104434]
[0.15798502]]
Scaled data:
[[0.2700278 ]
[0.88361963]
[0. ]
[1. ]
[0.92112461]
[0.8218663 ]
[0.4917027 ]
[0.309786 ]
[0.31579731]
[0.09921083]]StandardScaler类(z-score标准化)
Z-score是一种常用的数据标准化方法,它可以将原始数据按比例缩放,使其均值为0,标准差为1。在Python中,可以使用scikit-learn库中的StandardScaler类来计算Z-score。



下面是一个使用StandardScaler计算Z-score的示例代码:
from sklearn.preprocessing import StandardScaler
import numpy as np
# 创建一个符合正太分布的10x1随机数组
data = np.random.randn(10, 1)
# 使用StandardScaler进行标准化处理
standard_scaler = StandardScaler()
standard_scaled_data = standard_scaler.fit_transform(data)
print("Original data:\n", data)
print("StandardScaled data:\n", standard_scaled_data)输出:
Original data:
[[-0.69510903]
[-1.15608677]
[-0.76831287]
[ 0.47380698]
[ 0.36857006]
[ 0.82884027]
[ 0.2112434 ]
[ 0.49386235]
[-0.89261534]
[-0.29554126]]
StandardScaled data:
[[-0.82977114]
[-1.52274847]
[-0.9398168 ]
[ 0.92743363]
[ 0.76923338]
[ 1.46114708]
[ 0.5327278 ]
[ 0.95758241]
[-1.12667788]
[-0.22911002]]Normalizer类(L2范数归一化)
Normalizer是一种常用的数据预处理方法,它可以将原始数据按比例缩放,使其均值为0,标准差为1。在Python中,可以使用scikit-learn库中的Normalizer类来计算L2范数归一化。



按“行”范数归一化
如果我们打算按“行”进行范数归一化,则每一行会被视为一个向量,由于我们的数据一行只有一个元素,即一个向量只有一个分量,套用范数归一化的计算公式可知,不管是什么值,计算出的结果都为1。
from sklearn.preprocessing import Normalizer
import numpy as np
# 创建一个随机10x1数组
data = np.random.rand(10, 1)
# 创建Normalizer对象并对数据进行拟合和转换
normalizer = Normalizer()
normalized_data = normalizer.fit_transform(data)
print("Original data:", data)
print("Normalized data:", normalized_data)输出:
Original data: [[0.72778373]
[0.07109779]
[0.04295321]
[0.92648521]
[0.99412893]
[0.09707909]
[0.95332802]
[0.04867314]
[0.39227923]
[0.97322251]]
Normalized data: [[1.]
[1.]
[1.]
[1.]
[1.]
[1.]
[1.]
[1.]
[1.]
[1.]]按“列”范数归一化
如果我们打算按“列”进行范数归一化,则每一列会被视为一个向量。
from sklearn.preprocessing import Normalizer
import numpy as np
# 创建一个随机1x10数组
data = np.random.rand(1, 10)
# 创建Normalizer对象并对数据进行拟合和转换
normalizer = Normalizer()
normalized_data = normalizer.fit_transform(data)
print("Original data:\n", data)
print("Normalized data:\n", normalized_data)输出:
Original data:
[[0.01981939 0.79937458 0.61082445 0.64022951 0.22634141 0.29765169
0.60833544 0.51709269 0.14774151 0.16873684]]
Normalized data:
[[0.01321299 0.53291919 0.40721844 0.42682191 0.15089507 0.1984355
0.40555909 0.34473027 0.09849486 0.11249182]]
















 1939
1939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











