







 本文详细介绍了YOLO目标检测算法的数据集格式,包括图像文件、标注文件(含类别ID、位置信息)和类别文件(类别名称及其编码)。同时提出使用classes.json文件管理类别信息以便于训练和呈现中文标签。
本文详细介绍了YOLO目标检测算法的数据集格式,包括图像文件、标注文件(含类别ID、位置信息)和类别文件(类别名称及其编码)。同时提出使用classes.json文件管理类别信息以便于训练和呈现中文标签。
YOLO (You Only Look Once) 是一种目标检测算法,它使用了一个单独的神经网络来同时识别图像中的多个对象。它可以支持一下多种的训练数据集的格式。其中YOLO数据集格式是非常常用的一种。
YOLO DataSet Format - Ultralytics YOLOv8 Docs
YOLO数据集格式
YOLO数据集的格式主要包括以下几部分:
- 图像文件: 这是数据集中的图像文件,通常是jpg或png格式。
- 标注文件: 这是一个文本文件,包含了每张图像中目标对象的类别和位置信息。
- 类别文件: 这是一个文本文件,包含了数据集中所有目标对象的类别信息。



注意:除扩展名外,标注文件的名称必须和图像的名称保持一致哦。
标注文件格式
主要包含了以下内容:
- 每个目标对象的类别编号
- 目标对象在图像中的中心位置 (x,y)
- 目标对象的宽度和高度 (w,h)
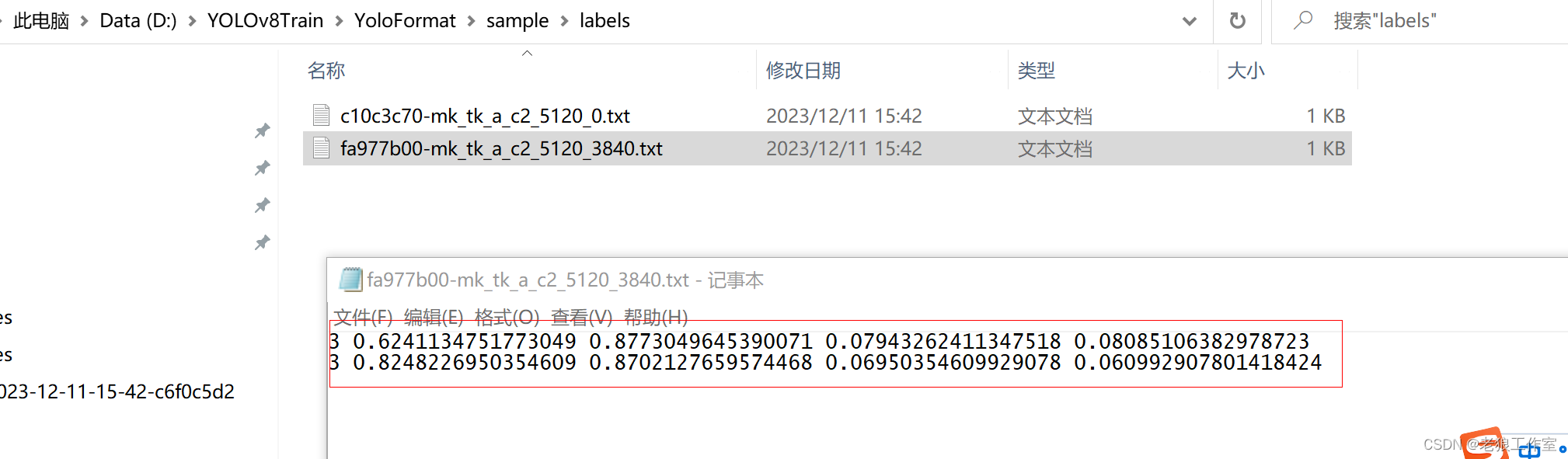 备注:
备注:
1) 列1 - 目标类别id , 列2 - 目标中心位置x, 列3 - 目标中心位置y, 列4 - 目标宽度w,列5 - 目标高度h。
2)x,y,w,h是小于1的浮点数,因为是经过对图像进行了归一化处理得到的值,也就是目标的真实的x,w值除以图像的宽度,y,h除以图像的高度。
类别文件格式
主要包含了以下内容:
- 每个类别的编号
- 每个类别的名称
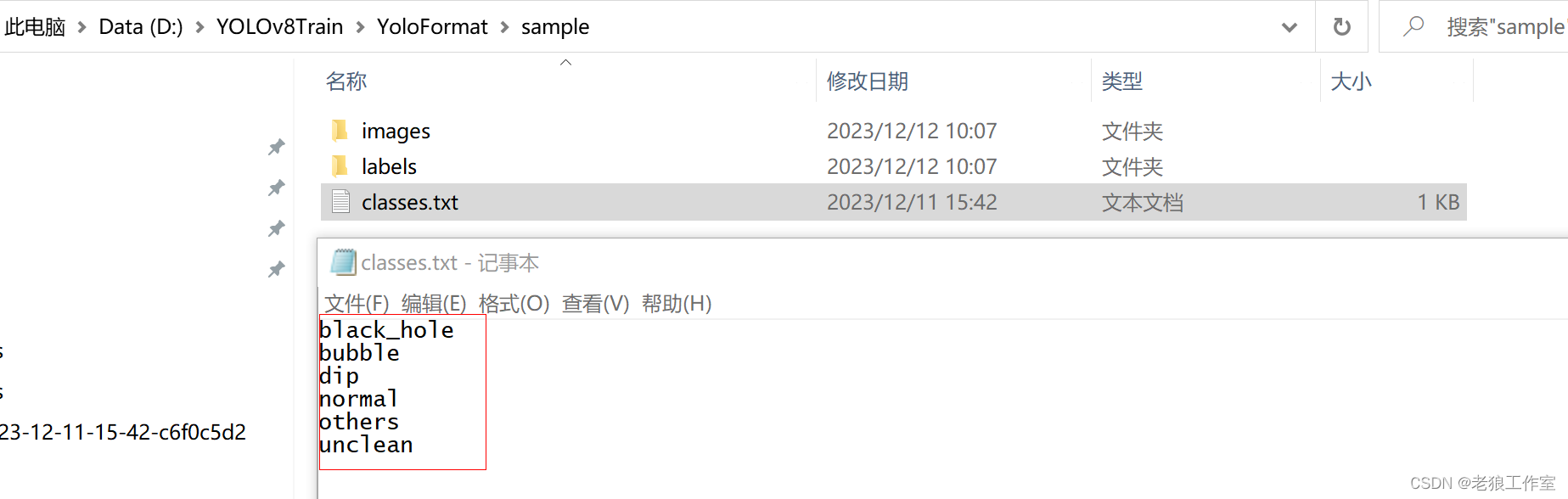
备注:一行代表一个类别,行号代表类别id,比如normal是类别名称,它在第四行,那么它的类别id为3(索引从0开始),比如上面的显示的图像的标注文件,有2个类别为normal的目标。
一点小思考
YOLO的类别文件一行代表一个类别名称,行号代表类别id,这样似乎不能够很好的描述数据集的类别信息。我们可以考虑使用classes.json文件来描述数据集的类别信息:
{
"categories": [
{
"id": 0,
"name": "black_hole",
"zh_name": "黑孔"
},
{
"id": 1,
"name": "bubble",
"zh_name": "气泡"
},
{
"id": 2,
"name": "dip",
"zh_name": "凹陷"
},
{
"id": 3,
"name": "normal",
"zh_name": "正常",
},
{
"id": 4,
"name": "others",
"zh_name": "其它"
},
{
"id": 5,
"name": "unclean",
"zh_name": "研磨不净"
}
],
"info": {
"year": 2023,
"version": "1.0"
}
}这样方便我们通过classes.json文件生成classes.txt用于训练,呈现时使用中文标签。



















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











