







k最近邻(k-Nearest Neighbor)
思想:如果一个样本在特征空间中的k个最近邻(最相似)的样本中的大多数都属于某一个类别,则该样本也属于这个类别
流程:
- 第一阶段:首先我们事先定下k值(就是指最近邻居的个数)
- 第二阶段:确定的距离度量公式——文本分类一般使用夹角余弦,得出待分类数据点和所有已知类别的样本点中, 选择距离最近的 k 个样本。
-
- 夹角余弦公式:
- 夹角余弦公式:
- 第三阶段:统计这k个样本点中,各个类别的数量。根据k个样本中,数量最多的样本是什么类别,我们就把这个数据点定为什么类别。
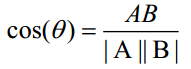















 2065
2065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









