







--整理来源:《hadoop权威指南第三版》、《hadoop官网doc文档》
--本文原创,转载请注明
看了好多前人们在hadoop配置上留下的足迹,一时没有发现一篇全面、通熟易懂的,的确让我这个新手菜鸟十分苦恼。所以将一些资料进行了整理并加上了自己的理解。能够帮助后继者
快速完成Hadoop安装,以便对Hadoop分布式文件系统(HDFS)和Map-Reduce框架有所体会。
笔者的配置环境:
- Linux distributions:CentOS 7.1 64位,VM虚拟机
- Hadoop 2.7.1(Stable)
-->先决条件
Hadoop目前同时支持Linux与Windows平台,在Linux上已经得到了较好的运行与验证。在Windows下需要安装Cygwin(
https://www.cygwin.com/
)插件提供除了JDK,SSH之外的shell支持。
前面的linux知识中也提到Window优势在于用户界面的亲和,系统操作容易上手,网上也有大牛在windows上玩得十分的爽快,鉴于自己先天性的手抽综合症,还是选择了大众化的虚拟机+Linux,不然玩着玩着把整个windows玩崩了,就是在玩火了。
- GNU/Linux是产品开发和运行的平台。 Hadoop已在有2000个节点的GNU/Linux主机组成的集群系统上得到验证。
- Win32平台是作为开发平台支持的。由于分布式操作尚未在Win32平台上充分测试,所以还不作为一个生产平台被支持。
-->需要的环境
- JavaTM1.5.x,必须安装,建议选择Sun公司发行的Java版本。
- ssh 必须安装并且保证 sshd一直运行,以便用Hadoop 脚本管理远端Hadoop守护进程。
-->需要准备
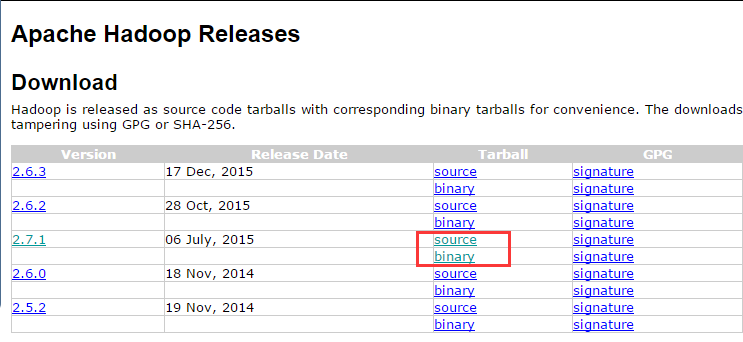
- 下载最近发布的hadoop稳定版(http://hadoop.apache.org/releases.html),可以从镜像网站上下载。这样速度可能会快一些。记得是在CentOS linux系统中的浏览器下载,windows中的文件是无法像平时鼠标一拖直接扔过去的。图中source指的是源代码,需要编译之后才能使用,binary指的是已经编译好的二进制文件,能直接解压缩使用,所以我们直接下载binary(约200M)。
- 虚拟机的联网环境。Centos通过yum来安装软件,需要联网的环境。这里就要吐槽一下使用锐捷客户端的校园网了,网卡地址冲突,目前已经不想解决了,放弃校园网了。
-->了解Hadoop的三种安装模式
- 单机模式 (standalone): 单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
- 伪分布式模式 (Pseudo-Distributed Mode):在单节点上以一种伪分布式模式运行。就是假装是分布式多台机,实际上只有一个节点, 所有的守护进程都运行在同一台机器上。有点像古语里面的”草木皆兵“,适合个人在没有硬件的情况下去搭建hadoop集群,入门学习。所以接下来的主要都是使用伪分布式去搭建集群的过程。
- 完全分布式模式 (Fully Distributed Mode):就是真正意义上的集群了,部署在多台机上,有待学习研究,再来更新。
-->安装SSH
- 创建用户
首先最好先为CentOS Linux创建一个hadoop的用户,在以后的漫漫学习长路上,如果只使用单个用户说不定就劈腿了,我想还是很有必要的。
- 在终端(文字界面)中输入"su",按下回车。
- 输入root账户的密码,这个是在安装linux的过程中设定的,注意一点:屏幕中不会显示输入的内容,实际上是有输入的,所以看着键盘一鼓作气输完它,不要停顿。。
- 接着在root用户中输入 useradd -m hadoop -s /bin/bash,创建hadoop用户,接着输入“passwd hadoop”为该用户设置登录密码。
-
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题,在当前的root用户执行:“visudo”,按下Esc键,输入:98,回车,然后如图下增加一行内容。再按下Esc键,输入":wq",按下回车键即可。

几个注意点:
- vi是一种编辑器,输入“:wq”是保存编辑器修改的方法。
- 完成之后,切换用户或者重启虚拟机,选择hadoop用户登录。
- 之后使用“su”/"su hadoop"可实现用户的快速切换。
- 安装SSH(Secure Shell)
CentOS 使用yum来进行软件的在线安装,CentOS linux已经默认安装了SSH client与SSH server,所以可以不必再安装,若没有安装则可以在终端中输入下面两行
来完成联网安装:
sudo yum install openssh-clients
sudo yum install openssh-server
输入"ssh localhost"测试是否可用,第一次登录需要输入“yes”,接着输入hadoop用户的密码,登录到本机。每次都输入密码十分地麻烦,所以可以配置免密钥登录。先改变当前目录,生成秘钥,加入到授权中,这样省去带上路径的麻烦。下面两种都是可行的。


几点说明:
- ~表示的是用户的主文件夹,即“/home/用户名”,例如现在你使用hadoop用户,即表示“/home/hadoop”。
- -t rsa/-t dsa 指的是生成秘钥的类型,即加密的方式。上网查DSA 用于签名,而 RSA 可用于签名和加密。具体可以上网找下资料,指的是加密的算法。两种都可以在这里使用。强迫症患者可以放心了。
- 设置好之后,再次输入“ssh localhost”,就可以免密登录了。输入“exit”退出ssh登录。
-->安装Java环境
建议选择Sun公司发行的Java版本,同样地,
CentOS 7.1
中也默认安装了
OpenJDK ,但是CentOS默认安装的只是
Java JRE,即运行环境,而不是 JDK,我们可以在终端中输入“java -version”与“rpm -qa | grep java”来查看当前安装的版本与详细信息。搬砖之路任重道远,为了今后有不时之需,这里还是需要重新去安装JDK。
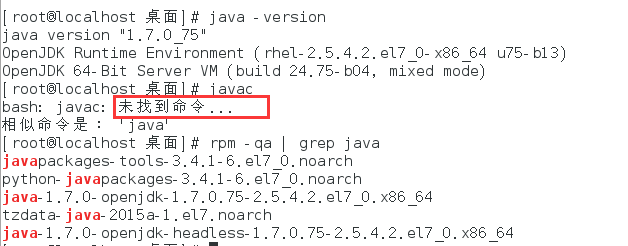

- 卸载原来的openjdk
上面我们已经通过
“rpm -qa | grep java”输出了linux自带jdk的具体信息,接着在终端【root】中输入命令来卸载openjdk,不断版本的centos自带的openjdk型号也不同,大家要写准版本号。
[root@localhost ~]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.75-2.5.4.2.el7_0.x86_64
[root@localhost ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64
- 安装JDK
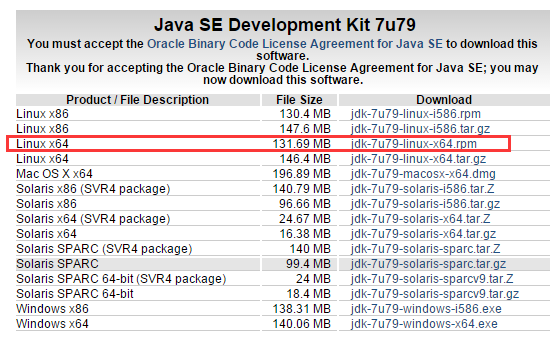
在oracle官网上下载linux版的JDK(
http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk7-downloads-1880260.html
),根据CentOS的版本选择位数,x86指的是32位,x64指的是64位。我们选择64位。有两种方式来下载:
- 直接在虚拟机的浏览器中下载,并存放在/usr/local/目录下。
- 在windows上下载,通过ftp的方式上传至linux的/usr/local/目录。再次吐槽一下校园网,虚拟机连不上网,所以用这个方式更加简单粗暴了。windows与虚拟机linux通信需要设置静态IP/防火墙/ftp等,后续会更新。
下载完成后,在终端中输入“ rpm -ivh jdk-7u79-linux-x64.rpm”来执行安装命令,JDK默认安装在/usr/java下。完成后,可以输入
"javac" "java"
“java -version”等命令来验证。
- 配置环境变量
与我们熟悉的windows操作系统类似,需要设置好系统的环境变量,就像地铁里面功能齐全的指示一样,告诉行人怎样坐车怎样出站。在root用户下输入“vi /etc/profile ”,在最后加入以下几行:

















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









