







智能优化算法:鹰栖息优化算法
摘要:鹰栖息优化算法(eagle perching optimizer,EPO)是于2018年提出的一种新型智能优化算法,该算法主要模拟了老鹰栖息的天性。具有结构简单,速度快的特点。
1.算法原理
在 EPO 算法中,每只鹰的初始位置随机生成,使种群在搜索空间内均匀分布,有利于算法寻优。
x
=
l
b
+
(
u
b
−
l
b
)
∗
r
a
n
d
(1)
x=lb+(ub-lb)*rand\tag{1}
x=lb+(ub−lb)∗rand(1)
其中
x
x
x为初始位置,
l
b
lb
lb为寻优下边界,
u
b
ub
ub为寻优上边界。
EPO 算法的搜索范围更新如下:
s
=
s
∗
e
t
a
(2)
s=s*eta \tag{2}
s=s∗eta(2)
其中:
s
s
s 是搜索范围变量,实现算法在全局搜索和局部搜索之间的转变;
e
t
a
eta
eta 是收缩变量。eta的计算如下式:
e
t
a
=
(
r
e
s
s
)
t
/
t
s
(3)
eta=(\frac{res}{s})^{t/ts} \tag{3}
eta=(sres)t/ts(3)
其中ts为最大迭代次数,res为分辨率范围。
每只鹰的位置更新如下:
x
i
t
+
1
=
x
m
i
n
t
+
Δ
x
i
(4)
x_i^{t+1}=x_{min}^t+\Delta x_i \tag{4}
xit+1=xmint+Δxi(4)
其中:
x
i
t
+
1
x_i^{t+1}
xit+1为迭代至
t
+
1
t +1
t+1次时第
i
i
i只鹰的位置;
x
m
i
n
t
x_{min}^t
xmint为迭代至
t
t
t次的全局最优位置;
Δ
x
i
=
s
∗
(
R
i
1
,
R
i
2
,
.
.
.
,
R
i
n
)
\Delta x_i=s*(R_{i1},R_{i2},...,R_{in})
Δxi=s∗(Ri1,Ri2,...,Rin)用来反映鹰在搜索范围内的随机移动,
R
i
n
R_{in}
Rin是( -1 , 1 )之间的随机数。
算法步骤:
步骤1: 初始化算法参数,包括搜索范围变量、收缩变量,迭代次数等。
步骤2:初始化种群;
步骤3:计算适应度度值,并保留最优位置;
步骤4:利用式(2)-(4)更新种群位置;
步骤5:判断是否满足停止条件,如果满足,则输出最优解,否则,重复步骤3-5。
2.实验结果
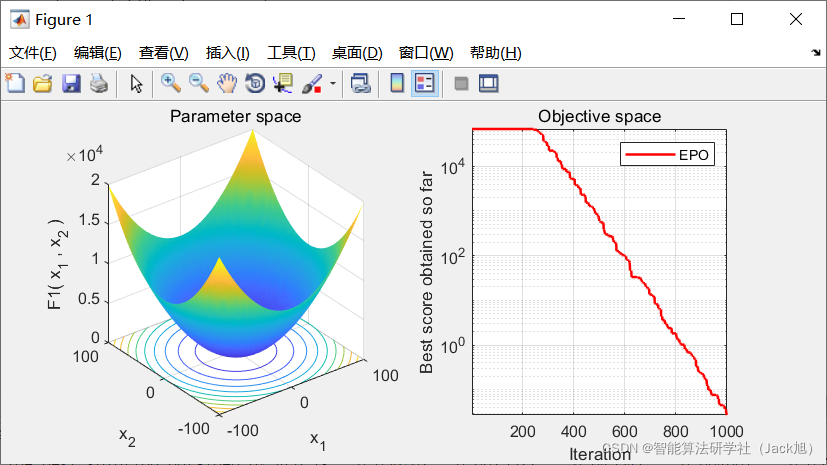
3.参考文献
[1] Khan A T , Senior S L , Stanimirovic P S , et al. Model-Free Optimization Using Eagle Perching Optimizer[J]. 2018.
















 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











