







摘要
小样本学习是一种通过少量样本训练分类器的方法,目前是一项比较困难的任务。目前比较有效的方法是基于元学习的预训练方法,首先在样本比较丰富的基础类别上训练一个特征提取器,然后在样本比较少的新类别上进行微调。然而实验表明微调对网络在新类别上的分类准确率的改进比较有限,本文发现,在用于预训练的基础类别数据集中,每个类别中样本的分布都比较紧凑,不同类别之间泾渭分明,而在样本比较少的新类别数据集中,各个类别中的样本分布比较混乱,不同类别的样本混在一起,不容易分开,即方差比较大。针对上述问题,该文对所有类别的类别词条进行处理,通过WordNet获得其属性词条,将所有类别词条与属性词条经GloVe计算得到词嵌入向量(即对英文单词进行数字化得到高维向量),补全单纯通过样本均值计算得到的原型,提出一种更加具有代表性的类别原型,然后将原始的原型与补全的原型进行高斯融合,得到最终的原型,在新类别数据集上进行N-way K-shot方式的元训练。5-way 1-shot训练后,模型在MiniImageNet的测试集上达到目前最高的73.13%分类准确率。
方法

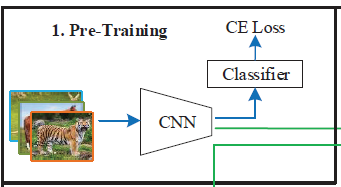
1. 预训练(Pre-Training)
在基础类别
C
b
a
s
e
C_{base}
Cbase数据集上,使用所有图像样本,以传统的梯度下降训练方法,使用比较大的batch_size(如128)、合适的学习率(如0.001)与学习率衰减策略、合适的优化器(如随机梯度下降,SGD),合适的损失函数(如交叉熵损失函数,CrossEntropyLoss,CE Loss),训练一个卷积神经网络(如ResNet-12),即骨干网络(backbone),训练完成后,删除网络中的所有全连接层(即下图中的Classifier),形成特征提取器
f
θ
f
f_{\theta_f}
fθf,
θ
f
\theta_f
θf表示特征提取器的所有参数。对该网络输入一张训练图像样本,即可输出样本的特征图,每个batch中的所有图像样本的特征图是多个空间分辨率较低,通道数很多的三维张量, 例如设置batch_size为128,则网络最终输出128个7x7x512的三维张量,可以形象理解为有512张7x7的矩阵沿第三维度叠起来形成一个长方体,这样的长方体有128个。
2. 学习如何补全原型(Learning to Complete Prototypes)
本文提出一种原型补全网络(ProtoComNet)作为元学习器,补全基于每个类别样本均值的原始原型。
-
Step 1
找到基础类别数据集 D b a s e D_{base} Dbase中第 k k k个类别词条 c k c_k ck的属性词条 a i a_i ai,例如袋鼠(kangaroo)具有长脸和白色腹部,则“长脸(long face)”和“白色腹部(white belly)”就是袋鼠这个类别词条的属性词条,斑马(zebra)也具有长脸,所以斑马的属性词条也包括“长脸“,另外斑马还有四条腿,所以“四条腿(four-footed)”也是斑马的属性词条。
通过WordNet可以轻松获得MiniImageNet数据集中所有类别词条的属性词条。
假设基础类别数据集 D b a s e D_{base} Dbase共含 K K K个基础类别 c k c_k ck,通过WordNet获得了所有 K K K个基础类别下的 F F F个属性词条 a i a_i ai。令集合 A A A表示所有属性词条 a i a_i ai的集合,有 A = { a i ∣ i = 1 , 2 , . . . , F } A=\{a_i|i=1,2,...,F\} A={ai∣i=1,2,...,F}令集合 C b a s e C_{base} Cbase表示 K K K个类别词条 c k c_k ck的集合,即 C b a s e = { c k ∣ k = 1 , 2 , . . . , K } C_{base}=\{c_k|k=1,2,...,K\} Cbase={ck∣k=1,2,...,K}令 w j w_j wj表示第 j j j个词条,集合 W W W表示所有词条 w j w_j wj的集合,有 W = { w j ∣ w j ∈ C b a s e ∪ A , j = 1 , 2 , . . . , K , K + 1 , . . . , K + F } W=\{w_j|w_j\in C_{base}\cup A,j=1,2,...,K,K+1,...,K+F\} W={wj∣wj∈Cbase∪A,j=1,2,...,K,K+1,...,K+F}令 r k j r_{kj} rkj表示类别词条 c k c_k ck和词条 w j w_j wj之间的关系,有 r k j = { 1 if w j 是 c k 的 属 性 词 条 1 if w j = c k 0 if otherwise r_{kj}=\begin{cases}1&\text{if }w_j是c_k的属性词条\\1&\text{if }w_j=c_k\\0&\text{if otherwise}\end{cases} rkj=⎩⎪⎨⎪⎧110if wj是ck的属性词条if wj=ckif otherwise令 R R R是所有 r k j r_{kj} rkj的集合,则有 r k j ∈ R , R ∈ R K × ( K + F ) r_{kj}\in R,R\in \R^{K\times {(K+F)}} rkj∈R,R∈RK×(K+F)。
使用GloVe算法对词条集合 W W W中的所有词条 w j w_j wj数字化,即 h ⃗ j = GloVe ( w j ) , \vec{h}_j=\text{GloVe}(w_j), hj=GloVe(wj),转化成相同长度的词嵌入向量 h ⃗ j ∈ R 1 × d \vec{h}_j \in \R ^{1\times d} hj∈R1×d, d d d是向量通道数。令 H H H表示所有 h ⃗ j \vec{h}_j hj的集合,有 H = { h ⃗ j ∣ j = 1 , 2 , . . . , K + F } , H ∈ R ( K + F ) × d H=\{\vec{h}_j|j=1,2,...,K+F\},H\in \R^{(K+F)\times d} H={hj∣j=1,2,...,K+F},H∈R(K+F)×d对于MiniImageNet数据集,共 K = 100 K=100 K=100类别, F = 71 F=71 F=71个属性词条,GloVe算法生成 d = 300 d=300 d=300的词嵌入向量,则 H H H是171x300的矩阵, R R R是171x171的稀疏矩阵。在矩阵 R R R中,由于共 K = 100 K=100 K=100个类别,因此从第101行开始,后面的所有元素都是0,矩阵中0的数量远大于1的数量,从而 R R R是一个稀疏矩阵。

-
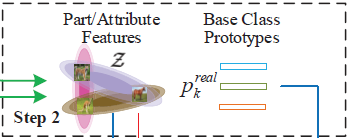
Step 2
在预训练出的特征提取器 f θ f f_{\theta_f} fθf和属性词条集合 A A A基础上,计算每个基础类别中所有样本特征图的平均值,得到每个基础类别的原型。具体来讲,对于第 k k k个基础类别 c k c_k ck,将一张属于 c k c_k ck类别的训练图像样本 x x x输入预训练阶段训练好的特征提取器 f θ f f_{\theta_f} fθf,得到 x x x的特征向量 f ⃗ x = f θ f ( x ) ∈ R 1 × s \vec{f}_x=f_{\theta_f}(x)\in \R^{1\times s} fx=fθf(x)∈R1×s, s s s是特征图通道数,若 f θ f = ResNet-12 f_{\theta_f}=\text{ResNet-12} fθf=ResNet-12,则 s = 512 s=512 s=512。以这种方式计算出 c k c_k ck类别下训练图像样本集合 D b a s e k D^k_{base} Dbasek中所有图像的特征向量,求平均值,得到基础类别 c k c_k ck的原型 p ⃗ k r e a l \vec{p}_k^{real} pkreal,即 p ⃗ k r e a l = 1 ∣ D b a s e k ∣ ∑ ( x , y ) ∈ D b a s e k f θ f ( x ) , p ⃗ k r e a l ∈ R 1 × s \vec{p}_k^{real}=\frac{1}{|D^k_{base}|}\sum_{(x,y)\in D^k_{base}}f_{\theta_f}(x),\vec{p}^{real}_k\in \R^{1\times s} pkreal=∣Dbasek∣1(x,y)∈Dbasek∑fθf(x),pkreal∈R1×s其中 ∣ D b a s e k ∣ |D^k_{base}| ∣Dbasek∣表示第 k k k个类别下训练图像样本的数量。
对于WordNet提取出的属性词条 a i a_i ai,可以想到这些属性词条也同样属于一些新类别,例如将马作为基础类别,斑马作为新类别,则马的属性词条之一“四条腿”也是斑马的属性词条,即这些属性词条将基础类别和新类别联系了起来。对于第 i i i个属性词条 a i a_i ai,找到其所属的所有基础类别,例如对于“四条腿”这一属性词条,马、斑马、大象等类别都具有四条腿,即都含有“四条腿”这一属性词条,然后找出这些类别所包含的所有训练图像样本 x ∈ D b a s e a i x\in D_{base}^{a_i} x∈Dbaseai。
接下来计算所有属性词条 a i a_i ai的特征向量 z ⃗ a i \vec{z}_{a_i} zai(即下图中的Part/Attribute Features)。首先,计算集合 D b a s e a i D_{base}^{a_i} Dbaseai中所有图像样本的均值特征向量 μ ⃗ a i \vec{\mu}_{a_i} μai和标准差向量 σ ⃗ a i \vec{\sigma}_{a_i} σai,即 μ ⃗ a i = 1 ∣ D b a s e a i ∣ ∑ ( x , y ) ∈ D b a s e a i f θ f ( x ) , μ ⃗ a i ∈ R 1 × s \vec{\mu}_{a_i}=\frac{1}{|D^{a_i}_{base}|}\sum_{(x,y)\in D^{a_i}_{base}}f_{\theta_f}(x),\vec{\mu}_{a_i}\in \R^{1\times s} μai=∣Dbaseai∣1(x,y)∈Dbaseai∑fθf(x),μai∈R1×s σ ⃗ a i = 1 ∣ D b a s e a i ∣ ∑ ( x , y ) ∈ D b a s e a i ( f θ f ( x ) − μ ⃗ a i ) 2 , σ ⃗ a i ∈ R 1 × s \vec{\sigma}_{a_i}=\sqrt{\frac{1}{|D^{a_i}_{base}|}\sum_{(x,y)\in D^{a_i}_{base}}{(f_{\theta_f}(x)-\vec{\mu}_{a_i})}^2},\vec{\sigma}_{a_i}\in \R^{1\times s} σai=∣Dbaseai∣1(x,y)∈Dbaseai∑(fθf(x)−μai)2,σai∈R1×s i = 1 , 2 , . . . , F i=1,2,...,F i=1,2,...,F其中 ∣ D b a s e a i ∣ |D^{a_i}_{base}| ∣Dbaseai∣表示 D b a s e a i D^{a_i}_{base} Dbaseai中样本的数量。其次,以均值特征向量 μ ⃗ a i \vec{\mu}_{a_i} μai和标准差向量 σ ⃗ a i \vec{\sigma}_{a_i} σai为参数,构造 s s s维正态分布 N ( μ ⃗ a i , σ ⃗ a i 2 ) N(\vec{\mu}_{a_i},\vec{\sigma}_{a_i}^2) N(μai,σai2)(即下图中不同颜色的椭圆形区域。为何使用椭圆形?因为高维正态分布概率密度函数在二维平面上的投影是一个椭圆),从该分布中随机取值,作为属性词条 a i a_i ai的特征向量,即 z ⃗ a i = μ ⃗ a i + σ ⃗ a i ϵ ⃗ , z ⃗ a i ∈ R 1 × s \vec{z}_{a_i}=\vec{\mu}_{a_i}+\vec{\sigma}_{a_i}\vec{\epsilon},\vec{z}_{a_i} \in\R^{1\times s} zai=μai+σaiϵ,zai∈R1×s ϵ ⃗ \vec{\epsilon} ϵ从 s s s维标准正态分布中随机取样, ϵ ⃗ ∈ R 1 × s \vec{\epsilon}\in \R^{1\times s} ϵ∈R1×s。令 Z Z Z表示所有 z ⃗ a i \vec{z}_{a_i} zai的集合,有 Z = { z ⃗ a i ∣ a i ∈ A } Z=\{\vec{z}_{a_i}|a_i\in A\} Z={zai∣ai∈A}
-
Step 3
通过Step 1和Step 2,得到了基础类别 c k c_k ck的原型 p ⃗ k r e a l \vec{p}_k^{real} pkreal和属性词条 a i a_i ai的特征向量 z ⃗ a i \vec{z}_{a_i} zai,在这一步中,需要通过原型补全网络(ProtoComNet) f θ c f_{\theta_c} fθc,将集合 R R R、集合 H H H、集合 Z Z Z和基础类别 c k c_k ck的原型 p k r e a l p_k^{real} pkreal作为输入,输出基础类别 c k c_k ck补全后的原型 p ^ k \hat p_k p^k。具体做法如下:
编码器(Encoder)
此步需要训练一个输出通道减半的全连接层加ReLU激活函数作为编码器 g θ e g_{\theta_e} gθe,即self.encoder = nn.Sequential( nn.Linear(in_features=s, out_features=s//2), nn.ReLU(inplace=True), )在基础类别数据集 D b a s e D_{base} Dbase中随机选择一个训练图像样本 x x x,得到 x x x的标签 y y y,输入预训练阶段训练好的特征提取器 f θ f f_{\theta_{f}} fθf,即 f ⃗ x = f θ f ( x ) \vec{f}_x=f_{\theta_f}(x) fx=fθf(x),得到 x x x的特征向量 f ⃗ x ∈ R 1 × s \vec{f}_x\in \R^{1\times s} fx∈R1×s。对 f ⃗ x = ( f 1 , f 2 , . . . , f s ) \vec{f}_x=(f_1,f_2,...,f_s) fx=(f1,f2,...,fs)进行线性变换并非线性激活,得到 f ⃗ x \vec{f}_x fx的隐编码 b ⃗ x = ( b 1 , b 2 , . . . , b s / 2 ) \vec{b}_x=(b_1,b_2,...,b_{s/2}) bx=(b1,b2,...,bs/2),即 b j = ∑ i = 1 s β i j f i + γ j b_j=\sum^s_{i=1} \beta_{ij}f_i+\gamma_j bj=i=1∑sβijfi+γj ReLU激活: b j = max ( 0 , b j ) \text{ReLU激活:}b_j=\text{max}(0,b_j) ReLU激活:bj=max(0,bj) j = 1 , 2 , . . . , s 2 j=1,2,...,\frac{s}{2} j=1,2,...,2s同样,输入属性词条 a i a_i ai的特征向量 z ⃗ a i = ( z 1 , z 2 , . . . , z s ) \vec{z}_{a_i}=(z_1,z_2,...,z_s) zai=(z1,z2,...,zs),替换上述式子的 f i f_i fi,计算得到属性词条 a i a_i ai特征向量 z ⃗ a i \vec{z}_{a_i} zai的隐编码向量 c ⃗ a i ∈ R 1 × s 2 \vec{c}_{a_i}\in \R^{1\times \frac{s}{2}} cai∈R1×2s
聚合器(Aggregator)
不同的属性词条对同一类别具有不同影响,例如属性词条“鼻子”对于“大象”这一类别比“老虎”更有代表性,因此需要构造一种注意力机制达到属性加权目的,此步需要训练一个双层全连接网络作为聚合器 g θ a g_{\theta_a} gθa,即self.aggregator = nn.Sequential( nn.Linear(in_features=d+d+s, out_features=d), nn.ReLU(inplace=True), nn.Linear(in_features=d, out_features=1)首先,将训练图像样本 x x x的标签 y y y对应的类别词嵌入向量 h ⃗ y ∈ R 1 × d \vec{h}_y\in \R^{1\times d} hy∈R1×d、词条 w m ∈ W w_m\in W wm∈W( m = 1 , 2 , . . . , K + F m=1,2,...,K+F m=1,2,...,K+F)的词嵌入向量 h ⃗ m ∈ R 1 × d \vec{h}_{m}\in \R^{1\times d} hm∈R1×d和 x x x经过特征提取器 f θ f f_{\theta_{f}} fθf得到的特征向量 f ⃗ x ∈ R 1 × s \vec{f}_x\in \R^{1\times s} fx∈R1×s连接,得到 [ h ⃗ y ∣ ∣ h ⃗ m ∣ ∣ f ⃗ x ] ∈ R 1 × ( d + d + s ) [\vec{h}_y||\vec{h}_{m}||\vec{f}_x]\in \R^{1\times (d+d+s)} [hy∣∣hm∣∣fx]∈R1×(d+d+s),对 [ h ⃗ y ∣ ∣ h ⃗ m ∣ ∣ f ⃗ x ] [\vec{h}_y||\vec{h}_{m}||\vec{f}_x] [hy∣∣hm∣∣fx]经过上述全连接层,得到隐编码向量 c ⃗ x = ( c 1 , c 2 , . . . , c K + F ) \vec{c}_x=(c_1,c_2,...,c_{K+F}) cx=(c1,c2,...,cK+F),即 t j m = ∑ i = 1 d + d + s δ i j [ h ⃗ y ∣ ∣ h ⃗ m ∣ ∣ f ⃗ x ] i + ζ j , j = 1 , 2 , . . . , d t_{jm}=\sum_{i=1}^{d+d+s}\delta_{ij}[\vec{h}_y||\vec{h}_{m}||\vec{f}_x]_i+\zeta_j,\quad j=1,2,...,d tjm=i=1∑d+d+sδij[hy∣∣hm∣∣fx]i+ζj,j=1,2,...,d t j m = max ( 0 , t j m ) , j = 1 , 2 , . . . , d t_{jm}=\text{max}(0,t_{jm}),\quad j=1,2,...,d tjm=max(0,tjm),j=1,2,...,d c m = ∑ j = 1 d η j t j m + θ c_m=\sum_{j=1}^d\eta_{j}t_{jm}+\theta cm=j=1∑dηjtjm+θ m = 1 , 2 , . . . , K + F m=1,2,...,K+F m=1,2,...,K+F其次,将隐编码向量 c x ⃗ ∈ R 1 × ( K + F ) \vec{c_x}\in \R^{1\times (K+F)} cx∈R1×(K+F)与表示标签 y y y对应类别 c y c_y cy对所有词条关系的向量 r ⃗ y = ( r 1 , r 2 , . . . , r K + F ) \vec{r}_y=(r_1,r_2,...,r_{K+F}) ry=(r1,r2,...,rK+F)逐元素相乘,即 α ⃗ = c ⃗ x ⋅ r ⃗ y , α ⃗ ∈ R 1 × ( K + F ) , m = 1 , 2 , . . . , K + F \vec{\alpha}=\vec{c}_x\cdot \vec{r}_y,\vec{\alpha}\in \R^{1\times (K+F)},m=1,2,...,K+F α=cx⋅ry,α∈R1×(K+F),m=1,2,...,K+F得到输入 x x x时,所有词条的注意力权重 α ⃗ \vec{\alpha} α。最后,将注意力权重 α ⃗ = ( α 1 , α 2 , . . . , α K + F ) \vec{\alpha}=(\alpha_1,\alpha_2,...,\alpha_{K+F}) α=(α1,α2,...,αK+F)、 x x x的特征向量 f x ⃗ \vec{f_x} fx经过编码器得到的隐编码向量 b ⃗ x = ( b 1 , b 2 , . . . , b s 2 ) \vec{b}_x=(b_1,b_2,...,b_{\frac{s}{2}}) bx=(b1,b2,...,b2s)、集合 Z Z Z中所有属性词条特征向量 z ⃗ a i \vec{z}_{a_i} zai的隐编码向量 c ⃗ i = ( c i 1 , c i 2 , . . . , c i s 2 ) \vec{c}_i=(c_{i1},c_{i2},...,c_{i\frac{s}{2}}) ci=(ci1,ci2,...,ci2s)相乘求和,得到聚合结果 g ⃗ = ( g 1 , g 2 , . . . , g s 2 ) \vec{g}=(g_1,g_2,...,g_\frac{s}{2}) g=(g1,g2,...,g2s),即 g n = α y b n + ∑ i = 1 F α K + i c i n , n = 1 , 2 , . . . , s 2 g_n=\alpha_yb_n+\sum_{i=1}^{F}\alpha_{K+i}c_{in},\quad n=1,2,...,\frac{s}{2} gn=αybn+i=1∑FαK+icin,n=1,2,...,2s其中,在注意力权重向量 α ⃗ \vec{\alpha} α中,由于存在 K K K个基础类别,所以前 K K K个注意力权重 α 1 , α 2 , . . . , α K \alpha_1,\alpha_2,...,\alpha_K α1,α2,...,αK是基础类别的注意力权重,后 F F F个注意力权重 α K + 1 , α K + 2 , . . . , α K + F \alpha_{K+1},\alpha_{K+2},...,\alpha_{K+F} αK+1,αK+2,...,αK+F是 F F F个属性词条的注意力权重。
解码器(Decoder)
解码器 g θ d g_{\theta d} gθd的作用比较简单,只是把向量的维度从 s / 2 s/2 s/2恢复到 s s s,即self.decoder = nn.Sequential( nn.Linear(in_features=s//2, out_features=512), nn.ReLU(inplace=True), nn.Linear(in_features=512, out_features=s)具体公式在此省略,最终得到 x x x的标签 y y y对应的补全原型 p ^ y ∈ R 1 × s \hat{p}_y\in \R^{1\times s} p^y∈R1×s。注意,在训练原型补全网络过程中,输入一个训练图像样本 x x x,输出一个 x x x的标签 y y y的补全原型,即在同一基础类别 c y c_y cy中,不同训练图像样本输出的补全原型 p ^ y \hat{p}_y p^y不同。
训练原型补全网络
计算Step 2计算得到的基础类别 c y c_y cy的原始原型 p ⃗ y r e a l = ( p 1 r e a l , p 2 r e a l , . . . , p s r e a l ) \vec{p}_y^{real}=(p^{real}_1,p^{real}_2,...,p^{real}_s) pyreal=(p1real,p2real,...,psreal)和基础类别 c y c_y cy的补全原型 p ^ y = ( p 1 , p 2 , . . . , p s ) \hat{p}_y=(p_1,p_2,...,p_s) p^y=(p1,p2,...,ps)之间的均方差损失 E E E,即 E = 1 s ∑ i = 1 s ( p i − p i r e a l ) 2 E=\frac{1}{s}\sum_{i=1}^s(p_i-p^{real}_i)^2 E=s1i=1∑s(pi−pireal)2通过梯度下降方法,以合适的学习率,在降低均方差损失(MSE Loss) E E E的过程中,训练编码器 g θ e g_{\theta_e} gθe、聚合器 g θ a g_{\theta_a} gθa、解码器 g θ d g_{\theta_d} gθd网络的参数和偏置。

3. 元训练(Meta-Training)
在这一阶段,进行N-way K-shot训练。从基础类别数据集
D
b
a
s
e
D_{base}
Dbase中随机取出
N
N
N个类别,在这
N
N
N个类别中,从每个类别中取出
K
K
K张训练样本图像
x
s
u
p
p
o
r
t
x_{support}
xsupport和对应标签
y
s
u
p
p
o
r
t
y_{support}
ysupport构成支持集
D
s
u
p
p
o
r
t
D_{support}
Dsupport,
(
x
s
u
p
p
o
r
t
,
y
s
u
p
p
o
r
t
)
∈
D
s
u
p
p
o
r
t
(x_{support},y_{support})\in D_{support}
(xsupport,ysupport)∈Dsupport,
M
M
M张训练样本图像
x
q
u
e
r
y
x_{query}
xquery和对应标签
y
q
u
e
r
y
y_{query}
yquery构成查询集,
(
x
q
u
e
r
y
,
y
q
u
e
r
y
)
∈
D
q
u
e
r
y
(x_{query},y_{query})\in D_{query}
(xquery,yquery)∈Dquery,其中
M
M
M>
N
N
N,
D
s
u
p
p
o
r
t
∪
D
q
u
e
r
y
D_{support}\cup D_{query}
Dsupport∪Dquery构成一个训练episode。
对于一个训练episode:
首先,将其中的每一张支持集图像
x
s
u
p
p
o
r
t
x_{support}
xsupport经特征提取器
f
θ
f
f_{\theta_f}
fθf、编码器
g
θ
e
g_{\theta_e}
gθe、聚合器
g
θ
a
g_{\theta_a}
gθa和解码器
g
θ
d
g_{\theta_d}
gθd,计算得到
x
s
u
p
p
o
r
t
x_{support}
xsupport所属第
y
s
u
p
p
o
r
t
y_{support}
ysupport个类别的补全原型
p
^
y
s
u
p
p
o
r
t
\hat p_{y_{support}}
p^ysupport。
其次,计算每一个
y
s
u
p
p
o
r
t
y_{support}
ysupport下所有支持集图像
x
s
u
p
p
o
r
t
x_{support}
xsupport经特征提取器
f
θ
f
f_{\theta_f}
fθf计算得到的特征向量的均值,作为第
y
s
u
p
p
o
r
t
y_{support}
ysupport个类别的原始原型
p
y
s
u
p
p
o
r
t
p_{y_{support}}
pysupport。
取出一张查询集图像
x
q
u
e
r
y
x_{query}
xquery,















 5270
5270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









