






1.
- EM blog的举例就是group 然后就是每个group的function很有效地串联所学的知识,看到的论文,所有的思考,都是有一定的逻辑关系,如何逐渐develop你的想法,都是有一定的源头,注意体会。
- 以前上课的时候,没有把握EM算法的思想,现在重新看文章,发现自己上课的效率确实有问题,一定要引起注意,以后上课注意有效地把握知识,进行对饮的吸收,并且进一步进行积累
- 不要被洗脑,要发展自己的思考这点才是最重要的,注意进行对应的额体会,要怀疑,批判,找到这个模型的缺陷。-----------就像authority /hub那篇文章一样,肯定存在有缺陷,这些都是需要进行分析讨论的。
- 提出EM算法的时候,自己需要思考这个方法是否真的有效,是否具备充分的理论保证,会收敛吗,这些的成立条件是否有效,都是自己需要思考的焦点。
- 收敛的理论保证,非常的重要。
- 这只是jesen不等式的特例,因为期望是随机变量在测度空间上求积分,所以jesen不等式带来了期望上的不等式的成立。
- :EM算法做的是参数的点估计 假设参数是未知常数,Gibbs采样则是估计参数的后验概率分布 假设参数是满足一定先验概率的随机变量 通过估计参数后验再求参数的期望来间接求解参数 避免学习参数出现置信误差(过拟合)
- 我理解的EM算法是最大似然估计方法--参数估计方法的一种 为什么要引入EM呢 我觉得 因为参数theta本身是依赖于数据的完整特征 但是只观察了部分特征X 因此需要引入隐藏特征Z 才能建立起theta与X,Z的关系。。。
怎么开始这个过程呢?我们现在自己的脑袋里假设存在一个theta(当然我们未知) 利用这个theta对数据进行了采样 由于每个数据的X特征已知 只须采样每个样本的Z特征 (这是一次实验) 利用实验观察的数据(X,Z)来修正我们对theta的理解,即使最大化似然函数的theta值作为新值;然后利用新的theta来做下一次实验 再利用新的数据修正我们对当前theta的理解 。不断重复上述过程 直到现实的观察与我们对世界的理解基本吻合 就停止实验。
至于EM算法为什么容易陷入局部最优解 要采取多次随机初始化呢?我认为 每个人对世界的认识都有限 只能根据自己的经验去判断 与外界缺乏联系 因此 只能做到自己认为的最好---------------看看别人是如何将知识串在一起的,这点要学习,学习一个模型知识,在于对应的融合,而不仅仅是知道这个层次,还要快速地进行积累。
还有一部分Jeery bird 的reference article没有读注意,关于k-means, 混合高斯模型,
后面补上。
1. 实际上k means又何尝不是一种em方法,不断地进行估计,相互迭代,知识进行相互融合,串起来,这样,更好地方便自己的理解运用分析,非常的重要,注意体会。
zouxy09的专栏
悲喜枯荣如是本无分别,当来则来,当去则去,随心,随性,随缘!-zouxy09@qq.com
 目录视图
目录视图 摘要视图
摘要视图 订阅
订阅版权声明:本文为博主原创文章,未经博主允许不得转载。
从最大似然到EM算法浅解
机器学习十大算法之一:EM算法。能评得上十大之一,让人听起来觉得挺NB的。什么是NB啊,我们一般说某个人很NB,是因为他能解决一些别人解决不了的问题。神为什么是神,因为神能做很多人做不了的事。那么EM算法能解决什么问题呢?或者说EM算法是因为什么而来到这个世界上,还吸引了那么多世人的目光。
我希望自己能通俗地把它理解或者说明白,但是,EM这个问题感觉真的不太好用通俗的语言去说明白,因为它很简单,又很复杂。简单在于它的思想,简单在于其仅包含了两个步骤就能完成强大的功能,复杂在于它的数学推理涉及到比较繁杂的概率公式等。如果只讲简单的,就丢失了EM算法的精髓,如果只讲数学推理,又过于枯燥和生涩,但另一方面,想把两者结合起来也不是件容易的事。所以,我也没法期待我能把它讲得怎样。希望各位不吝指导。
一、最大似然
扯了太多,得入正题了。假设我们遇到的是下面这样的问题:
假设我们需要调查我们学校的男生和女生的身高分布。你怎么做啊?你说那么多人不可能一个一个去问吧,肯定是抽样了。假设你在校园里随便地活捉了100个男生和100个女生。他们共200个人(也就是200个身高的样本数据,为了方便表示,下面,我说“人”的意思就是对应的身高)都在教室里面了。那下一步怎么办啊?你开始喊:“男的左边,女的右边,其他的站中间!”。然后你就先统计抽样得到的100个男生的身高。假设他们的身高是服从高斯分布的。但是这个分布的均值u和方差∂2我们不知道,这两个参数就是我们要估计的。记作θ=[u, ∂]T。
用数学的语言来说就是:在学校那么多男生(身高)中,我们独立地按照概率密度p(x|θ)抽取100了个(身高),组成样本集X,我们想通过样本集X来估计出未知参数θ。这里概率密度p(x|θ)我们知道了是高斯分布N(u,∂)的形式,其中的未知参数是θ=[u, ∂]T。抽到的样本集是X={x1,x2,…,xN},其中xi表示抽到的第i个人的身高,这里N就是100,表示抽到的样本个数。
由于每个样本都是独立地从p(x|θ)中抽取的,换句话说这100个男生中的任何一个,都是我随便捉的,从我的角度来看这些男生之间是没有关系的。那么,我从学校那么多男生中为什么就恰好抽到了这100个人呢?抽到这100个人的概率是多少呢?因为这些男生(的身高)是服从同一个高斯分布p(x|θ)的。那么我抽到男生A(的身高)的概率是p(xA|θ),抽到男生B的概率是p(xB|θ),那因为他们是独立的,所以很明显,我同时抽到男生A和男生B的概率是p(xA|θ)* p(xB|θ),同理,我同时抽到这100个男生的概率就是他们各自概率的乘积了。用数学家的口吻说就是从分布是p(x|θ)的总体样本中抽取到这100个样本的概率,也就是样本集X中各个样本的联合概率,用下式表示:

这个概率反映了,在概率密度函数的参数是θ时,得到X这组样本的概率。因为这里X是已知的,也就是说我抽取到的这100个人的身高可以测出来,也就是已知的了。而θ是未知了,则上面这个公式只有θ是未知数,所以它是θ的函数。这个函数放映的是在不同的参数θ取值下,取得当前这个样本集的可能性,因此称为参数θ相对于样本集X的似然函数(likehood function)。记为L(θ)。
这里出现了一个概念,似然函数。还记得我们的目标吗?我们需要在已经抽到这一组样本X的条件下,估计参数θ的值。怎么估计呢?似然函数有啥用呢?那咱们先来了解下似然的概念。
直接举个例子:
某位同学与一位猎人一起外出打猎,一只野兔从前方窜过。只听一声枪响,野兔应声到下,如果要你推测,这一发命中的子弹是谁打的?你就会想,只发一枪便打中,由于猎人命中的概率一般大于这位同学命中的概率,看来这一枪是猎人射中的。
这个例子所作的推断就体现了极大似然法的基本思想。
再例如:下课了,一群男女同学分别去厕所了。然后,你闲着无聊,想知道课间是男生上厕所的人多还是女生上厕所的人比较多,然后你就跑去蹲在男厕和女厕的门口。蹲了五分钟,突然一个美女走出来,你狂喜,跑过来告诉我,课间女生上厕所的人比较多,你要不相信你可以进去数数。呵呵,我才没那么蠢跑进去数呢,到时还不得上头条。我问你是怎么知道的。你说:“5分钟了,出来的是女生,女生啊,那么女生出来的概率肯定是最大的了,或者说比男生要大,那么女厕所的人肯定比男厕所的人多”。看到了没,你已经运用最大似然估计了。你通过观察到女生先出来,那么什么情况下,女生会先出来呢?肯定是女生出来的概率最大的时候了,那什么时候女生出来的概率最大啊,那肯定是女厕所比男厕所多人的时候了,这个就是你估计到的参数了。
从上面这两个例子,你得到了什么结论?
回到男生身高那个例子。在学校那么男生中,我一抽就抽到这100个男生(表示身高),而不是其他人,那是不是表示在整个学校中,这100个人(的身高)出现的概率最大啊。那么这个概率怎么表示?哦,就是上面那个似然函数L(θ)。所以,我们就只需要找到一个参数θ,其对应的似然函数L(θ)最大,也就是说抽到这100个男生(的身高)概率最大。这个叫做θ的最大似然估计量,记为:

有时,可以看到L(θ)是连乘的,所以为了便于分析,还可以定义对数似然函数,将其变成连加的:

好了,现在我们知道了,要求θ,只需要使θ的似然函数L(θ)极大化,然后极大值对应的θ就是我们的估计。这里就回到了求最值的问题了。怎么求一个函数的最值?当然是求导,然后让导数为0,那么解这个方程得到的θ就是了(当然,前提是函数L(θ)连续可微)。那如果θ是包含多个参数的向量那怎么处理啊?当然是求L(θ)对所有参数的偏导数,也就是梯度了,那么n个未知的参数,就有n个方程,方程组的解就是似然函数的极值点了,当然就得到这n个参数了。
最大似然估计你可以把它看作是一个反推。多数情况下我们是根据已知条件来推算结果,而最大似然估计是已经知道了结果,然后寻求使该结果出现的可能性最大的条件,以此作为估计值。比如,如果其他条件一定的话,抽烟者发生肺癌的危险时不抽烟者的5倍,那么如果现在我已经知道有个人是肺癌,我想问你这个人抽烟还是不抽烟。你怎么判断?你可能对这个人一无所知,你所知道的只有一件事,那就是抽烟更容易发生肺癌,那么你会猜测这个人不抽烟吗?我相信你更有可能会说,这个人抽烟。为什么?这就是“最大可能”,我只能说他“最有可能”是抽烟的,“他是抽烟的”这一估计值才是“最有可能”得到“肺癌”这样的结果。这就是最大似然估计。
好了,极大似然估计就讲到这,总结一下:
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
求最大似然函数估计值的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数,令导数为0,得到似然方程;
(4)解似然方程,得到的参数即为所求;
二、EM算法
好了,重新回到上面那个身高分布估计的问题。现在,通过抽取得到的那100个男生的身高和已知的其身高服从高斯分布,我们通过最大化其似然函数,就可以得到了对应高斯分布的参数θ=[u, ∂]T了。那么,对于我们学校的女生的身高分布也可以用同样的方法得到了。
再回到例子本身,如果没有“男的左边,女的右边,其他的站中间!”这个步骤,或者说我抽到这200个人中,某些男生和某些女生一见钟情,已经好上了,纠缠起来了。咱们也不想那么残忍,硬把他们拉扯开。那现在这200个人已经混到一起了,这时候,你从这200个人(的身高)里面随便给我指一个人(的身高),我都无法确定这个人(的身高)是男生(的身高)还是女生(的身高)。也就是说你不知道抽取的那200个人里面的每一个人到底是从男生的那个身高分布里面抽取的,还是女生的那个身高分布抽取的。用数学的语言就是,抽取得到的每个样本都不知道是从哪个分布抽取的。
这个时候,对于每一个样本或者你抽取到的人,就有两个东西需要猜测或者估计的
只有当我们知道了哪些人属于同一个高斯分布的时候,我们才能够对这个分布的参数作出靠谱的预测,例如刚开始的最大似然所说的,但现在两种高斯分布的人混在一块了,我们又不知道哪些人属于第一个高斯分布,哪些属于第二个,所以就没法估计这两个分布的参数。反过来,只有当我们对这两个分布的参数作出了准确的估计的时候,才能知道到底哪些人属于第一个分布,那些人属于第二个分布。
这就成了一个先有鸡还是先有蛋的问题了。鸡说,没有我,谁把你生出来的啊。蛋不服,说,没有我,你从哪蹦出来啊。(呵呵,这是一个哲学问题。当然了,后来科学家说先有蛋,因为鸡蛋是鸟蛋进化的)。为了解决这个你依赖我,我依赖你的循环依赖问题,总得有一方要先打破僵局,说,不管了,我先随便整一个值出来,看你怎么变,然后我再根据你的变化调整我的变化,然后如此迭代着不断互相推导,最终就会收敛到一个解。这就是EM算法的基本思想了。
不知道大家能否理解其中的思想,我再来啰嗦一下。其实这个思想无处在不啊。
例如,小时候,老妈给一大袋糖果给你,叫你和你姐姐等分,然后你懒得去点糖果的个数,所以你也就不知道每个人到底该分多少个。咱们一般怎么做呢?先把一袋糖果目测的分为两袋,然后把两袋糖果拿在左右手,看哪个重,如果右手重,那很明显右手这代糖果多了,然后你再在右手这袋糖果中抓一把放到左手这袋,然后再感受下哪个重,然后再从重的那袋抓一小把放进轻的那一袋,继续下去,直到你感觉两袋糖果差不多相等了为止。呵呵,然后为了体现公平,你还让你姐姐先选了。
EM算法就是这样,假设我们想估计知道A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM的意思是“Expectation Maximization
这里把每个人(样本)的完整描述看做是三元组yi={xi,zi1,zi2},其中,xi是第i个样本的观测值,也就是对应的这个人的身高,是可以观测到的值。zi1和zi2表示男生和女生这两个高斯分布中哪个被用来产生值xi,就是说这两个值标记这个人到底是男生还是女生(的身高分布产生的)。这两个值我们是不知道的,是隐含变量。确切的说,zij在xi由第j个高斯分布产生时值为1,否则为0。例如一个样本的观测值为1.8,然后他来自男生的那个高斯分布,那么我们可以将这个样本表示为{1.8, 1, 0}。如果zi1和zi2的值已知,也就是说每个人我已经标记为男生或者女生了,那么我们就可以利用上面说的最大似然算法来估计他们各自高斯分布的参数。但是它们未知,因此我们只能用EM算法。
咱们现在不是因为那个恶心的隐含变量(抽取得到的每个样本都不知道是从哪个分布抽取的)使得本来简单的可以求解的问题变复杂了,求解不了吗。那怎么办呢?人类解决问题的思路都是想能否把复杂的问题简单化。好,那么现在把这个复杂的问题逆回来,我假设已经知道这个隐含变量了,哎,那么求解那个分布的参数是不是很容易了,直接按上面说的最大似然估计就好了。那你就问我了,这个隐含变量是未知的,你怎么就来一个假设说已知呢?你这种假设是没有根据的。呵呵,我知道,所以我们可以先给这个给分布弄一个初始值,然后求这个隐含变量的期望,当成是这个隐含变量的已知值,那么现在就可以用最大似然求解那个分布的参数了吧,那假设这个参数比之前的那个随机的参数要好,它更能表达真实的分布,那么我们再通过这个参数确定的分布去求这个隐含变量的期望,然后再最大化,得到另一个更优的参数,……迭代,就能得到一个皆大欢喜的结果了。
这时候你就不服了,说你老迭代迭代的,你咋知道新的参数的估计就比原来的好啊?为什么这种方法行得通呢?有没有失效的时候呢?什么时候失效呢?
三、EM算法推导
假设我们有一个样本集{x(1),…,x(m)},包含m个独立的样本。但每个样本i对应的类别z(i)是未知的(相当于聚类),也即隐含变量。故我们需要估计概率模型p(x,z)的参数θ,但是由于里面包含隐含变量z,所以很难用最大似然求解,但如果z知道了,那我们就很容易求解了。
对于参数估计,我们本质上还是想获得一个使似然函数最大化的那个参数θ,现在与最大似然不同的只是似然函数式中多了一个未知的变量z,见下式(1)。也就是说我们的目标是找到适合的θ和z让L(θ)最大。那我们也许会想,你就是多了一个未知的变量而已啊,我也可以分别对未知的θ和z分别求偏导,再令其等于0,求解出来不也一样吗?

本质上我们是需要最大化(1)式(对(1)式,我们回忆下联合概率密度下某个变量的边缘概率密度函数的求解,注意这里z也是随机变量。对每一个样本i的所有可能类别z求等式右边的联合概率密度函数和,也就得到等式左边为随机变量x的边缘概率密度),也就是似然函数,但是可以看到里面有“和的对数”,求导后形式会非常复杂(自己可以想象下log(f1(x)+ f2(x)+ f3(x)+…)复合函数的求导),所以很难求解得到未知参数z和θ。那OK,我们可否对(1)式做一些改变呢?我们看(2)式,(2)式只是分子分母同乘以一个相等的函数,还是有“和的对数”啊,还是求解不了,那为什么要这么做呢?咱们先不管,看(3)式,发现(3)式变成了“对数的和”,那这样求导就容易了。我们注意点,还发现等号变成了不等号,为什么能这么变呢?这就是Jensen不等式的大显神威的地方。
Jensen不等式:
设f是定义域为实数的函数,如果对于所有的实数x。如果对于所有的实数x,f(x)的二次导数大于等于0,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的,那么f是凸函数。如果只大于0,不等于0,那么称f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么:E[f(X)]>=f(E[X])
特别地,如果f是严格凸函数,当且仅当X是常量时,上式取等号。
如果用图表示会很清晰:

图中,实线f是凸函数,X是随机变量,有0.5的概率是a,有0.5的概率是b。(就像掷硬币一样)。X的期望值就是a和b的中值了,图中可以看到E[f(X)]>=f(E[X])成立。
当f是(严格)凹函数当且仅当-f是(严格)凸函数。
Jensen不等式应用于凹函数时,不等号方向反向。
回到公式(2),因为f(x)=log x为凹函数(其二次导数为-1/x2<0)。
(2)式中 的期望,(考虑到E(X)=∑x*p(x),f(X)是X的函数,则E(f(X))=∑f(x)*p(x)),又
的期望,(考虑到E(X)=∑x*p(x),f(X)是X的函数,则E(f(X))=∑f(x)*p(x)),又 ,所以就可以得到公式(3)的不等式了(若不明白,请拿起笔,呵呵):
,所以就可以得到公式(3)的不等式了(若不明白,请拿起笔,呵呵):

OK,到这里,现在式(3)就容易地求导了,但是式(2)和式(3)是不等号啊,式(2)的最大值不是式(3)的最大值啊,而我们想得到式(2)的最大值,那怎么办呢?
现在我们就需要一点想象力了,上面的式(2)和式(3)不等式可以写成:似然函数L(θ)>=J(z,Q),那么我们可以通过不断的最大化这个下界J,来使得L(θ)不断提高,最终达到它的最大值。
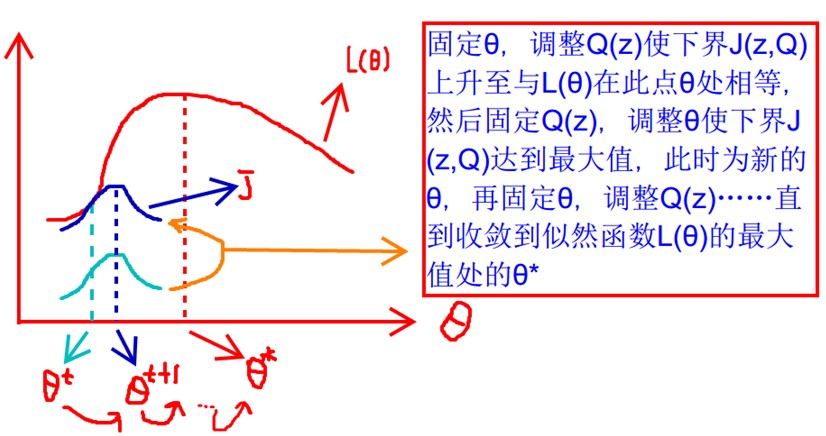
见上图,我们固定θ,调整Q(z)使下界J(z,Q)上升至与L(θ)在此点θ处相等(绿色曲线到蓝色曲线),然后固定Q(z),调整θ使下界J(z,Q)达到最大值(θt到θt+1),然后再固定θ,调整Q(z)……直到收敛到似然函数L(θ)的最大值处的θ*。这里有两个问题:什么时候下界J(z,Q)与L(θ)在此点θ处相等?为什么一定会收敛?
首先第一个问题,在Jensen不等式中说到,当自变量X是常数的时候,等式成立。而在这里,即:

再推导下,由于 (因为Q是随机变量z(i)的概率密度函数),则可以得到:分子的和等于c(分子分母都对所有z(i)求和:多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),则:
(因为Q是随机变量z(i)的概率密度函数),则可以得到:分子的和等于c(分子分母都对所有z(i)求和:多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),则:

至此,我们推出了在固定参数θ后,使下界拉升的Q(z)的计算公式就是后验概率,解决了Q(z)如何选择的问题。这一步就是E步,建立L(θ)的下界。接下来的M步,就是在给定Q(z)后,调整θ,去极大化L(θ)的下界J(在固定Q(z)后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
EM算法(Expectation-maximization):
期望最大算法是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。
EM的算法流程:
初始化分布参数θ;
重复以下步骤直到收敛:
E步骤:根据参数初始值或上一次迭代的模型参数来计算出隐性变量的后验概率,其实就是隐性变量的期望。作为隐藏变量的现估计值:

M步骤:将似然函数最大化以获得新的参数值:

这个不断的迭代,就可以得到使似然函数L(θ)最大化的参数θ了。那就得回答刚才的第二个问题了,它会收敛吗?
感性的说,因为下界不断提高,所以极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。理性分析的话,就会得到下面的东西:

具体如何证明的,看推导过程参考:Andrew Ng《The EM algorithm》
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
四、EM算法另一种理解
坐标上升法(Coordinate ascent):

图中的直线式迭代优化的路径,可以看到每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。
这犹如在x-y坐标系中找一个曲线的极值,然而曲线函数不能直接求导,因此什么梯度下降方法就不适用了。但固定一个变量后,另外一个可以通过求导得到,因此可以使用坐标上升法,一次固定一个变量,对另外的求极值,最后逐步逼近极值。对应到EM上,E步:固定θ,优化Q;M步:固定Q,优化θ;交替将极值推向最大。
五、EM的应用
EM算法有很多的应用,最广泛的就是GMM混合高斯模型、聚类、HMM等等。具体可以参考JerryLead的cnblog中的Machine Learning专栏:
混合高斯模型(Mixtures of Gaussians)和EM算法
K-means聚类算法
没有鸡和蛋的先后之争,因为他们都知道“没有你就没有我”。从此他们一起过上了幸福美好的生活。
-
顶
- 197
-
踩
- 6
参考知识库



-
猜你在找
-
132楼
Charlie818 2016-12-29 23:44发表
-

- 虽说例子有些琐碎,也有些冷,但能感觉到博主在努力举例子诠释这个概念,让我们明白,谢谢博主!
-
131楼
sinat_15560643巴黎圣日尔曼 2016-12-09 11:05发表
-

- 就是说EM算法每次迭代的时候都要更新核函数的参数,是吗?
-
130楼
番茄炒鸡蛋 2016-12-05 14:29发表
-

-
真啰嗦。。。唧唧歪歪步入正题。搞呢么多反问
-
Re:
神谷姬爱ML 昨天 14:17发表
-

- 回复qicongsheng:这位同学你连个毛线都写不出来你信不信
-
Re:
忆臻 2016-12-10 09:23发表
-

- 回复qicongsheng:这位同学你写一篇试试....不然就尊重人家的成果~
-
Re:
dalerkd 2016-12-08 11:28发表
-

- 感谢您对知识的分享!
-
-
129楼
caotuhao 2016-12-04 16:52发表
-

- 膜拜啊 感激大牛
-
128楼
Jetqvvf_what 2016-11-10 11:51发表
-

- 猎人打兔子的例子中,兔子被猎人打死了,如果不知道谁更准,那我猜猎人更准,应该这样是最大似然估计吧,貌似楼主说反了。
-
127楼
jpzhoucsdn 2016-11-04 10:14发表
-

- 不错,赞一个,如此深奥的道理,讲得通俗易懂,可见博主的功底真不一般。
-
126楼
mimicdj 2016-10-24 21:56发表
-

- 虽然有些笑话很冷,但是丝毫不减我看这篇文章的兴奋。赞!
-
125楼
lppl 2016-10-17 18:54发表
-

- 打滚膜拜大神,谢谢楼主
-
124楼
qq_36079872 2016-10-15 16:14发表
-

- 写的太好了,形象,看完了竟然没感觉枯燥。HIT学生前来学习
-
123楼
a649339266 2016-09-27 09:52发表
-

- 最后求出来的Theta是男生分布的还是女生分布的呢
-
122楼
哈士奇说喵 2016-09-23 15:07发表
-

- 能那么用心写博客的人真的很少了啊,必须赞一个
-
121楼
人工智能times 2016-09-21 18:11发表
-

-
例子讲的不错,推导思路不错。但是以我一个数学系的学生来说,推导步骤省略太多,跳跃太大,同时感觉凸函数那个地方不是很准确,谢谢
PS:其实最后证明只需要说明单调递增有上确界必收敛到上确界
-
120楼
tyf0425 2016-09-05 15:43发表
-

-
写得通俗易懂,看了好多博客,还是在这里看懂了,但是我感觉Jensen不等式那里的凹凸函数写反了,不知道是不是这样,还是我理解错了?
-
Re:
gladys132013 2016-09-18 22:05发表
-

-
回复tyf0425: 不是的, 国外的凸函数定义跟我们教材上的相反
-
Re:
tyf0425 2016-10-13 10:49发表
-
- 回复gladys132013:原来是这样 我知道了 谢谢你!
-
-
-
119楼
怠馬 2016-08-23 18:20发表
-

- 赞!
-
118楼
何小毛哒哒哒 2016-08-05 12:12发表
-

-
写的非常的好,第一次真正地把EM算法给弄懂了。谢谢你!
非常喜欢这种通俗但又恰到好处的解释。
-
117楼
ulando 2016-07-19 18:39发表
-

- 写的很好,赞,谢谢分享。
-
116楼
追寻灯火阑珊 2016-07-07 10:55发表
-

- mark
-
115楼
mengan1223334444 2016-06-17 11:49发表
-

-
上面的函数叫凹函数,不是凸函数。y''>0,凹函数,如y=x2,y''=2>0,凹函数。
如下面中:
设f是定义域为实数的函数,如果对于所有的实数x。如果对于所有的实数x,f(x)的二次导数大于等于0,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的,那么f是凸函数。如果只大于0,不等于0,那么称f是严格凸函数。
我没有理解错吧?-
Re:
qq_35552388 2016-07-08 19:05发表
-

- 回复mengan1223334444:。。。文中的凸函数是凸优化的那种凸函数,不是高数中的那个定义。。。
-
Re:
HDACMer 2016-07-07 10:24发表
-

- 回复mengan1223334444:so sad, you mixed concept of conVex and conCAVE.
-
-
114楼
夏驰Lock 2016-05-22 23:09发表
-

- E步骤中,为什么隐性变量的后验概率,就是隐性变量的期望?
-
113楼
ken_92 2016-05-16 15:34发表
-

- 写得太好了!在之前对EM的理解上更近了一步,谢谢楼主!
-
112楼
yexiadan276 2016-04-14 15:45发表
-

- 太赞了,多谢楼主
-
111楼
小米0921 2016-04-10 18:24发表
-

- f(x)=logx是凸函数还是凹函数啊?满足E[f(x)] >= f(E[x])吗?
-
110楼
秋光 2016-04-08 13:48发表
-

-
楼主,我想问一下EM算法步骤里边的那个期望怎么求?
p(z(i)|x(i); θ)这个怎么求呢?
-
109楼
FlytoYoung 2016-04-01 17:11发表
-

-
大神,在由公式(2)推导公式(3)的不等式时,是不是写反了?
根据Jensen不等式来讲:不应该是E[f(x)] >= f(E[x])吗?但文中似乎反了。。-
Re:
a649339266 2016-09-22 20:52发表
-
- 回复FlytoYoung:我因为这个错误。。。弄了一下午。。。智商掉一地啊
-
Re:
小米0921 2016-04-10 18:24发表
-
- 回复FlytoYoung:f(x)=logx是凸函数还是凹函数啊?满足E[f(x)] >= f(E[x])吗?
-
Re:
FlytoYoung 2016-04-01 17:23发表
-
- 回复FlytoYoung:额,刚发现,是凹函数。。。我去。。好吧。自己犯了低级错误
-
-
108楼
brave heart 2016-03-25 12:13发表
-

- 你的函数凹凸性是不是说反了啊?
-
107楼
csj1993 2016-03-21 16:40发表
-

- 麻烦问下楼主,还是不太懂hmm工具箱中em算法的主要目的是什么?
-
106楼
cothee 2016-03-14 13:59发表
-

-
您好,最近正在学习EM算法,看了您的博客,感觉很受启发。我有一个问题,就是关于Z右上角那个i和X右上角那个i并不是一回事,所以我觉得是不是改成j或换乘其他符号可以更好的区分一下呢?还请解惑……
-
Re:
lipeng19930407 2016-03-16 20:34发表
-

- 回复cothee:z和x的i是一回事,都表示第i个训练样本
-
-
105楼
Lvhhh 2016-03-06 08:41发表
-

- http://blog.csdn.net/lvhao92/article/details/50805021
-
104楼
cl11235813 2016-02-03 06:21发表
-

- 谢谢楼主,相当通俗易懂的解释!!!
-
103楼
xiangshoujiyi 2016-01-15 11:58发表
-

- 通俗易懂,非常不错!!!
-
102楼
missdan2015 2016-01-13 14:54发表
-

- 深入人心,受教了,尤其是那些生动的例子
-
101楼
小小程序猿_ 2016-01-11 20:30发表
-

-
但是我对Q(Z)这个函数的具体含义还是不太理解...写的都看明白了,但是感觉楼主还差一个具体是事列(在EM的最后),包括最后公司里面每一个函数的意义和用法的说明...
-
Re:
silly_fox 2016-03-08 00:12发表
-

- 回复tangbo713:我也不太懂,哥们弄懂了教教我,而且上面说是z的概率分布z的概率分布不是p(z)吗?
-
-
100楼
还有名字 2015-12-31 13:58发表
-

- 楼主写的大赞,对于刚开始学ML的我,对于依然忘记线性代数的我,读起来很容易理解,循循善诱!
-
99楼
一生所求bu 2015-12-27 16:01发表
-

- 思维清晰,内容详细丰富
-
98楼
Jorfun 2015-12-23 09:58发表
-

- 这几天看了不少资料,感觉博主的解释是最为详细的,把一些我不太明白的概念都串联了起来。非常谢谢您的分享~
-
97楼
呆维 2015-12-21 21:08发表
-

- 就要这样深入浅出的文章,顶
-
96楼
阿炜 2015-12-06 17:42发表
-

- 比较色的同志,看什么就是透!赞!
-
95楼
阿炜 2015-12-06 17:41发表
-
- 比较色的同志,看什么就是透!赞!
-
94楼
weixliui 2015-12-04 12:18发表
-

- lz文章写的很不错,最大似然估计这部分通俗易懂很快就了解了思想。关于EM已经很不错的,但是作为小白还是有些障碍,主要原因:1.EM算法其中Q(zi)函数一开始的引入并没有解释这个函数的意义,所以没有能够理解,直接解释其为zi的分布函数感觉会更容易理解。2.lz的那个手绘的优化图实在没有太理解,绿色和蓝色的均值怎么出现在同一条直线了...这里我硬生生理解优化下界可以提高最大值了。总而言之,楼主文章还是很赞。
-
93楼
weixliui 2015-12-04 11:30发表
-
-
lz文章写的很不错,最大似然估计这部分通俗易懂很快就了解了思想。关于EM已经很不错的,但是作为小白还是有些障碍,主要原因:1.EM算法其中Q(zi)函数一开始的引入并没有解释这个函数的意义,所以没有能够理解,直接解释其为zi的分布函数感觉会更容易理解。2.lz的那个手绘的优化图实在没有太理解,绿色和蓝色的均值怎么出现在同一条直线了...这里我硬生生理解优化下界可以提高最大值了。总而言之,楼主文章还是很赞。
-
Re:
silly_fox 2016-03-08 09:00发表
-
- 回复liu_xiao_wei:请问一下 你的意思是 Q(z)表示z的概率分布 ,那也就是Q(z)=P(z)?
-
-
92楼
Yetixie1994 2015-12-01 17:31发表
-

- 那第一次循环算E-step的时候,参数的值是带哪个?是带一个随机的参数;还是假设完Z,用M-step算出参数,再把参数值带入E-step呀?
-
91楼
professionall 2015-11-30 20:17发表
-

- 真不错
-
90楼
蔡叫兽 2015-11-17 09:51发表
-

-
写得真好,学习了
-
Re:
weixinyu127 2016-06-30 16:36发表
-

- 回复cpsinwhu:赫然见到蔡教授!
-
-
89楼
Z-Chris 2015-11-04 15:17发表
-

- 写的很好,但是有点小建议,博主把太多精力放在讲前面的基本概念上,导致读起来感觉头重脚轻的。应该将一部分精力放在基本概念上,然后把重点放在公式的讲解上。
-
88楼
multiangle 2015-11-02 13:51发表
-

- 通俗易懂,非常感谢~
-
87楼
Ffanfanm 2015-10-12 10:33发表
-

-
一个小小的建议。
样本是指研究中实际观测或调查的一部分个体,你博文中称“样本集”意思就有偏差了,成了很多个样例集的意思。建议博主把“样本集”改为“样例集”
-
86楼
enexygbz 2015-10-10 17:25发表
-

- 写的很好 谢谢
-
85楼
motoyule 2015-10-07 22:26发表
-

- 这是我见过最好的EM算法通俗解释了。但是凹凸性和jesen不等式这里稍有瑕疵。函数其实未必可导的也未必连续,但是jesen不等式仅仅和凹凸性有关,也就是说函数虽然不连续,jesen依旧成立,同时jesen不等式也不是这样的,这只是 jesen不等式的特例,因为期望是随机变量在测度空间上求积分,所以jesen不等式带来了期望上的不等式的成立。
-
84楼
296163849 2015-09-11 18:52发表
-

-
肺癌与烟民的例子有错误吧。考虑到人群中烟民的比例不大,概率上来看,应该猜不吸烟比较正确,但是我也不知道你错在哪里,为什么会得出这样的结论呢?
-
Re:
迷雾forest 2015-10-12 16:10发表
-

- 回复u011857056:作者依据的是,根据统计吸烟人群中得肺癌的比较多,而不是人群中吸烟的人数比较少。
-
-
83楼
chongchong24 2015-09-10 10:35发表
-

-
请问目前有没有什么好的策略能够避免EM算法陷入局部最优解
-
Re:
sinat_33931042 2016-02-04 22:46发表
-

- 回复chongchong24:有一个随机EM算法可以
-
-
82楼
xueditanglang1 2015-08-19 11:32发表
-

- 这篇看得最是明白了,感谢博主分享啊
-
81楼
xwzhong2016 2015-08-06 19:58发表
-

- 顶
-
80楼
qq_26966809 2015-07-18 09:33发表
-

- 说的太好了!!!看了半天没看懂的em终于明白了!
-
79楼
袁良锭 2015-07-16 11:20发表
-

- 公式全部不显示了呢。
-
78楼
dmkl123 2015-07-02 22:04发表
-

- 看了那么多,这篇是看得最懂的了!讲得太好了
-
77楼
zsfcg 2015-06-11 21:15发表
-

- 写得好!!!感谢,感谢你们这些默默耕耘的人!人类的知识因为你们而得以传播的更广,变得更完善!
-
76楼
925813290 2015-06-04 18:31发表
-

- 好棒
-
75楼
sinat_28503151 2015-05-26 17:11发表
-

- 求解释:为什么在E步骤里计算出的隐性变量的后验概率Q,“其实就是隐性变量的期望“?
-
74楼
lvchahp 2015-05-24 23:26发表
-

- 楼主你好~极大似然之所以是连乘是因为假设样本是独立同分布的,所以密度函数可以写成连乘的形式。看了博客受益匪浅,非常感谢!
-
73楼
拾毅者 2015-05-22 09:20发表
-

- 这个算法数学功底要好,可是感觉概率论这块没学好 都忘了
-
72楼
yanghuatang 2015-05-06 14:48发表
-

- 很不错!!关于poisson分布的最大似然估计,很多数据的怎么求?
-
71楼
hhran123 2015-05-02 17:28发表
-

- 楼主说的很好,情不自禁一路看完
-
70楼
zhuxianduowan 2015-04-23 09:51发表
-

- 已经被绕晕了
-
69楼
DqWong 2015-04-15 14:51发表
-

-
只有我一个人觉得废话连篇吗?看了半天一直没看到重点
-
Re:
qq_34531825 2016-09-23 22:32发表
-

- 回复u010381648:这篇文章写的非常好,例子看似很多但是都恰到好处
-
-
68楼
KlausQi 2015-04-14 08:40发表
-

- 深入浅出,例子很生动,支持楼主!!!
-
67楼
coolclient 2015-04-07 09:44发表
-

- 博主,深入浅出,例子举的非常的好!
-
66楼
_KDH 2015-04-05 21:56发表
-

- p(zi|xi;theta)怎么算
-
65楼
BARDDD 2015-03-25 16:03发表
-

- 写的很好,学习了!
-
64楼
Li_ableXiao 2015-03-25 13:42发表
-

- 博主碉堡了,讲解很精彩~~~
-
63楼
会敲键盘的猩猩 2015-03-17 14:54发表
-

- 博主讲解的很清晰易懂,非常感谢。
-
62楼
ld331239828 2015-03-13 20:40发表
-

- 膜拜,能否在深入浅出的讲解一下GMM
-
61楼
tianbwin2995 2015-02-03 12:45发表
-

- 楼主nb啊 说的深入浅出 希望多写一些供学弟们学习!
-
60楼
鼓Sk8er 2015-01-14 11:27发表
-

-
作者写的真好。我也看了你关于DeepLearning的文章。我正在理解RBM,你觉得RBM的优化原理(Gibbs Sampling)是不是就是这里的EM算法?
-
Re:
宇宙蛋 2015-05-28 20:34发表
-

- 回复zzz7290: EM算法做的是参数的点估计 假设参数是未 知常数,Gibbs采样则是估计参数的后验概率分布 假设参数是满足一定先验概率的随机变量 通过估计参数后验再求参数的期望来间接求解参数 避免学习参数出现置信误差(过拟合)
-
Re:
johnnyconstantine 2015-03-27 10:02发表
-

- 回复zzz7290:还真不是,EM算法的关键在于期望的最大化,而不是迭代调参的过程。吉布斯采样同样有迭代过程,但和EM还是两回事
-
-
59楼
wxklr 2015-01-08 16:08发表
-

- 精彩!总算明白什么是最大似然及为什么要引入那个隐变量了
-
58楼
houyue 2015-01-07 14:15发表
-

- 赞一下啦。
-
57楼
有梦的码农 2014-12-08 11:17发表
-

- 楼主nb啊,讲的通俗易懂,学习了
-
56楼
saldlFLSA 2014-12-02 17:08发表
-

- 弱弱的问一句,您博客中的图(数学符号、分布图等等)都是怎么做的?要写课程报告,不会作图-_-
-
55楼
linzhineng44 2014-11-22 23:41发表
-

- 非常赞,博主提到的问题,我都想过了。很好解决了问题!非常感谢,特别是举得例子!!!
-
54楼
我真的不是赵能飞 2014-11-22 19:47发表
-

- 拜读了 写的非常好 研一的飘过
-
53楼
曼陀罗彼岸花 2014-10-19 23:26发表
-

- 博主说的很明白,终于看懂了EM算法,而且还很深刻。厉害,赞一个!!
-
52楼
西电菜鸟 2014-10-19 21:05发表
-

- 太有用了,希望能发一篇变分贝叶斯的博客,最近在看这个
-
51楼
NgHingtim 2014-10-15 23:16发表
-

- 撸主的鸡与蛋举得例子很恰当,终于明白了EM算法怎么回事?
-
50楼
zwlh1990 2014-10-11 12:51发表
-

- 楼主真乃牛人,把深奥的道理用生动形象的语言表达了出来,讲得太好了,想必楼主对此已做了相当多的研究,看完真是很感动,比我们那老师上课BB叨了90分钟都管用,现在是真的明白了!感谢楼主!!!
-
49楼
xclovecx1314 2014-09-21 19:53发表
-

- 写的非常好,感谢楼主!
-
48楼
YXY_1989 2014-09-19 09:31发表
-

- 写的很好,很容易理解
-
47楼
MrsYoung 2014-09-15 10:40发表
-

- 看过了之后感觉很简单易懂,语言风趣幽默,但是同时也发现了自己的数学功底相当之薄弱。。
-
46楼
En_Dea_Vor 2014-09-05 21:09发表
-

- 顶一个~
-
45楼
洛萨之子 2014-09-01 18:12发表
-

-
回复yihualuomeng:国内的,尤其是同济的高等数学,凹凸性是相反的,而在经济学等领域,凹凸性与国外的相同,所以明白了吗
-
Re:
IT小飞飞 2014-09-03 11:04发表
-

- 回复hit_suit:嗯,后来知道了,所以就把评论删了。博主写得不错,继续加油哈
-
-
44楼
bee0308 2014-08-29 14:50发表
-

- 好好好好好好好~~~~~
-
43楼
迷雾forest 2014-08-27 21:02发表
-
- 这是我看过的EM算法讲的最清楚的地方,另外,EM算法可以被理解成为引入隐含变量(往往对应于丢失数据)的坐标上升法,不知道我这么理解对不对?
-
42楼
今夕望月 2014-08-12 14:08发表
-

- 先马之
-
41楼
xiaozixiaozhi 2014-08-06 19:20发表
-

-
先有鸟蛋还是先有鸟
-
Re:
JokerMi 2015-04-20 20:00发表
-

- 回复xiaozixiaozhi:先有鸟蛋,因为鸟蛋也是从别的蛋进化来的
-
-
40楼
caisense 2014-07-26 17:33发表
-

-
1.“我们就变成了去最大化 P(Y) ”------ “去”是否应为“求”
2.“这时分裂信息的值为log2n ”-------2是作为底数还是真数
用word应该能搜到吧,具体行数就不写了,求解答谢谢
-
39楼
碎片球球 2014-07-16 16:37发表
-

- 讲的真好,深入浅出。好老师好老师。
-
38楼
kyu_saku 2014-07-11 12:39发表
-

-
(*0*) 比较喜欢糖果那一段
-
Re:
raymond_kwan 2014-07-11 19:04发表
-

- 回复kyu_saku:(*0*)
-
-
37楼
YZYLOVEYZY 2014-07-06 19:48发表
-

- 赞!!看了好多EM的都看不懂,看你写的就懂啦~
-
36楼
github_17251979 2014-07-04 18:18发表
-

-
看的感动的要哭出来。。。
受益匪浅!!
-
35楼
whazyk 2014-06-04 20:04发表
-

- 上面打猎、抽烟的例子本来是用来体现贝叶斯先验优于极大似然的地方,博主用来当做极大似然的例子来举是否不妥。
-
34楼
whazyk 2014-06-04 20:02发表
-
- 上面几个抽烟、打猎的几个例子,本来是用来讲贝叶斯先验优于极大似然的,被用来当极大似然的例子感觉有点不妥。
-
33楼
宇宙蛋 2014-04-24 10:57发表
-
-
楼主讲得很精彩。。。我理解的EM算法是最大似然估计方法--参数估计方法的一种 为什么要引入EM呢 我觉得 因为参数theta本身是依赖于数据的完整特征 但是只观察了部分特征X 因此需要引入隐藏特征Z 才能建立起theta与X,Z的关系。。。
怎么开始这个过程呢?我们现在自己的脑袋里假设存在一个theta(当然我们未知) 利用这个theta对数据进行了采样 由于每个数据的X特征已知 只须采样每个样本的Z特征 (这是一次实验) 利用实验观察的数据(X,Z)来修正我们对theta的理解,即使最大化似然函数的theta值作为新值;然后利用新的theta来做下一次实验 再利用新的数据修正我们对当前theta的理解 。不断重复上述过程 直到现实的观察与我们对世界的理解基本吻合 就停止实验。
至于EM算法为什么容易陷入局部最优解 要采取多次随机初始化呢?我认为 每个人对世界的认识都有限 只能根据自己的经验去判断 与外界缺乏联系 因此 只能做到自己认为的最好-
Re:
迷雾forest 2015-10-09 14:59发表
-
- 回复cannon0102:这个理解太牛了!!!
-
Re:
zyz193 2015-03-19 21:21发表
-

- 回复cannon0102:牛啊,更透彻!
-
Re:
zouxy09 2014-04-24 12:52发表
-

- 回复cannon0102:good,理解的非常好啊,受教了
-
-
32楼
李博Garvin 2014-04-17 17:18发表
-

- 谢谢博主,学到很多
-
31楼
penergy 2014-04-11 22:16发表
-

-
zouxy09老师,
我仔细看了您的这篇文章,通过R语言模拟了你文章男女学生抽样的EM算法,但是效果不太好。问题在于求取Q(z)的过程中,男生类的身高均值很高,女生很低。自己感觉是由于两个正太分布重叠部分太多,导致分类不好。
总之,自己也不知道什么原因。您能不能解释一下,或者看了我的算法之后,如何改进E-step的分类问题。
这是我的帖子:
http://penergy.iteye.com/blog/2043921-
Re:
期望最大化 2015-09-01 17:25发表
-

-
回复penergy:你已经找到了问题所在,那两个分布重叠部分太多。
现实中多用于可以分类的数据。
-
-
30楼
deanlan_sjtu 2014-04-06 19:51发表
-

- 写的浅显易懂,楼主真大牛。。。谢谢楼主。
-
29楼
whynot2412 2014-03-21 17:04发表
-

- 有瑕疵要指出一下。你说的样本应该是样本点,样本集才叫样本。猎人和同学打猎的例子,是贝叶斯先验的最好体现,而不是最大似然。
-
28楼
打破沙锅也要问到底 2014-03-12 17:12发表
-

-
膜拜大神!!!!
原来是这么个意思啊。。。。。。
本科学数学,研究生学计算机。
依然发现自己的数学功底相当薄弱,要补太多太多数学知识。
谢谢大神。这时我看过最好的文章。
我得方向和你的博文都差不多。
果断一篇一篇跟着你学过去
-
27楼
小白鸽 2014-03-12 16:07发表
-

-
我以前就是学数学的,但当时最大似然函数估计只会用,不知道干嘛的.
看了lz通俗易懂的解释,膜拜了.看到lz的文章才豁然开朗.
-
26楼
Elvin_C_L 2014-02-28 12:58发表
-

- 叹服,楼主这个EM是所有讲EM文章里面最通俗易懂的,很多文章都是学院派的,一大堆推导,晕乎其晕,楼主这个有例子,有推导,还有各种管用的口水话,更易于理解。。。顶楼主,多写好文啊
-
25楼
sharpstill 2014-02-09 17:46发表
-

-
说反了吧,f(x) = log x的二阶导数小于0,是凸函数啊,上凸函数,你这个文章里怎么写的凹函数
-
Re:
AceMa 2014-07-22 14:13发表
-

- 回复sharpstill:你把凸凹函数概念搞反了,同学
-
-
24楼
ahuang1900 2014-01-10 12:45发表
-

- 通俗易懂,假如能够举个例子,写点代码实现,应该会更好!
-
23楼
pymqq 2014-01-08 19:27发表
-

- 第三部分,【那我们也许会想,你就是多了一个未知的变量而已啊,我也可以分别对未知的θ和z分别求偏导,再令其等于0,求解出来不也一样吗?】这句话后面没有解释清楚为什么,是因为后面得到“对数的和”后方便求导了,但是此时不在是“等于”了,所以不能同时对未知的θ和z分别求偏导进行求解吗?非常感谢博主,同为研三,感觉自己好搓啊!我要加油!
-
22楼
yayatongnian 2014-01-08 10:00发表
-

- 大爱楼主的文章!真的很感谢这种用心的分享!
-
21楼
gjs0821 2013-12-30 06:49发表
-

- 写的太好了!
-
20楼
wei_chao_cui 2013-12-29 11:34发表
-

- Very Good!
-
19楼
痞子寇 2013-12-20 14:06发表
-

- 投了一票 (写的不错)
-
17楼
GO小胖 2013-12-17 14:24发表
-

- 写的真好
-
16楼
紫荆飘香V 2013-12-12 21:53发表
-

-
前几天在华工上机器学习课的时候,有同学推荐了你的博客,看了一下博主,原来也是华工的,好巧好巧啊。博主是读研几呢?
-
Re:
zouxy09 2013-12-13 00:17发表
-
- 回复ahuang1900:哈哈,幸会幸会!研二了
-
-
15楼
wang_xiaoke 2013-12-11 15:26发表
-

-
楼主在最大似然模块中,所说的样本集X={x1,x2,…,xN}其实应该称为样本,里面的每个xi为个体,N为样本容量。
-
Re:
zouxy09 2013-12-12 09:49发表
-
-
回复wang_xiaoke:样本集实际上是样本的集合,里面包含的是N个样本。我觉得我的表述是没有问题的。
-
Re:
wang_xiaoke 2013-12-12 14:53发表
-
- 回复zouxy09:一次抽样过程得到是应该是一个样本,要得到一个样本集,需要将抽样过程重复N次。样本本身就是一个集合,里面包含了你的观测单元(样例)。严格来说,这种拦截式抽样是不属于概率抽样的。
-
Re:
wang_xiaoke 2013-12-12 14:49发表
-
-
回复zouxy09:你对样本的理解有误哦!
-
Re:
zouxy09 2013-12-12 15:05发表
-
-
回复wang_xiaoke:哦哦,谢谢。我是按照平时机器学习那套来理解了。如果严格按照概率或者统计学来说的话,可能就像您说的这样吧。平时在表达机器学习的训练样本集和测试样本集,也是这么表达了,所以习惯了。哈哈
-
Re:
wang_xiaoke 2013-12-12 15:20发表
-
- 回复zouxy09:仔细看看可以发现,你给出的jerrylead的文章中也是将你所说的样本集定义为样本的。嘿嘿!
-
Re:
wang_xiaoke 2013-12-12 15:16发表
-
- 回复zouxy09:我之前对样本的理解和你是一样的,所以一直不明白,为什么paper中一般都把样本叫example。后来看了统计学中样本的定义,才发现这里的example是指样例,而样本sample则是example的集合。
-
-
-
-
-
14楼
Gcache 2013-10-30 16:17发表
-

- 看了你的博文,受益匪浅,Thanks!
-
13楼
小强茜茜 2013-09-15 17:37发表
-

- 讲的通俗易懂,看了2天的EM,还是这个看懂了,在看统计学习方法的证明就容易多了,谢楼主
-
12楼
系米 2013-07-20 15:32发表
-

- 写的通俗易懂,让我这样的菜鸟都看懂了,谢谢楼主!!
-
11楼
Crossi 2013-06-26 22:29发表
-

- 辛苦楼主了,讲的详细生动到位。
-
10楼
qykshr 2013-06-24 23:48发表
-

- 讲解的很生动,尤其是,做铺垫的那几个例子,受教了
-
9楼
hedabenniao 2013-06-12 15:07发表
-

- 感谢博主分享,谢谢
-
8楼
dvd_rom 2013-05-12 14:16发表
-

- 楼主讲的很好,受教了
-
7楼
v_JULY_v 2013-05-12 00:14发表
-

-
有这个想写成通俗风格的意识不错,可以继续写写其它算法:-)
-
Re:
zouxy09 2013-05-12 16:13发表
-
- 回复v_JULY_v:呵呵,很高兴您逛到这里,您的博客让我很受用,也有很多的感触。非常感谢您!
-
-
6楼
且听风雨999 2013-05-03 14:55发表
-

- 我也喜欢博主这种风格。话说我貌似比楼主口水话更多。顶博主
-
5楼
dxball2 2013-04-28 06:11发表
-

- 说的很好 深入浅出 文章排班也很好 赞一个
-
4楼
u010319374 2013-04-16 12:42发表
-

-
楼主的深度学习和em看完后真的很受益匪浅,特意注册个账号评论下,谢谢楼主!!!!!
-
Re:
zouxy09 2013-04-16 12:59发表
-
- 回复u010319374:呵呵,非常感谢鼓励
-
-
3楼
workerwu 2013-04-15 06:07发表
-

- 楼主列举的例子太形象生动了,赞一个。
-
2楼
ppn029012 2013-04-09 04:51发表
-

-
我觉得,文章的一开始就应该先说EM是什么...看了半天才说EM是expectation maximization...因为是缩写,最好在文章的一开始就稍微解释一下。
不过很喜欢这样的文章! 我也在努力学习博主风格,继续努力!-
Re:
zouxy09 2013-04-09 12:20发表
-
- 回复ppn029012:呵呵,谢谢你的建议。以后会注意,欢迎交流
-
-
1楼
blossomchina 2013-04-03 10:09发表
-

- 说的太好了,谢谢了
核心技术类目
- 个人资料
-

- 访问:6824138次
- 积分:27017
- 等级:

- 排名:第166名
- 原创:116篇
- 转载:11篇
- 译文:1篇
- 评论:3594条

- 个人简介
-
关注:机器学习、计算机视觉、人机交互和人工智能等领域。
邮箱:zouxy09@qq.com
微博: Erik-zou
交流请发邮件,不怎么看博客私信^-^
- 相关资料与课程推荐

- 文章搜索
- 文章分类
- 阅读排行
- (557312)
- (399686)
- (379722)
- (245266)
- (242266)
- (213704)
- (203322)
- (194432)
- (190612)
- (173727)
- 评论排行
- (266)
- (174)
- (172)
- (165)
- (138)
- (120)
- (95)
- (86)
- (81)
- (70)
- 最新评论
: 博主,真大神,代码写的很棒
: 楼主,我的运行错误如下Undefined function 'sigm' for input arg...
: 你好,我遇到同样的问题,你怎么解决的?谢谢
: 此算法的个人觉得不好,第一,跟踪效果,如果运动目标速度过快根本跟踪不上,第二,时间350fps跟踪的...
: 非常赞,适合初学者学习
: @qicongsheng:这位同学你连个毛线都写不出来你信不信
: 博主写的非常好,狂赞一个!
: 楼主有没有计算机图形学关于三维重建的资料,现在在学,但不知道,从何下手?
: 我想知道那个β到底是什么?通过卷积之后的特征图还要乘以这个β再加上偏置常量b然后再输入激活函数吗?在...
: 我想知道那个β到底是什么?通过卷积之后的特征图还要乘以这个β再加上偏置常量b然后再输入激活函数吗?在...

zouxy09的专栏
悲喜枯荣如是本无分别,当来则来,当去则去,随心,随性,随缘!-zouxy09@qq.com
版权声明:本文为博主原创文章,未经博主允许不得转载。
从最大似然到EM算法浅解
机器学习十大算法之一:EM算法。能评得上十大之一,让人听起来觉得挺NB的。什么是NB啊,我们一般说某个人很NB,是因为他能解决一些别人解决不了的问题。神为什么是神,因为神能做很多人做不了的事。那么EM算法能解决什么问题呢?或者说EM算法是因为什么而来到这个世界上,还吸引了那么多世人的目光。
我希望自己能通俗地把它理解或者说明白,但是,EM这个问题感觉真的不太好用通俗的语言去说明白,因为它很简单,又很复杂。简单在于它的思想,简单在于其仅包含了两个步骤就能完成强大的功能,复杂在于它的数学推理涉及到比较繁杂的概率公式等。如果只讲简单的,就丢失了EM算法的精髓,如果只讲数学推理,又过于枯燥和生涩,但另一方面,想把两者结合起来也不是件容易的事。所以,我也没法期待我能把它讲得怎样。希望各位不吝指导。
一、最大似然
扯了太多,得入正题了。假设我们遇到的是下面这样的问题:
假设我们需要调查我们学校的男生和女生的身高分布。你怎么做啊?你说那么多人不可能一个一个去问吧,肯定是抽样了。假设你在校园里随便地活捉了100个男生和100个女生。他们共200个人(也就是200个身高的样本数据,为了方便表示,下面,我说“人”的意思就是对应的身高)都在教室里面了。那下一步怎么办啊?你开始喊:“男的左边,女的右边,其他的站中间!”。然后你就先统计抽样得到的100个男生的身高。假设他们的身高是服从高斯分布的。但是这个分布的均值u和方差∂2我们不知道,这两个参数就是我们要估计的。记作θ=[u, ∂]T。
用数学的语言来说就是:在学校那么多男生(身高)中,我们独立地按照概率密度p(x|θ)抽取100了个(身高),组成样本集X,我们想通过样本集X来估计出未知参数θ。这里概率密度p(x|θ)我们知道了是高斯分布N(u,∂)的形式,其中的未知参数是θ=[u, ∂]T。抽到的样本集是X={x1,x2,…,xN},其中xi表示抽到的第i个人的身高,这里N就是100,表示抽到的样本个数。
由于每个样本都是独立地从p(x|θ)中抽取的,换句话说这100个男生中的任何一个,都是我随便捉的,从我的角度来看这些男生之间是没有关系的。那么,我从学校那么多男生中为什么就恰好抽到了这100个人呢?抽到这100个人的概率是多少呢?因为这些男生(的身高)是服从同一个高斯分布p(x|θ)的。那么我抽到男生A(的身高)的概率是p(xA|θ),抽到男生B的概率是p(xB|θ),那因为他们是独立的,所以很明显,我同时抽到男生A和男生B的概率是p(xA|θ)* p(xB|θ),同理,我同时抽到这100个男生的概率就是他们各自概率的乘积了。用数学家的口吻说就是从分布是p(x|θ)的总体样本中抽取到这100个样本的概率,也就是样本集X中各个样本的联合概率,用下式表示:
这个概率反映了,在概率密度函数的参数是θ时,得到X这组样本的概率。因为这里X是已知的,也就是说我抽取到的这100个人的身高可以测出来,也就是已知的了。而θ是未知了,则上面这个公式只有θ是未知数,所以它是θ的函数。这个函数放映的是在不同的参数θ取值下,取得当前这个样本集的可能性,因此称为参数θ相对于样本集X的似然函数(likehood function)。记为L(θ)。
这里出现了一个概念,似然函数。还记得我们的目标吗?我们需要在已经抽到这一组样本X的条件下,估计参数θ的值。怎么估计呢?似然函数有啥用呢?那咱们先来了解下似然的概念。
直接举个例子:
某位同学与一位猎人一起外出打猎,一只野兔从前方窜过。只听一声枪响,野兔应声到下,如果要你推测,这一发命中的子弹是谁打的?你就会想,只发一枪便打中,由于猎人命中的概率一般大于这位同学命中的概率,看来这一枪是猎人射中的。
这个例子所作的推断就体现了极大似然法的基本思想。
再例如:下课了,一群男女同学分别去厕所了。然后,你闲着无聊,想知道课间是男生上厕所的人多还是女生上厕所的人比较多,然后你就跑去蹲在男厕和女厕的门口。蹲了五分钟,突然一个美女走出来,你狂喜,跑过来告诉我,课间女生上厕所的人比较多,你要不相信你可以进去数数。呵呵,我才没那么蠢跑进去数呢,到时还不得上头条。我问你是怎么知道的。你说:“5分钟了,出来的是女生,女生啊,那么女生出来的概率肯定是最大的了,或者说比男生要大,那么女厕所的人肯定比男厕所的人多”。看到了没,你已经运用最大似然估计了。你通过观察到女生先出来,那么什么情况下,女生会先出来呢?肯定是女生出来的概率最大的时候了,那什么时候女生出来的概率最大啊,那肯定是女厕所比男厕所多人的时候了,这个就是你估计到的参数了。
从上面这两个例子,你得到了什么结论?
回到男生身高那个例子。在学校那么男生中,我一抽就抽到这100个男生(表示身高),而不是其他人,那是不是表示在整个学校中,这100个人(的身高)出现的概率最大啊。那么这个概率怎么表示?哦,就是上面那个似然函数L(θ)。所以,我们就只需要找到一个参数θ,其对应的似然函数L(θ)最大,也就是说抽到这100个男生(的身高)概率最大。这个叫做θ的最大似然估计量,记为:
有时,可以看到L(θ)是连乘的,所以为了便于分析,还可以定义对数似然函数,将其变成连加的:
好了,现在我们知道了,要求θ,只需要使θ的似然函数L(θ)极大化,然后极大值对应的θ就是我们的估计。这里就回到了求最值的问题了。怎么求一个函数的最值?当然是求导,然后让导数为0,那么解这个方程得到的θ就是了(当然,前提是函数L(θ)连续可微)。那如果θ是包含多个参数的向量那怎么处理啊?当然是求L(θ)对所有参数的偏导数,也就是梯度了,那么n个未知的参数,就有n个方程,方程组的解就是似然函数的极值点了,当然就得到这n个参数了。
最大似然估计你可以把它看作是一个反推。多数情况下我们是根据已知条件来推算结果,而最大似然估计是已经知道了结果,然后寻求使该结果出现的可能性最大的条件,以此作为估计值。比如,如果其他条件一定的话,抽烟者发生肺癌的危险时不抽烟者的5倍,那么如果现在我已经知道有个人是肺癌,我想问你这个人抽烟还是不抽烟。你怎么判断?你可能对这个人一无所知,你所知道的只有一件事,那就是抽烟更容易发生肺癌,那么你会猜测这个人不抽烟吗?我相信你更有可能会说,这个人抽烟。为什么?这就是“最大可能”,我只能说他“最有可能”是抽烟的,“他是抽烟的”这一估计值才是“最有可能”得到“肺癌”这样的结果。这就是最大似然估计。
好了,极大似然估计就讲到这,总结一下:
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
求最大似然函数估计值的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数,令导数为0,得到似然方程;
(4)解似然方程,得到的参数即为所求;
二、EM算法
好了,重新回到上面那个身高分布估计的问题。现在,通过抽取得到的那100个男生的身高和已知的其身高服从高斯分布,我们通过最大化其似然函数,就可以得到了对应高斯分布的参数θ=[u, ∂]T了。那么,对于我们学校的女生的身高分布也可以用同样的方法得到了。
再回到例子本身,如果没有“男的左边,女的右边,其他的站中间!”这个步骤,或者说我抽到这200个人中,某些男生和某些女生一见钟情,已经好上了,纠缠起来了。咱们也不想那么残忍,硬把他们拉扯开。那现在这200个人已经混到一起了,这时候,你从这200个人(的身高)里面随便给我指一个人(的身高),我都无法确定这个人(的身高)是男生(的身高)还是女生(的身高)。也就是说你不知道抽取的那200个人里面的每一个人到底是从男生的那个身高分布里面抽取的,还是女生的那个身高分布抽取的。用数学的语言就是,抽取得到的每个样本都不知道是从哪个分布抽取的。
这个时候,对于每一个样本或者你抽取到的人,就有两个东西需要猜测或者估计的
了, 一是这个人是男的还是女的?二是男生和女生对应的身高的高斯分布的参数是多少?只有当我们知道了哪些人属于同一个高斯分布的时候,我们才能够对这个分布的参数作出靠谱的预测,例如刚开始的最大似然所说的,但现在两种高斯分布的人混在一块了,我们又不知道哪些人属于第一个高斯分布,哪些属于第二个,所以就没法估计这两个分布的参数。反过来,只有当我们对这两个分布的参数作出了准确的估计的时候,才能知道到底哪些人属于第一个分布,那些人属于第二个分布。
这就成了一个先有鸡还是先有蛋的问题了。鸡说,没有我,谁把你生出来的啊。蛋不服,说,没有我,你从哪蹦出来啊。(呵呵,这是一个哲学问题。当然了,后来科学家说先有蛋,因为鸡蛋是鸟蛋进化的)。为了解决这个你依赖我,我依赖你的循环依赖问题,总得有一方要先打破僵局,说,不管了,我先随便整一个值出来,看你怎么变,然后我再根据你的变化调整我的变化,然后如此迭代着不断互相推导,最终就会收敛到一个解。这就是EM算法的基本思想了。
不知道大家能否理解其中的思想,我再来啰嗦一下。其实这个思想无处在不啊。
例如,小时候,老妈给一大袋糖果给你,叫你和你姐姐等分,然后你懒得去点糖果的个数,所以你也就不知道每个人到底该分多少个。咱们一般怎么做呢?先把一袋糖果目测的分为两袋,然后把两袋糖果拿在左右手,看哪个重,如果右手重,那很明显右手这代糖果多了,然后你再在右手这袋糖果中抓一把放到左手这袋,然后再感受下哪个重,然后再从重的那袋抓一小把放进轻的那一袋,继续下去,直到你感觉两袋糖果差不多相等了为止。呵呵,然后为了体现公平,你还让你姐姐先选了。
EM算法就是这样,假设我们想估计知道A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM的意思是“Expectation Maximization
”,在我们上面这个问题里面,我们是先随便猜一下男生(身高)的正态分布的参数:如均值和方差是多少。例如男生的均值是 1米 7,方差是 0.1米(当然了,刚开始肯定没那么准),然后计算出每个人更可能属于第一个还是第二个正态分布中的(例如,这个人的身高是 1米 8,那很明显,他最大可能属于男生的那个分布),这个是属于 Expectation一步。有了每个人的归属,或者说我们已经大概地按上面的方法将这 200个人分为男生和女生两部分,我们就可以根据之前说的最大似然那样,通过这些被大概分为男生的 n个人来重新估计第一个分布的参数,女生的那个分布同样方法重新估计。这个是 Maximization。然后,当我们更新了这两个分布的时候,每一个属于这两个分布的概率又变了,那么我们就再需要调整 E步……如此往复,直到参数基本不再发生变化为止。这里把每个人(样本)的完整描述看做是三元组yi={xi,zi1,zi2},其中,xi是第i个样本的观测值,也就是对应的这个人的身高,是可以观测到的值。zi1和zi2表示男生和女生这两个高斯分布中哪个被用来产生值xi,就是说这两个值标记这个人到底是男生还是女生(的身高分布产生的)。这两个值我们是不知道的,是隐含变量。确切的说,zij在xi由第j个高斯分布产生时值为1,否则为0。例如一个样本的观测值为1.8,然后他来自男生的那个高斯分布,那么我们可以将这个样本表示为{1.8, 1, 0}。如果zi1和zi2的值已知,也就是说每个人我已经标记为男生或者女生了,那么我们就可以利用上面说的最大似然算法来估计他们各自高斯分布的参数。但是它们未知,因此我们只能用EM算法。
咱们现在不是因为那个恶心的隐含变量(抽取得到的每个样本都不知道是从哪个分布抽取的)使得本来简单的可以求解的问题变复杂了,求解不了吗。那怎么办呢?人类解决问题的思路都是想能否把复杂的问题简单化。好,那么现在把这个复杂的问题逆回来,我假设已经知道这个隐含变量了,哎,那么求解那个分布的参数是不是很容易了,直接按上面说的最大似然估计就好了。那你就问我了,这个隐含变量是未知的,你怎么就来一个假设说已知呢?你这种假设是没有根据的。呵呵,我知道,所以我们可以先给这个给分布弄一个初始值,然后求这个隐含变量的期望,当成是这个隐含变量的已知值,那么现在就可以用最大似然求解那个分布的参数了吧,那假设这个参数比之前的那个随机的参数要好,它更能表达真实的分布,那么我们再通过这个参数确定的分布去求这个隐含变量的期望,然后再最大化,得到另一个更优的参数,……迭代,就能得到一个皆大欢喜的结果了。
这时候你就不服了,说你老迭代迭代的,你咋知道新的参数的估计就比原来的好啊?为什么这种方法行得通呢?有没有失效的时候呢?什么时候失效呢?
用到这个方法需要注意什么问题呢?呵呵,一下子抛出那 么多问题,搞得我适应不过来了,不过这证明了你有很好的搞研究的潜质啊。呵呵,其实这些问题就是数学家需要解决的问题。在数学上是可以稳当的证明的或者得出结论的。那咱们用数学来把上面的问题重新描述下。( 在这里可以知道,不管多么复杂或者简单的物理世界的思想,都需要通过数学工具进行建模抽象才得以使用并发挥其强大的作用,而且,这里面蕴含的数学往往能带给你更多想象不到的东西,这就是数学的精妙所在啊)
三、EM算法推导
假设我们有一个样本集{x(1),…,x(m)},包含m个独立的样本。但每个样本i对应的类别z(i)是未知的(相当于聚类),也即隐含变量。故我们需要估计概率模型p(x,z)的参数θ,但是由于里面包含隐含变量z,所以很难用最大似然求解,但如果z知道了,那我们就很容易求解了。
对于参数估计,我们本质上还是想获得一个使似然函数最大化的那个参数θ,现在与最大似然不同的只是似然函数式中多了一个未知的变量z,见下式(1)。也就是说我们的目标是找到适合的θ和z让L(θ)最大。那我们也许会想,你就是多了一个未知的变量而已啊,我也可以分别对未知的θ和z分别求偏导,再令其等于0,求解出来不也一样吗?
本质上我们是需要最大化(1)式(对(1)式,我们回忆下联合概率密度下某个变量的边缘概率密度函数的求解,注意这里z也是随机变量。对每一个样本i的所有可能类别z求等式右边的联合概率密度函数和,也就得到等式左边为随机变量x的边缘概率密度),也就是似然函数,但是可以看到里面有“和的对数”,求导后形式会非常复杂(自己可以想象下log(f1(x)+ f2(x)+ f3(x)+…)复合函数的求导),所以很难求解得到未知参数z和θ。那OK,我们可否对(1)式做一些改变呢?我们看(2)式,(2)式只是分子分母同乘以一个相等的函数,还是有“和的对数”啊,还是求解不了,那为什么要这么做呢?咱们先不管,看(3)式,发现(3)式变成了“对数的和”,那这样求导就容易了。我们注意点,还发现等号变成了不等号,为什么能这么变呢?这就是Jensen不等式的大显神威的地方。
Jensen不等式:
设f是定义域为实数的函数,如果对于所有的实数x。如果对于所有的实数x,f(x)的二次导数大于等于0,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的,那么f是凸函数。如果只大于0,不等于0,那么称f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么:E[f(X)]>=f(E[X])
特别地,如果f是严格凸函数,当且仅当X是常量时,上式取等号。
如果用图表示会很清晰:
图中,实线f是凸函数,X是随机变量,有0.5的概率是a,有0.5的概率是b。(就像掷硬币一样)。X的期望值就是a和b的中值了,图中可以看到E[f(X)]>=f(E[X])成立。
当f是(严格)凹函数当且仅当-f是(严格)凸函数。
Jensen不等式应用于凹函数时,不等号方向反向。
回到公式(2),因为f(x)=log x为凹函数(其二次导数为-1/x2<0)。
(2)式中的期望,(考虑到E(X)=∑x*p(x),f(X)是X的函数,则E(f(X))=∑f(x)*p(x)),又,所以就可以得到公式(3)的不等式了(若不明白,请拿起笔,呵呵):
OK,到这里,现在式(3)就容易地求导了,但是式(2)和式(3)是不等号啊,式(2)的最大值不是式(3)的最大值啊,而我们想得到式(2)的最大值,那怎么办呢?
现在我们就需要一点想象力了,上面的式(2)和式(3)不等式可以写成:似然函数L(θ)>=J(z,Q),那么我们可以通过不断的最大化这个下界J,来使得L(θ)不断提高,最终达到它的最大值。
见上图,我们固定θ,调整Q(z)使下界J(z,Q)上升至与L(θ)在此点θ处相等(绿色曲线到蓝色曲线),然后固定Q(z),调整θ使下界J(z,Q)达到最大值(θt到θt+1),然后再固定θ,调整Q(z)……直到收敛到似然函数L(θ)的最大值处的θ*。这里有两个问题:什么时候下界J(z,Q)与L(θ)在此点θ处相等?为什么一定会收敛?
首先第一个问题,在Jensen不等式中说到,当自变量X是常数的时候,等式成立。而在这里,即:
再推导下,由于(因为Q是随机变量z(i)的概率密度函数),则可以得到:分子的和等于c(分子分母都对所有z(i)求和:多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),则:
至此,我们推出了在固定参数θ后,使下界拉升的Q(z)的计算公式就是后验概率,解决了Q(z)如何选择的问题。这一步就是E步,建立L(θ)的下界。接下来的M步,就是在给定Q(z)后,调整θ,去极大化L(θ)的下界J(在固定Q(z)后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
EM算法(Expectation-maximization):
期望最大算法是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。
EM的算法流程:
初始化分布参数θ;
重复以下步骤直到收敛:
E步骤:根据参数初始值或上一次迭代的模型参数来计算出隐性变量的后验概率,其实就是隐性变量的期望。作为隐藏变量的现估计值:
M步骤:将似然函数最大化以获得新的参数值:
这个不断的迭代,就可以得到使似然函数L(θ)最大化的参数θ了。那就得回答刚才的第二个问题了,它会收敛吗?
感性的说,因为下界不断提高,所以极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。理性分析的话,就会得到下面的东西:
具体如何证明的,看推导过程参考:Andrew Ng《The EM algorithm》
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
四、EM算法另一种理解
坐标上升法(Coordinate ascent):
图中的直线式迭代优化的路径,可以看到每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。
这犹如在x-y坐标系中找一个曲线的极值,然而曲线函数不能直接求导,因此什么梯度下降方法就不适用了。但固定一个变量后,另外一个可以通过求导得到,因此可以使用坐标上升法,一次固定一个变量,对另外的求极值,最后逐步逼近极值。对应到EM上,E步:固定θ,优化Q;M步:固定Q,优化θ;交替将极值推向最大。
五、EM的应用
EM算法有很多的应用,最广泛的就是GMM混合高斯模型、聚类、HMM等等。具体可以参考JerryLead的cnblog中的Machine Learning专栏:
混合高斯模型(Mixtures of Gaussians)和EM算法
K-means聚类算法
没有鸡和蛋的先后之争,因为他们都知道“没有你就没有我”。从此他们一起过上了幸福美好的生活。
-
顶
- 197
-
踩
- 6
参考知识库
-
猜你在找
-
132楼
Charlie818 2016-12-29 23:44发表
-
- 虽说例子有些琐碎,也有些冷,但能感觉到博主在努力举例子诠释这个概念,让我们明白,谢谢博主!
-
131楼
sinat_15560643巴黎圣日尔曼 2016-12-09 11:05发表
-
- 就是说EM算法每次迭代的时候都要更新核函数的参数,是吗?
-
130楼
番茄炒鸡蛋 2016-12-05 14:29发表
-
- 真啰嗦。。。唧唧歪歪步入正题。搞呢么多反问
-
- 回复qicongsheng:这位同学你连个毛线都写不出来你信不信
-
- 回复qicongsheng:这位同学你写一篇试试....不然就尊重人家的成果~
-
- 感谢您对知识的分享!
-
Re:
神谷姬爱ML 昨天 14:17发表
-
Re:
忆臻 2016-12-10 09:23发表
-
Re:
dalerkd 2016-12-08 11:28发表
-
129楼
caotuhao 2016-12-04 16:52发表
-
- 膜拜啊 感激大牛
-
128楼
Jetqvvf_what 2016-11-10 11:51发表
-
- 猎人打兔子的例子中,兔子被猎人打死了,如果不知道谁更准,那我猜猎人更准,应该这样是最大似然估计吧,貌似楼主说反了。
-
127楼
jpzhoucsdn 2016-11-04 10:14发表
-
- 不错,赞一个,如此深奥的道理,讲得通俗易懂,可见博主的功底真不一般。
-
126楼
mimicdj 2016-10-24 21:56发表
-
- 虽然有些笑话很冷,但是丝毫不减我看这篇文章的兴奋。赞!
-
125楼
lppl 2016-10-17 18:54发表
-
- 打滚膜拜大神,谢谢楼主
-
124楼
qq_36079872 2016-10-15 16:14发表
-
- 写的太好了,形象,看完了竟然没感觉枯燥。HIT学生前来学习
-
123楼
a649339266 2016-09-27 09:52发表
-
- 最后求出来的Theta是男生分布的还是女生分布的呢
-
122楼
哈士奇说喵 2016-09-23 15:07发表
-
- 能那么用心写博客的人真的很少了啊,必须赞一个
-
121楼
人工智能times 2016-09-21 18:11发表
-
-
例子讲的不错,推导思路不错。但是以我一个数学系的学生来说,推导步骤省略太多,跳跃太大,同时感觉凸函数那个地方不是很准确,谢谢
PS:其实最后证明只需要说明单调递增有上确界必收敛到上确界
-
120楼
tyf0425 2016-09-05 15:43发表
-
- 写得通俗易懂,看了好多博客,还是在这里看懂了,但是我感觉Jensen不等式那里的凹凸函数写反了,不知道是不是这样,还是我理解错了?
-
- 回复tyf0425: 不是的, 国外的凸函数定义跟我们教材上的相反
-
- 回复gladys132013:原来是这样 我知道了 谢谢你!
-
Re:
gladys132013 2016-09-18 22:05发表
-
Re:
tyf0425 2016-10-13 10:49发表
-
119楼
怠馬 2016-08-23 18:20发表
-
- 赞!
-
118楼
何小毛哒哒哒 2016-08-05 12:12发表
-
-
写的非常的好,第一次真正地把EM算法给弄懂了。谢谢你!
非常喜欢这种通俗但又恰到好处的解释。
-
117楼
ulando 2016-07-19 18:39发表
-
- 写的很好,赞,谢谢分享。
-
116楼
追寻灯火阑珊 2016-07-07 10:55发表
-
- mark
-
115楼
mengan1223334444 2016-06-17 11:49发表
-
-
上面的函数叫凹函数,不是凸函数。y''>0,凹函数,如y=x2,y''=2>0,凹函数。
如下面中:
设f是定义域为实数的函数,如果对于所有的实数x。如果对于所有的实数x,f(x)的二次导数大于等于0,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的,那么f是凸函数。如果只大于0,不等于0,那么称f是严格凸函数。
我没有理解错吧? -
- 回复mengan1223334444:。。。文中的凸函数是凸优化的那种凸函数,不是高数中的那个定义。。。
-
- 回复mengan1223334444:so sad, you mixed concept of conVex and conCAVE.
-
Re:
qq_35552388 2016-07-08 19:05发表
-
Re:
HDACMer 2016-07-07 10:24发表
-
114楼
夏驰Lock 2016-05-22 23:09发表
-
- E步骤中,为什么隐性变量的后验概率,就是隐性变量的期望?
-
113楼
ken_92 2016-05-16 15:34发表
-
- 写得太好了!在之前对EM的理解上更近了一步,谢谢楼主!
-
112楼
yexiadan276 2016-04-14 15:45发表
-
- 太赞了,多谢楼主
-
111楼
小米0921 2016-04-10 18:24发表
-
- f(x)=logx是凸函数还是凹函数啊?满足E[f(x)] >= f(E[x])吗?
-
110楼
秋光 2016-04-08 13:48发表
-
-
楼主,我想问一下EM算法步骤里边的那个期望怎么求?
p(z(i)|x(i); θ)这个怎么求呢?
-
109楼
FlytoYoung 2016-04-01 17:11发表
-
-
大神,在由公式(2)推导公式(3)的不等式时,是不是写反了?
根据Jensen不等式来讲:不应该是E[f(x)] >= f(E[x])吗?但文中似乎反了。。 -
- 回复FlytoYoung:我因为这个错误。。。弄了一下午。。。智商掉一地啊
-
- 回复FlytoYoung:f(x)=logx是凸函数还是凹函数啊?满足E[f(x)] >= f(E[x])吗?
-
- 回复FlytoYoung:额,刚发现,是凹函数。。。我去。。好吧。自己犯了低级错误
-
Re:
a649339266 2016-09-22 20:52发表
-
Re:
小米0921 2016-04-10 18:24发表
-
Re:
FlytoYoung 2016-04-01 17:23发表
-
108楼
brave heart 2016-03-25 12:13发表
-
- 你的函数凹凸性是不是说反了啊?
-
107楼
csj1993 2016-03-21 16:40发表
-
- 麻烦问下楼主,还是不太懂hmm工具箱中em算法的主要目的是什么?
-
106楼
cothee 2016-03-14 13:59发表
-
- 您好,最近正在学习EM算法,看了您的博客,感觉很受启发。我有一个问题,就是关于Z右上角那个i和X右上角那个i并不是一回事,所以我觉得是不是改成j或换乘其他符号可以更好的区分一下呢?还请解惑……
-
- 回复cothee:z和x的i是一回事,都表示第i个训练样本
-
Re:
lipeng19930407 2016-03-16 20:34发表
-
105楼
Lvhhh 2016-03-06 08:41发表
-
- http://blog.csdn.net/lvhao92/article/details/50805021
-
104楼
cl11235813 2016-02-03 06:21发表
-
- 谢谢楼主,相当通俗易懂的解释!!!
-
103楼
xiangshoujiyi 2016-01-15 11:58发表
-
- 通俗易懂,非常不错!!!
-
102楼
missdan2015 2016-01-13 14:54发表
-
- 深入人心,受教了,尤其是那些生动的例子
-
101楼
小小程序猿_ 2016-01-11 20:30发表
-
- 但是我对Q(Z)这个函数的具体含义还是不太理解...写的都看明白了,但是感觉楼主还差一个具体是事列(在EM的最后),包括最后公司里面每一个函数的意义和用法的说明...
-
- 回复tangbo713:我也不太懂,哥们弄懂了教教我,而且上面说是z的概率分布z的概率分布不是p(z)吗?
-
Re:
silly_fox 2016-03-08 00:12发表
-
100楼
还有名字 2015-12-31 13:58发表
-
- 楼主写的大赞,对于刚开始学ML的我,对于依然忘记线性代数的我,读起来很容易理解,循循善诱!
-
99楼
一生所求bu 2015-12-27 16:01发表
-
- 思维清晰,内容详细丰富
-
98楼
Jorfun 2015-12-23 09:58发表
-
- 这几天看了不少资料,感觉博主的解释是最为详细的,把一些我不太明白的概念都串联了起来。非常谢谢您的分享~
-
97楼
呆维 2015-12-21 21:08发表
-
- 就要这样深入浅出的文章,顶
-
96楼
阿炜 2015-12-06 17:42发表
-
- 比较色的同志,看什么就是透!赞!
-
95楼
阿炜 2015-12-06 17:41发表
-
- 比较色的同志,看什么就是透!赞!
-
94楼
weixliui 2015-12-04 12:18发表
-
- lz文章写的很不错,最大似然估计这部分通俗易懂很快就了解了思想。关于EM已经很不错的,但是作为小白还是有些障碍,主要原因:1.EM算法其中Q(zi)函数一开始的引入并没有解释这个函数的意义,所以没有能够理解,直接解释其为zi的分布函数感觉会更容易理解。2.lz的那个手绘的优化图实在没有太理解,绿色和蓝色的均值怎么出现在同一条直线了...这里我硬生生理解优化下界可以提高最大值了。总而言之,楼主文章还是很赞。
-
93楼
weixliui 2015-12-04 11:30发表
-
- lz文章写的很不错,最大似然估计这部分通俗易懂很快就了解了思想。关于EM已经很不错的,但是作为小白还是有些障碍,主要原因:1.EM算法其中Q(zi)函数一开始的引入并没有解释这个函数的意义,所以没有能够理解,直接解释其为zi的分布函数感觉会更容易理解。2.lz的那个手绘的优化图实在没有太理解,绿色和蓝色的均值怎么出现在同一条直线了...这里我硬生生理解优化下界可以提高最大值了。总而言之,楼主文章还是很赞。
-
- 回复liu_xiao_wei:请问一下 你的意思是 Q(z)表示z的概率分布 ,那也就是Q(z)=P(z)?
-
Re:
silly_fox 2016-03-08 09:00发表
-
92楼
Yetixie1994 2015-12-01 17:31发表
-
- 那第一次循环算E-step的时候,参数的值是带哪个?是带一个随机的参数;还是假设完Z,用M-step算出参数,再把参数值带入E-step呀?
-
91楼
professionall 2015-11-30 20:17发表
-
- 真不错
-
90楼
蔡叫兽 2015-11-17 09:51发表
-
- 写得真好,学习了
-
- 回复cpsinwhu:赫然见到蔡教授!
-
Re:
weixinyu127 2016-06-30 16:36发表
-
89楼
Z-Chris 2015-11-04 15:17发表
-
- 写的很好,但是有点小建议,博主把太多精力放在讲前面的基本概念上,导致读起来感觉头重脚轻的。应该将一部分精力放在基本概念上,然后把重点放在公式的讲解上。
-
88楼
multiangle 2015-11-02 13:51发表
-
- 通俗易懂,非常感谢~
-
87楼
Ffanfanm 2015-10-12 10:33发表
-
-
一个小小的建议。
样本是指研究中实际观测或调查的一部分个体,你博文中称“样本集”意思就有偏差了,成了很多个样例集的意思。建议博主把“样本集”改为“样例集”
-
86楼
enexygbz 2015-10-10 17:25发表
-
- 写的很好 谢谢
-
85楼
motoyule 2015-10-07 22:26发表
-
- 这是我见过最好的EM算法通俗解释了。但是凹凸性和jesen不等式这里稍有瑕疵。函数其实未必可导的也未必连续,但是jesen不等式仅仅和凹凸性有关,也就是说函数虽然不连续,jesen依旧成立,同时jesen不等式也不是这样的,这只是 jesen不等式的特例,因为期望是随机变量在测度空间上求积分,所以jesen不等式带来了期望上的不等式的成立。
-
84楼
296163849 2015-09-11 18:52发表
-
- 肺癌与烟民的例子有错误吧。考虑到人群中烟民的比例不大,概率上来看,应该猜不吸烟比较正确,但是我也不知道你错在哪里,为什么会得出这样的结论呢?
-
- 回复u011857056:作者依据的是,根据统计吸烟人群中得肺癌的比较多,而不是人群中吸烟的人数比较少。
-
Re:
迷雾forest 2015-10-12 16:10发表
-
83楼
chongchong24 2015-09-10 10:35发表
-
- 请问目前有没有什么好的策略能够避免EM算法陷入局部最优解
-
- 回复chongchong24:有一个随机EM算法可以
-
Re:
sinat_33931042 2016-02-04 22:46发表
-
82楼
xueditanglang1 2015-08-19 11:32发表
-
- 这篇看得最是明白了,感谢博主分享啊
-
81楼
xwzhong2016 2015-08-06 19:58发表
-
- 顶
-
80楼
qq_26966809 2015-07-18 09:33发表
-
- 说的太好了!!!看了半天没看懂的em终于明白了!
-
79楼
袁良锭 2015-07-16 11:20发表
-
- 公式全部不显示了呢。
-
78楼
dmkl123 2015-07-02 22:04发表
-
- 看了那么多,这篇是看得最懂的了!讲得太好了
-
77楼
zsfcg 2015-06-11 21:15发表
-
- 写得好!!!感谢,感谢你们这些默默耕耘的人!人类的知识因为你们而得以传播的更广,变得更完善!
-
76楼
925813290 2015-06-04 18:31发表
-
- 好棒
-
75楼
sinat_28503151 2015-05-26 17:11发表
-
- 求解释:为什么在E步骤里计算出的隐性变量的后验概率Q,“其实就是隐性变量的期望“?
-
74楼
lvchahp 2015-05-24 23:26发表
-
- 楼主你好~极大似然之所以是连乘是因为假设样本是独立同分布的,所以密度函数可以写成连乘的形式。看了博客受益匪浅,非常感谢!
-
73楼
拾毅者 2015-05-22 09:20发表
-
- 这个算法数学功底要好,可是感觉概率论这块没学好 都忘了
-
72楼
yanghuatang 2015-05-06 14:48发表
-
- 很不错!!关于poisson分布的最大似然估计,很多数据的怎么求?
-
71楼
hhran123 2015-05-02 17:28发表
-
- 楼主说的很好,情不自禁一路看完
-
70楼
zhuxianduowan 2015-04-23 09:51发表
-
- 已经被绕晕了
-
69楼
DqWong 2015-04-15 14:51发表
-
- 只有我一个人觉得废话连篇吗?看了半天一直没看到重点
-
- 回复u010381648:这篇文章写的非常好,例子看似很多但是都恰到好处
-
Re:
qq_34531825 2016-09-23 22:32发表
-
68楼
KlausQi 2015-04-14 08:40发表
-
- 深入浅出,例子很生动,支持楼主!!!
-
67楼
coolclient 2015-04-07 09:44发表
-
- 博主,深入浅出,例子举的非常的好!
-
66楼
_KDH 2015-04-05 21:56发表
-
- p(zi|xi;theta)怎么算
-
65楼
BARDDD 2015-03-25 16:03发表
-
- 写的很好,学习了!
-
64楼
Li_ableXiao 2015-03-25 13:42发表
-
- 博主碉堡了,讲解很精彩~~~
-
63楼
会敲键盘的猩猩 2015-03-17 14:54发表
-
- 博主讲解的很清晰易懂,非常感谢。
-
62楼
ld331239828 2015-03-13 20:40发表
-
- 膜拜,能否在深入浅出的讲解一下GMM
-
61楼
tianbwin2995 2015-02-03 12:45发表
-
- 楼主nb啊 说的深入浅出 希望多写一些供学弟们学习!
-
60楼
鼓Sk8er 2015-01-14 11:27发表
-
- 作者写的真好。我也看了你关于DeepLearning的文章。我正在理解RBM,你觉得RBM的优化原理(Gibbs Sampling)是不是就是这里的EM算法?
-
- 回复zzz7290: EM算法做的是参数的点估计 假设参数是未 知常数,Gibbs采样则是估计参数的后验概率分布 假设参数是满足一定先验概率的随机变量 通过估计参数后验再求参数的期望来间接求解参数 避免学习参数出现置信误差(过拟合)
-
- 回复zzz7290:还真不是,EM算法的关键在于期望的最大化,而不是迭代调参的过程。吉布斯采样同样有迭代过程,但和EM还是两回事
-
Re:
宇宙蛋 2015-05-28 20:34发表
-
Re:
johnnyconstantine 2015-03-27 10:02发表
-
59楼
wxklr 2015-01-08 16:08发表
-
- 精彩!总算明白什么是最大似然及为什么要引入那个隐变量了
-
58楼
houyue 2015-01-07 14:15发表
-
- 赞一下啦。
-
57楼
有梦的码农 2014-12-08 11:17发表
-
- 楼主nb啊,讲的通俗易懂,学习了
-
56楼
saldlFLSA 2014-12-02 17:08发表
-
- 弱弱的问一句,您博客中的图(数学符号、分布图等等)都是怎么做的?要写课程报告,不会作图-_-
-
55楼
linzhineng44 2014-11-22 23:41发表
-
- 非常赞,博主提到的问题,我都想过了。很好解决了问题!非常感谢,特别是举得例子!!!
-
54楼
我真的不是赵能飞 2014-11-22 19:47发表
-
- 拜读了 写的非常好 研一的飘过
-
53楼
曼陀罗彼岸花 2014-10-19 23:26发表
-
- 博主说的很明白,终于看懂了EM算法,而且还很深刻。厉害,赞一个!!
-
52楼
西电菜鸟 2014-10-19 21:05发表
-
- 太有用了,希望能发一篇变分贝叶斯的博客,最近在看这个
-
51楼
NgHingtim 2014-10-15 23:16发表
-
- 撸主的鸡与蛋举得例子很恰当,终于明白了EM算法怎么回事?
-
50楼
zwlh1990 2014-10-11 12:51发表
-
- 楼主真乃牛人,把深奥的道理用生动形象的语言表达了出来,讲得太好了,想必楼主对此已做了相当多的研究,看完真是很感动,比我们那老师上课BB叨了90分钟都管用,现在是真的明白了!感谢楼主!!!
-
49楼
xclovecx1314 2014-09-21 19:53发表
-
- 写的非常好,感谢楼主!
-
48楼
YXY_1989 2014-09-19 09:31发表
-
- 写的很好,很容易理解
-
47楼
MrsYoung 2014-09-15 10:40发表
-
- 看过了之后感觉很简单易懂,语言风趣幽默,但是同时也发现了自己的数学功底相当之薄弱。。
-
46楼
En_Dea_Vor 2014-09-05 21:09发表
-
- 顶一个~
-
45楼
洛萨之子 2014-09-01 18:12发表
-
- 回复yihualuomeng:国内的,尤其是同济的高等数学,凹凸性是相反的,而在经济学等领域,凹凸性与国外的相同,所以明白了吗
-
- 回复hit_suit:嗯,后来知道了,所以就把评论删了。博主写得不错,继续加油哈
-
Re:
IT小飞飞 2014-09-03 11:04发表
-
44楼
bee0308 2014-08-29 14:50发表
-
- 好好好好好好好~~~~~
-
43楼
迷雾forest 2014-08-27 21:02发表
-
- 这是我看过的EM算法讲的最清楚的地方,另外,EM算法可以被理解成为引入隐含变量(往往对应于丢失数据)的坐标上升法,不知道我这么理解对不对?
-
42楼
今夕望月 2014-08-12 14:08发表
-
- 先马之
-
41楼
xiaozixiaozhi 2014-08-06 19:20发表
-
- 先有鸟蛋还是先有鸟
-
- 回复xiaozixiaozhi:先有鸟蛋,因为鸟蛋也是从别的蛋进化来的
-
Re:
JokerMi 2015-04-20 20:00发表
-
40楼
caisense 2014-07-26 17:33发表
-
-
1.“我们就变成了去最大化 P(Y) ”------ “去”是否应为“求”
2.“这时分裂信息的值为log2n ”-------2是作为底数还是真数
用word应该能搜到吧,具体行数就不写了,求解答谢谢
-
39楼
碎片球球 2014-07-16 16:37发表
-
- 讲的真好,深入浅出。好老师好老师。
-
38楼
kyu_saku 2014-07-11 12:39发表
-
- (*0*) 比较喜欢糖果那一段
-
- 回复kyu_saku:(*0*)
-
Re:
raymond_kwan 2014-07-11 19:04发表
-
37楼
YZYLOVEYZY 2014-07-06 19:48发表
-
- 赞!!看了好多EM的都看不懂,看你写的就懂啦~
-
36楼
github_17251979 2014-07-04 18:18发表
-
-
看的感动的要哭出来。。。
受益匪浅!!
-
35楼
whazyk 2014-06-04 20:04发表
-
- 上面打猎、抽烟的例子本来是用来体现贝叶斯先验优于极大似然的地方,博主用来当做极大似然的例子来举是否不妥。
-
34楼
whazyk 2014-06-04 20:02发表
-
- 上面几个抽烟、打猎的几个例子,本来是用来讲贝叶斯先验优于极大似然的,被用来当极大似然的例子感觉有点不妥。
-
33楼
宇宙蛋 2014-04-24 10:57发表
-
-
楼主讲得很精彩。。。我理解的EM算法是最大似然估计方法--参数估计方法的一种 为什么要引入EM呢 我觉得 因为参数theta本身是依赖于数据的完整特征 但是只观察了部分特征X 因此需要引入隐藏特征Z 才能建立起theta与X,Z的关系。。。
怎么开始这个过程呢?我们现在自己的脑袋里假设存在一个theta(当然我们未知) 利用这个theta对数据进行了采样 由于每个数据的X特征已知 只须采样每个样本的Z特征 (这是一次实验) 利用实验观察的数据(X,Z)来修正我们对theta的理解,即使最大化似然函数的theta值作为新值;然后利用新的theta来做下一次实验 再利用新的数据修正我们对当前theta的理解 。不断重复上述过程 直到现实的观察与我们对世界的理解基本吻合 就停止实验。
至于EM算法为什么容易陷入局部最优解 要采取多次随机初始化呢?我认为 每个人对世界的认识都有限 只能根据自己的经验去判断 与外界缺乏联系 因此 只能做到自己认为的最好 -
- 回复cannon0102:这个理解太牛了!!!
-
- 回复cannon0102:牛啊,更透彻!
-
- 回复cannon0102:good,理解的非常好啊,受教了
-
Re:
迷雾forest 2015-10-09 14:59发表
-
Re:
zyz193 2015-03-19 21:21发表
-
Re:
zouxy09 2014-04-24 12:52发表
-
32楼
李博Garvin 2014-04-17 17:18发表
-
- 谢谢博主,学到很多
-
31楼
penergy 2014-04-11 22:16发表
-
-
zouxy09老师,
我仔细看了您的这篇文章,通过R语言模拟了你文章男女学生抽样的EM算法,但是效果不太好。问题在于求取Q(z)的过程中,男生类的身高均值很高,女生很低。自己感觉是由于两个正太分布重叠部分太多,导致分类不好。
总之,自己也不知道什么原因。您能不能解释一下,或者看了我的算法之后,如何改进E-step的分类问题。
这是我的帖子:
http://penergy.iteye.com/blog/2043921 -
-
回复penergy:你已经找到了问题所在,那两个分布重叠部分太多。
现实中多用于可以分类的数据。
-
Re:
期望最大化 2015-09-01 17:25发表
-
30楼
deanlan_sjtu 2014-04-06 19:51发表
-
- 写的浅显易懂,楼主真大牛。。。谢谢楼主。
-
29楼
whynot2412 2014-03-21 17:04发表
-
- 有瑕疵要指出一下。你说的样本应该是样本点,样本集才叫样本。猎人和同学打猎的例子,是贝叶斯先验的最好体现,而不是最大似然。
-
28楼
打破沙锅也要问到底 2014-03-12 17:12发表
-
-
膜拜大神!!!!
原来是这么个意思啊。。。。。。
本科学数学,研究生学计算机。
依然发现自己的数学功底相当薄弱,要补太多太多数学知识。
谢谢大神。这时我看过最好的文章。
我得方向和你的博文都差不多。
果断一篇一篇跟着你学过去
-
27楼
小白鸽 2014-03-12 16:07发表
-
-
我以前就是学数学的,但当时最大似然函数估计只会用,不知道干嘛的.
看了lz通俗易懂的解释,膜拜了.看到lz的文章才豁然开朗.
-
26楼
Elvin_C_L 2014-02-28 12:58发表
-
- 叹服,楼主这个EM是所有讲EM文章里面最通俗易懂的,很多文章都是学院派的,一大堆推导,晕乎其晕,楼主这个有例子,有推导,还有各种管用的口水话,更易于理解。。。顶楼主,多写好文啊
-
25楼
sharpstill 2014-02-09 17:46发表
-
- 说反了吧,f(x) = log x的二阶导数小于0,是凸函数啊,上凸函数,你这个文章里怎么写的凹函数
-
- 回复sharpstill:你把凸凹函数概念搞反了,同学
-
Re:
AceMa 2014-07-22 14:13发表
-
24楼
ahuang1900 2014-01-10 12:45发表
-
- 通俗易懂,假如能够举个例子,写点代码实现,应该会更好!
-
23楼
pymqq 2014-01-08 19:27发表
-
- 第三部分,【那我们也许会想,你就是多了一个未知的变量而已啊,我也可以分别对未知的θ和z分别求偏导,再令其等于0,求解出来不也一样吗?】这句话后面没有解释清楚为什么,是因为后面得到“对数的和”后方便求导了,但是此时不在是“等于”了,所以不能同时对未知的θ和z分别求偏导进行求解吗?非常感谢博主,同为研三,感觉自己好搓啊!我要加油!
-
22楼
yayatongnian 2014-01-08 10:00发表
-
- 大爱楼主的文章!真的很感谢这种用心的分享!
-
21楼
gjs0821 2013-12-30 06:49发表
-
- 写的太好了!
-
20楼
wei_chao_cui 2013-12-29 11:34发表
-
- Very Good!
-
19楼
痞子寇 2013-12-20 14:06发表
-
- 投了一票 (写的不错)
-
17楼
GO小胖 2013-12-17 14:24发表
-
- 写的真好
-
16楼
紫荆飘香V 2013-12-12 21:53发表
-
- 前几天在华工上机器学习课的时候,有同学推荐了你的博客,看了一下博主,原来也是华工的,好巧好巧啊。博主是读研几呢?
-
- 回复ahuang1900:哈哈,幸会幸会!研二了
-
Re:
zouxy09 2013-12-13 00:17发表
-
15楼
wang_xiaoke 2013-12-11 15:26发表
-
- 楼主在最大似然模块中,所说的样本集X={x1,x2,…,xN}其实应该称为样本,里面的每个xi为个体,N为样本容量。
-
- 回复wang_xiaoke:样本集实际上是样本的集合,里面包含的是N个样本。我觉得我的表述是没有问题的。
-
- 回复zouxy09:一次抽样过程得到是应该是一个样本,要得到一个样本集,需要将抽样过程重复N次。样本本身就是一个集合,里面包含了你的观测单元(样例)。严格来说,这种拦截式抽样是不属于概率抽样的。
-
- 回复zouxy09:你对样本的理解有误哦!
-
- 回复wang_xiaoke:哦哦,谢谢。我是按照平时机器学习那套来理解了。如果严格按照概率或者统计学来说的话,可能就像您说的这样吧。平时在表达机器学习的训练样本集和测试样本集,也是这么表达了,所以习惯了。哈哈
-
- 回复zouxy09:仔细看看可以发现,你给出的jerrylead的文章中也是将你所说的样本集定义为样本的。嘿嘿!
-
- 回复zouxy09:我之前对样本的理解和你是一样的,所以一直不明白,为什么paper中一般都把样本叫example。后来看了统计学中样本的定义,才发现这里的example是指样例,而样本sample则是example的集合。
-
Re:
zouxy09 2013-12-12 09:49发表
-
Re:
wang_xiaoke 2013-12-12 14:53发表
-
Re:
wang_xiaoke 2013-12-12 14:49发表
-
Re:
zouxy09 2013-12-12 15:05发表
-
Re:
wang_xiaoke 2013-12-12 15:20发表
-
Re:
wang_xiaoke 2013-12-12 15:16发表
-
14楼
Gcache 2013-10-30 16:17发表
-
- 看了你的博文,受益匪浅,Thanks!
-
13楼
小强茜茜 2013-09-15 17:37发表
-
- 讲的通俗易懂,看了2天的EM,还是这个看懂了,在看统计学习方法的证明就容易多了,谢楼主
-
12楼
系米 2013-07-20 15:32发表
-
- 写的通俗易懂,让我这样的菜鸟都看懂了,谢谢楼主!!
-
11楼
Crossi 2013-06-26 22:29发表
-
- 辛苦楼主了,讲的详细生动到位。
-
10楼
qykshr 2013-06-24 23:48发表
-
- 讲解的很生动,尤其是,做铺垫的那几个例子,受教了
-
9楼
hedabenniao 2013-06-12 15:07发表
-
- 感谢博主分享,谢谢
-
8楼
dvd_rom 2013-05-12 14:16发表
-
- 楼主讲的很好,受教了
-
7楼
v_JULY_v 2013-05-12 00:14发表
-
- 有这个想写成通俗风格的意识不错,可以继续写写其它算法:-)
-
- 回复v_JULY_v:呵呵,很高兴您逛到这里,您的博客让我很受用,也有很多的感触。非常感谢您!
-
Re:
zouxy09 2013-05-12 16:13发表
-
6楼
且听风雨999 2013-05-03 14:55发表
-
- 我也喜欢博主这种风格。话说我貌似比楼主口水话更多。顶博主
-
5楼
dxball2 2013-04-28 06:11发表
-
- 说的很好 深入浅出 文章排班也很好 赞一个
-
4楼
u010319374 2013-04-16 12:42发表
-
- 楼主的深度学习和em看完后真的很受益匪浅,特意注册个账号评论下,谢谢楼主!!!!!
-
- 回复u010319374:呵呵,非常感谢鼓励
-
Re:
zouxy09 2013-04-16 12:59发表
-
3楼
workerwu 2013-04-15 06:07发表
-
- 楼主列举的例子太形象生动了,赞一个。
-
2楼
ppn029012 2013-04-09 04:51发表
-
-
我觉得,文章的一开始就应该先说EM是什么...看了半天才说EM是expectation maximization...因为是缩写,最好在文章的一开始就稍微解释一下。
不过很喜欢这样的文章! 我也在努力学习博主风格,继续努力! -
- 回复ppn029012:呵呵,谢谢你的建议。以后会注意,欢迎交流
-
Re:
zouxy09 2013-04-09 12:20发表
-
1楼
blossomchina 2013-04-03 10:09发表
-
- 说的太好了,谢谢了
核心技术类目
- 个人资料
-
- 访问:6824138次
- 积分:27017
- 等级:
- 排名:第166名
- 原创:116篇
- 转载:11篇
- 译文:1篇
- 评论:3594条
- 个人简介
-
关注:机器学习、计算机视觉、人机交互和人工智能等领域。
邮箱:zouxy09@qq.com
微博: Erik-zou
交流请发邮件,不怎么看博客私信^-^
- 相关资料与课程推荐
- 文章搜索
- 文章分类
- 阅读排行
- (557312)
- (399686)
- (379722)
- (245266)
- (242266)
- (213704)
- (203322)
- (194432)
- (190612)
- (173727)
- 评论排行
- (266)
- (174)
- (172)
- (165)
- (138)
- (120)
- (95)
- (86)
- (81)
- (70)
- 最新评论
-
: 博主,真大神,代码写的很棒
-
: 楼主,我的运行错误如下Undefined function 'sigm' for input arg...
-
: 你好,我遇到同样的问题,你怎么解决的?谢谢
-
: 此算法的个人觉得不好,第一,跟踪效果,如果运动目标速度过快根本跟踪不上,第二,时间350fps跟踪的...
-
: 非常赞,适合初学者学习
-
: @qicongsheng:这位同学你连个毛线都写不出来你信不信
-
: 博主写的非常好,狂赞一个!
-
: 楼主有没有计算机图形学关于三维重建的资料,现在在学,但不知道,从何下手?
-
: 我想知道那个β到底是什么?通过卷积之后的特征图还要乘以这个β再加上偏置常量b然后再输入激活函数吗?在...
-
: 我想知道那个β到底是什么?通过卷积之后的特征图还要乘以这个β再加上偏置常量b然后再输入激活函数吗?在...


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









