






请点击上方“AI公园”,关注公众号
在之前的DocFace和DocFace+的论文中,反复提到了imprinting,我们今天就来看看,imprinting究竟是个什么东西,反正我理解就是用样本的特征来当做分类器对应类别的权值。
摘要:人类的视觉可以在见过几个训练样本之后,立刻识别出新的类别。我们描述了如何从少量样本的训练中通过直接设置最后一层的权重为卷积神经网络分类器增加一个类似的能力。我们把这个过程叫做权值imprinting,就是通过对训练样本的激活值做一个合适的缩放,直接为新的类别设置合适的权重。Imprinting的操作为梯度下降训练提供了一个重要的补充,因为他可以提供一个直接的好的分类能力以及一个用于未来finetune的初始化值。我们展示了imprinting是如何和基于代理的嵌入关联起来的。然而,这个与为每个新的类别学习单个的imprinting权值向量是不同的,和典型的嵌入方法基于最近邻距离来训练样本不同的。我们的实验表明,使用imprinting权值的瓶颈要比使用最近邻实例的嵌入的方法表现要好。
1. 介绍
深度学习虽然通过几百万样本的训练时候,能够在一些大型的数据集上超越人类的表现,但是对小样本的扩展能力却有限,这就是小样本学习的问题。嵌入方法是一个天然适合的方法,新的类别可以通过将样本送入到CNN网络中,然后通过最近邻的方法得到结果。这个在语义的嵌入表示中已经实现了,倒数第二层的激活值可以看做是一个嵌入向量,这个和我们的这篇文章有一定的关系。CNN是获取好的性能的一个推荐的方法,而softmax的损失的训练要比嵌入的方法如triplet的方法要快。
在本文中,我们尝试将CNN分类器和嵌入方法的优点结合起来来处理小样本的学习问题,受到将嵌入当做是物体类别的代理的启发,我们认为在CNN分类器中,嵌入向量可以有效的和最后一层的权值相比。我们的方法,叫做imprinting,是将训练时样本得到的激活值进行合适的缩放,将其当做新的类别的权值向量,而其他的权值向量保持不变。这个还可以扩展成使用多个样本的激活值向量的平均值作为权值。通过我们的实验,我们发现这种方法要比最近邻的方法要更好。
我们考虑这样一个小样本学习的场景,我们有一个在大量样本上训练得到的初始的分类器,需要到新的类别上使用,每个类别只有很少的几张图片。目标是,希望能在这个组合起来的数据集上表现的很好。这个设置和人类的持续学习新的概念的识别场景一样。
已有的一些方法无法使用在一些有限资源的场景中,如移动设备。因为重新训练增加了类别的模型需要一段比较长的时间。而语义的嵌入方法能够立即记住新的样本,并且使用它们进行识别,不需要重新训练。但是,语义嵌入难以学习,因为需要计算量很大的难样本挖掘,在测试的时候也需要存储所有的嵌入向量进行最近邻的比较。
我们表明了imprinted权值可以在小样本的情况下通过新的样本进行即时的学习。更进一步,既然imprinting之后的模型的参数形式和之前是一样的,以后有了更多的样本还可以进行finetune。实验表明,imprinting的方法比随机初始化的方法提供一个更好的初始化值,而且最后finetune之后,也能得到更好的结果。
2. 相关的工作
度量学习 度量学习在识别新的人脸中应用很成功。主要思想是,对人脸图像进行映射,在映射后的空间中,相同的人的图像距离很近,而不同的人的图像距离很远。映射学习好之后,在测试阶段,使用最近邻的方法进行检索,识别训练中没有的人脸类别。
对比损失,最小化相同类别之间的样本的距离,同时将不同类别之间距离拉大。相比于最小化绝对距离,最近的方法集中在相对距离上。FaceNet优化triplet的损失,使用了在线难样本挖掘的方法来组成minibatch。Magnet损失通过对样本进行k-means聚类,通过类的中心来表达该类别,从而优化不同类别的分布。Lifted structure损失在一个minibatch中组成所有的成对样本的关系来代替triplet。N-pair损失需要每个batch中的样本来自于N个不同的类别。所有的这些方法都需要一些在线的或者离线的batch的生成过程。
Proxy-NCA损失通过将可训练的代理赋值给每个类别从而不需要batch的生成,加快了收敛。NormalFace也提出了相似的想法,使用的是特征向量的归一化。嵌入向量可以用来泛化表示没有见过的类别,但是在测试的时候需要存储所有的需要进行比较的向量。在我们的工作中,我们保留了原来的CNN的参数形式,表明了嵌入向量可以用来imprinting最后一层的权值。从结果看,我们的方法具有所有的CNN方法训练时的优点,在测试的时候,也不需要存储所有的嵌入向量。
单样本和少样本学习 单样本或者小样本学习指的是使用只有1个或很少的几个样本进行训练。连体网络通过两个网络提取特征,对特征进行相似度的得分计算。匹配学习了一个神经网络,可以将一个没有见过的类别映射到一个小的支持集中的图片,得到他的类别。原型网络使用几个新的样本的嵌入的均值作为原型。这些方法将小样本学习变成使用一个支持数据集对几个没有见过的类别进行分类。在测试的时候,测试图片和支持数据集必须同时提供。但是,这个方式和人类的学习方式是不一样的,人类是当遇到新的样本的时候不断的学习新的类别。相比之下,我们考虑另外的设定,我们聚焦于一个整体的表现,包括一个大量样本的数据集和一个新的类别的少样本的数据集。Hariharan和Girshick训练了一个多层的感知机,通过和已有的样本进行类比从单个样本中生成了额外的特征向量。他们的方法保留了最后的线性分类层,我们的方法可以直接的在新的类别上得到提升而不需要重新训练。还有和我们的工作类似的工作,从激活值中训练预测的参数。但是,我们的方法直接从激活值imprints权重,这个可以修改结构加入一个归一化层。
3. 度量学习和Softmax分类器
这部分,我们讨论了在嵌入训练中使用基于代理的目标和softmax交叉熵的损失之间的关系。基于这些观察,我们通过扩展CNN的分类器到新的类别来介绍我们的方法。
3.1 基于代理的嵌入学习
最近的工作已经模糊了基于triplet的嵌入学习和softmax分类。例如,最近邻分量分析使用类似softmax的loss学习了一个距离度量。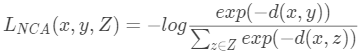
这个式子使得具有相同的label的点x,y比具有不同label的样本z更加靠近。使用的距离度量是欧式距离。Movshovitz-Attias 通过代理p(·)作为类别的标签来训练样本。

这种方式比triplet的方法收敛更快。
3.2 和Softmax分类器的联系
我们将讨论度量学习和softmax分类器之间的联系。我们考虑一个类别只有一个代理,而且这个代理由这个数据点的标签决定。具体的,设类别的样本标签是C, 为可训练的代理,那么,每个点x的代理为
为可训练的代理,那么,每个点x的代理为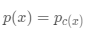 ,其中c(x)表示x的标签值,我们认为代理
,其中c(x)表示x的标签值,我们认为代理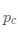 可以类比softmax分类器中的权值向量
可以类比softmax分类器中的权值向量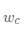 。
。
我们假设数据点向量和代理向量都归一化到同样的长度,这样的话,最小化欧式距离就等效于最大化内积也等效与余弦相似度。用内积来取代余弦距离的话,loss可以写成: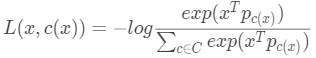
对比softmax的交叉熵的loss: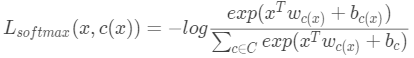
其中所有的偏置项b=0。
4. Imprinting
有了上面的归一化之后的特征向量和权值向量的相似性的讨论之后,感觉我们可以自然的用单个样本的特征向量来代替新的类别的权值向量。下面,我们会概述一下这个方法,叫做imprinting(铭记)。本质上,imprinting利用了归一化的特征向量和权值向量的对称性,复制了新样本的嵌入激活作为新的分类器的权值。
为了展示这个方法,我们聚焦于使用一个两步的小样本学习的方法,先在一个有大量样本的数据集中训练一个基础模型,然后在新的只有几个样本的数据集上不断的增长分类的能力。
4.1 模型结构
我们的模型包括两个部分,一个部分是将图像映射到一个向量空间,和标准的CNN不同的地方在于,我们在后面加了一个L2的归一化,第二步,使用softmax分类器将嵌入特征映射成一个没有归一化的logit的分数,然后再通过一个softmax的激活层,得到每一个类别的概率。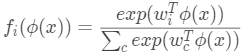
其中,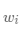 是归一化之后的权值矩阵的第i列,在这层中,没有偏置项。
是归一化之后的权值矩阵的第i列,在这层中,没有偏置项。
我们将权值矩阵的每一列看做是对应类别的模板。在前向传播中,我们输入一张图像,得到这个图像的嵌入特征向量,然后再和权值矩阵中的每一列做内积,这个结果等效于在嵌入空间中用最近邻的方式找一个类别的模板。
相比于非参数的最近邻模型,我们的分类器只需要为每个类别存储一个模板,而不需要存储大量的参考样本数据。
归一化 在我们的模型中,权值和嵌入特征的归一化是非常重要的部分。从几何上看,归一化的嵌入和权值都在一个高维的单位球上。相比之下,已有的DNN通常将minibatch中的激活值强制调整到零均值,单位方差,DNN并不会处理激活值和权值之间尺度上的差别。在我们的模型中,由于我们将特征和权值都做了归一化,向量的幅值并不会影响预测的结果,因为向量之间的角度是固定的。
缩放因子 余弦相似度wi>φ(x) ∈ [-1; 1]可以防止当使用softmax的激活之后,归一化的正确类别的概率接近1。例如,考虑对于一个输入x,正确的类别内积输出1,错误的类别内积输出-1,那么,假设有100个类别,C=100,归一化的概率为 ,这样的话,很难给出一个接近one-hot编码的分布,从而会产生一个很大的loss的下界。当类别的数量变大的时候,这种现象越发严重。为了避免这个问题,我们在模型中加入了缩放因子:
,这样的话,很难给出一个接近one-hot编码的分布,从而会产生一个很大的loss的下界。当类别的数量变大的时候,这种现象越发严重。为了避免这个问题,我们在模型中加入了缩放因子: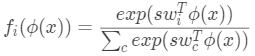
我们也尝试过使用自适应的缩放因子,但是并没有什么准确率的提升,所以还是使用固定的全局的缩放因子。
总的来说,我们的模型和标准的DNN模型是一样的,只有两个区别,一个是最后的分类器的特征和权值进行了归一化,这样我们可以认为他们是等效的。第二个就是对内积进行了缩放,这样训练起来和原来的标准的DNN是一样的。下面我们将说明,如何为这个分类器添加新的类别。
4.2 权值imprinting
我们的目的是,直接设置新的类别的权值,考虑一个新的类别的样本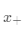 ,我们的方法是计算这个样本的映射之后的向量φ(x),然后用这个向量作为新的类别的权值向量
,我们的方法是计算这个样本的映射之后的向量φ(x),然后用这个向量作为新的类别的权值向量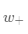 ,下图显示了如何用这种方法为分类器增加新的类别。
,下图显示了如何用这种方法为分类器增加新的类别。
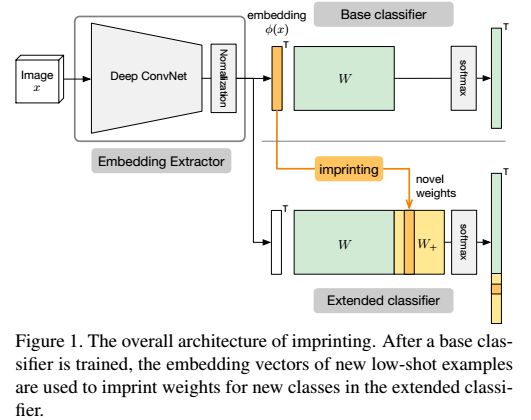
直觉上,我们可以认为是imprinting的操作记忆了新的类别的样本作为新的样本的模板。下图显示了新的权值imprinted之后,决策边界的变换情况。这样做的一个假设就是,测试用的新的类别的图像和训练样本中的新的类别的图像是很接近的。这个和triplet的性质是很相似的。
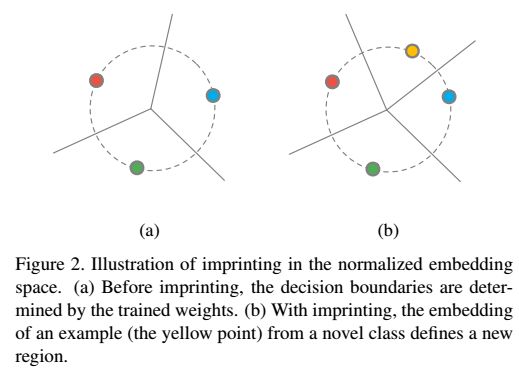
对嵌入做平均 如果有超过1个的样本在新的类别中,我们可以通过求平均值的方法来设置新的权值。实际操作的时候,也可以对原有的少样本做随机的增强之后,再取平均。
Finetune 我们的模型和原来的DNN模型具有相同的形式,因此,在做完权值的imprinting之后,我们还可以进行finetune,使用平均值的方法保证了我们的新的类别中的样本在嵌入空间的分布是一个单峰的分布。这个可能并不是所有的新的类别都是这样,因为我们学到的嵌入的表示是可能有偏差的。但是,经过finetune之后,新的类别将具有单峰分布的性质。
5. 实现细节
我们的模型使用imageNet进行预训练,使用了InceptionV1的结构,用来产生嵌入的全连接层的参数是随机初始化的。权值向量和特征向量都进行了L2的归一化。输入图像缩放为256x256,然后随机crop到224x224,然后归一化到[-1, 1],在训练的时候,进行随机的镜像,对于预训练的层,学习率设为0.0001,随机初始化的层的学习率为预训练层的学习率的10倍。我们的学习率指数下降,下降率为每4个epoch下降为原来的0.94,使用RMSProp优化器,动量设为0.9,测试的时候,图像进行中心crop。
6. 实验
6.1 数据集划分
CUB-200-2011 数据集包括200个不同类别的鸟,11788张图片,我们使用了数据集自己的训练集合测试集的划分。另外,我们将前面的100个类别作为基础的类别(每个类别平均30张图片),训练一个分类器,剩下的100个类别作为新的类别,每个类别有n张图像,我们做实验的时候,使用了不同的n=1,2,5,10,20。在测试的时候,原始的测试集划分里面包括了原来的100个类别后新的100个类别,我们使用所有类别的top-1的准确率来评估。我们还展示了新的类别的准确率。
6.2 模型和设置的变化
Imprinting 我们通过直接设置权值的方式来获取imprinted之后的模型,当新的类别中有超过一张图像时,我们将所有图像的特征做归一化之后再平均。基本的设置是使用新样本的原始形式,另外的方法是使用增强之后的图像,先做5个增强,包括镜像和随机的crop,然后再对嵌入向量取平均。这些只需要在前向的时候做就可以了,不需要额外的训练。我们将这些imprinting的变换和随机初始化新的类别的权值不进行finetune的方式进行对比。
Finetune imprinted权值可以作为finetune的初始化的值,我们对imprinted之后的模型进行了finetune,然后和随机初始化的模型进行finetune进行了对比,我们只用了新的类别中的少量样本来进行finetune,由于所有类别的样本的数量是不均衡的,我们对新的类别进行了过采样,随机的增强也用到了。
联合训练DNN分类器 为了进行对比,我们训练了一个分类器,使用了所有的类别,这个模型没有对权值和嵌入进行归一化。
其他的小样本学习方法 我们也使用了特征生成网络和匹配网络来进行对比。
6.3 结果
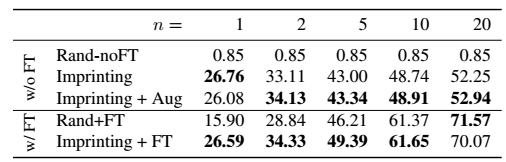
表1显示了新的100类的的top-1的准确率,可以看到Imprinting的方法在没有finetune的时候,能够很好的给出一个权值的估计值,使用了图像的增强,提升并不是很多。对于finetune之后表现,使用了Imprinting作为初始化值仍然表现最好,最后两行表示了和其他方法的对比。
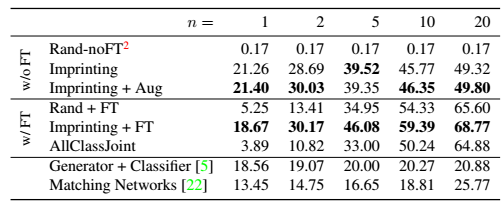
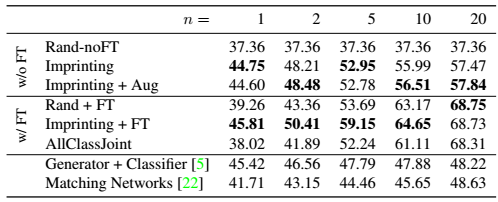
表2显示了所有的200类的top-1的准确率。
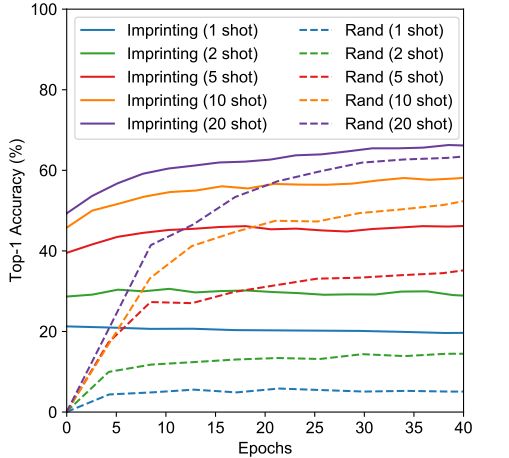
从训练曲线上来看,使用了Imprinting作为初始值来进行finetune的时候,收敛的更快,准确率也更高。
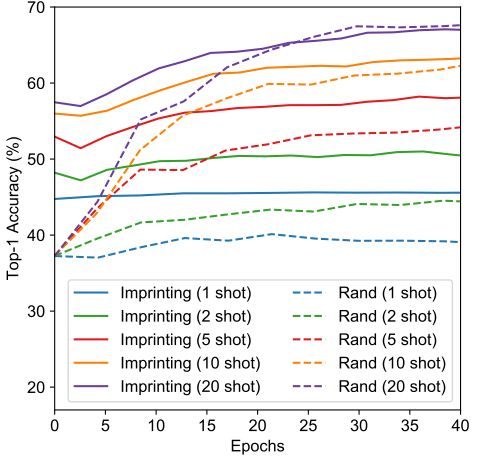
利用imprinted权值迁移学习 表3显示的是使用imprinted之后的权值进行迁移学习的情况,也就是只训练新的100个类别,测试新的100个类别的top-1的准确率。可以看到,在样本数很少的时候,n=1,2,5的时候,使用imprinting显示出了很大的优势,随着n的增大,两者的效果基本相当。
和最近邻方法对比 在度量学习中,常常使用的方法是最近邻法,我们也和最近邻法进行了对比,当每个新的类别只有一个样本的时候,n=1,imprinted分类器和最近邻法是等效的,当n>1的时候,imprinted分类器还和原来一样,而最近邻法需要存储的大小是随着n线性增长的。
从图6中可以看到,使用平均的嵌入要比存储所有的嵌入向量的效果要好,
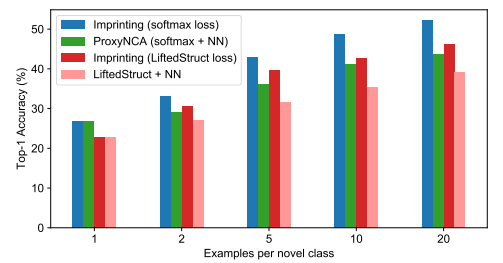
和Lifted Structured Loss对比 Lifted Structured Loss是一种triplet loss的泛化的版本,从上图中可以看到,我们的imprinted方法和ProxyNCA的方法都比Lifted Structure的方法要好。在Lifted Structured Loss上使用imprinting,也能有收益。
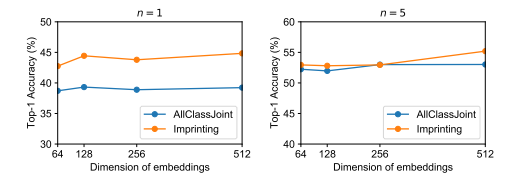
嵌入维度 我们在实验中使用的维度是64,我们还实验了其他的维度D=64,128,256,512,维度的提升并没有带来能力的提升。见图7.
本文提出了一种新的方法,权值imprinting,直接为新的类别设置分类器的权值。这是梯度下降的一个很好的补充,可以很好的用在新的类别上面。对原有的网络结构的修改就是需要对分类器的权值和嵌入向量做一个归一化,然后再最内积进行缩放。然后直接使用新的类别的样本的均值向量作为新的样本的权值向量。实验表明,我们的方法要比最近邻的方法表现要好。
本文可以任意转载,转载时请注明作者及原文地址。

请长按或扫描二维码关注我们















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









