







 本文介绍了一个使用RNN进行二进制序列预测的问题,其中输入序列X与输出序列Y之间存在特定时间步的依赖关系。通过计算交叉熵评估RNN是否学习到这些依赖,并详细解释了模型的内部工作原理,包括状态转移和输出计算。文章还讨论了不同学习情况下的交叉熵期望值,并展示了如何将模型转化为TensorFlow API的实现。
本文介绍了一个使用RNN进行二进制序列预测的问题,其中输入序列X与输出序列Y之间存在特定时间步的依赖关系。通过计算交叉熵评估RNN是否学习到这些依赖,并详细解释了模型的内部工作原理,包括状态转移和输出计算。文章还讨论了不同学习情况下的交叉熵期望值,并展示了如何将模型转化为TensorFlow API的实现。
Part 1
在本文中,我们会构造一个RNN接受一个二进制的X序列输入,来预测一个二进制序列Y输出。序列按如下方式构造:
输入序列X : 在时间步t, Xt有一半的几率为0,另一半几率为1,X可能是[1,0,0,1,1,...].
输出序列Y : 在时间步t,Yt有50%的几率为0,另一半几率为1。
- 如果X(t-3)是1,那么Yt为1的几率增加50%;
- 如果X(t-8)是1,那么Yt为1的几率减少25%;
- 如果X(t-3)和X(t-8)同时为1,那么Y(t)为1的几率是50%+50%-25%=75%.
因此,数据中存在两个依赖:t-3和t-8。
可以通过计算出交叉熵,来判断RNN是否学习到了这两个依赖。
- 如果没有学习到依赖性,那么有62.5%的几率为1,交叉熵应该是0.66.
- 如果仅仅学习到了t-3的依赖,交叉熵应该是0.52
- 如果两个依赖都学习到了,交叉熵应该是0.45
下面是计算公式:
import numpy as np
print("Expected cross entropy loss if the model:")
print("- learns neither dependency:", -(0.625 * np.log(0.625) +
0.375 * np.log(0.375)))
# Learns first dependency only ==> 0.51916669970720941
print("- learns first dependency: ",
-0.5 * (0.875 * np.log(0.875) + 0.125 * np.log(0.125))
-0.5 * (0.625 * np.log(0.625) + 0.375 * np.log(0.375)))
print("- learns both dependencies: ", -0.50 * (0.75 * np.log(0.75) + 0.25 * np.log(0.25))
- 0.25 * (2 * 0.50 * np.log (0.50)) - 0.25 * (0))Expected cross entropy loss if the model:
- learns neither dependency: 0.661563238158
- learns first dependency: 0.519166699707
- learns both dependencies: 0.454454367449
输出一个状态向量St, 和一个预测的概率分布向量Pt, 以拟合二进制的输出序列Yt向量。
St = tanh(W (Xt @ St-1)+ bs)
Pt = softmax(U*St + bp)
@代表向量的连接操作
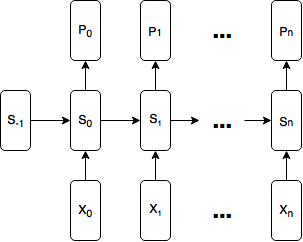
为了建立一个tensorflow的模型,首先你得把模型表示成一个图,然后执行这个图。
关键的问题是,图有多宽?我们的图一次接受多少time steps的输入?
每一个time step都是重复的,G代表了一个时间步:G(Xt,St-1) -> (Pt,St)。
我们可以每一个时间步就执行一次图。这样对一个已经训练好的模型来说是有效的,但问题是训练的过程:
在反向传播时梯度的计算是以图上限的。我们只能反向传播误差到现在的时间步,不能传播这个误差到上一个时间步。
这就意味着我们的网络无法学习到长期的依赖条件。
一个选择是,我们可以使我们的图和数据序列的长度一样宽,这样做通常是有效的(除非输入序列任意长)。如果说我们的
序列接收长度为10000的序列,来自第9999步的误差被一路传播到时间步o上。这样的计算代价非常
昂贵,不仅低效而且存在梯度消失、爆炸的问题。(将误差反向传播很多时间步通过会引起梯度消失、爆炸问题,这可以通过链式
求导的公式就可以简单理解)
一个常用的应对长序列的办法是
"截断"我们的反向传播,以一个最大步数的限制来反向传播误差。我们选择n作为模型超参数,记住
一个权衡法则:
越大的n可以捕捉越长期的依赖关系,但是计算代价也会
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2487
2487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









