










WAE(Wavelet-like Auto-Encoder) 是由来自中大、哈工大、桂电等多机构的多名研究人员合作提出的,发表于AAAI-2018(论文地址:
https://arxiv.org/pdf/1712.07493.pdf
创新点:
1. WAE借助小波分解得思想,将原图分解成两个低分辨率图像,以达到网络加速的目。
(PS:整体思路:下采样的方法达到网络加速,但是下采样会导致的信息损失而降低网络性能,因此需要一种既能降低图像分辨率,又不损失信息的方法。于是小波分解闪亮登场,WAE将原图分解成两个低分辨率图像,一个携带高频信息,一个携带低频信息,具体操作往下看 )
感觉这个idea还是挺有意思的,值得学习
———————————————-分割线—————————-
网络框架
WAE整体框架如下:

输入图片I ,经过encoder 得到IH(高频图)和IL(低频图),低频图输入到标准的CNN网络得到的特征与高频图融合(PS:高频图并不是像图中那样直接到fusion处的,而是与低频图一样,也要输入到一个CNN里面,具体请往下看),最后分类。
目标函数
目标函数比较复杂,得仔细讲讲,具体训练阶段分为三个部分,
1.auto-encoder的训练
2. 分类器的训练
3. 整体加起来训练 (PS: 思想和2016-ICML的一篇paper相同)
先看1.Auto-encoder主要是看重构误差,即:
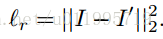
由于要获得“高频图”,还需要增加一个约束,用以约束其中一个特征图的像素值的大小:
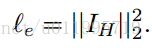
auto-encoder训练整体的loss 为:
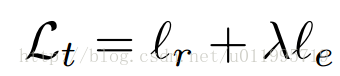
lr表示重构,le表示高频图的约束,λ是超参,用以权衡这两个loss
分类器的训练,这个没啥好说的:
3.整体训练的loss:
其中γ设置为0.001,用以权衡两个loss,Lc是分类的loss,Lt是训练auto-encoder的loss
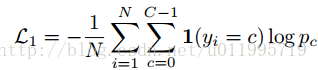
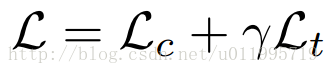
细节处理
知道了框架和目标函数,但是细节是如何处理的呢:
1. Encoding layer 是如何将I分解成低分辨率的高频图和低频图呢?
2. IL经过网络输出的特征如何与IH融合呢?
3. Decoding layer 是如何将IL和IH恢复的呢?
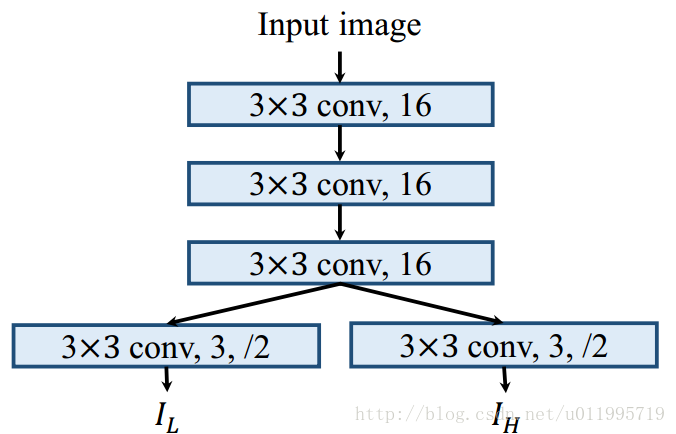
先看 1. Encoding layer 是如何将I分解成低分辨率的高频图和低频图呢?
WAE的Encoding layer采用卷积神经网络将I“分解”成低分辨率的高频图和低频图,卷积神经网路如下图所示,先用3层卷积核大小为3*3,数量为16的卷积层对原始图片进行卷积,之后分别采用两个卷积层进行卷积,再来一个下采样,得到分辨率为原始图片的1/2。具体网络如下图:
看到这里,我把分解改为了“分解”,用CNN获得两个图片,那么如何保证一个是高频,一个是低频呢?
论文是这样做的: 首先我们要肯定的是,通过CNN我们是不能得到一张是高频信息图,一张是低频信息图。作者这里采用的方式是,对其中一个图增加约束,即增加一个L2范数的约束,使得其中一张图的值都很小,然后这张图就是高频信息,从而对应的另外一张图就是低频信息。 (有熟悉信号处理的同学么?? 请问这个理论是小波分解的理论还是信号处理的理论?
增加的约束是这个:
对图像像素值的大小进行限制,一张图像的素值小,就称之为高频信息图,请问这个是否有理论根据? 知道的朋友请在评论区讨论讨论
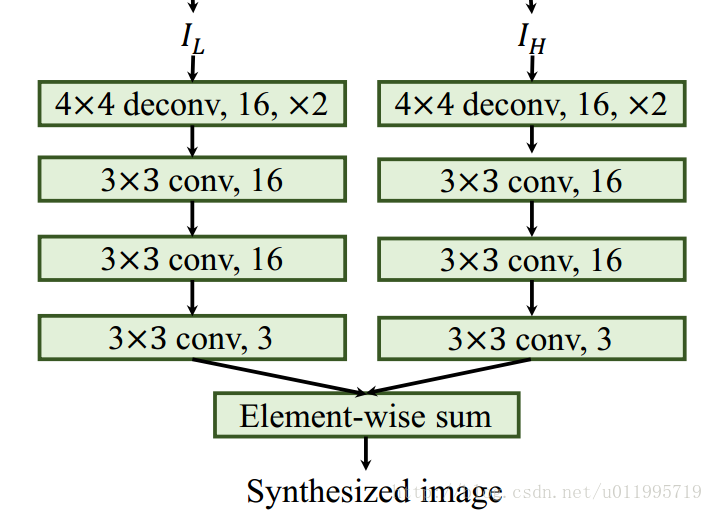
说完了encoding,接着说decoding。 3 . Decoding layer 是如何将IL和IH恢复的呢?
Decoding layer没啥好讲,知道了如何Encoder,所有步骤反过来就好了,具体操作如下图所示。
最后看问题2. IL经过网络输出的特征如何与IH融合呢?
如果只看开篇的WAE框架图,那肯定是理解不了 IH那条虚线直接到fusion到底做了什么操作!
看了prototxt才明白,原来是这样,具体如下图所示:
先看左半部分,IH和IL分别经过一个VGG的卷积部分,得出特征FH,FL;
右半部分 分为上下,先说上边,FH和FL进行“融合”,也就是按通道concat,然后输入FC层,得出一个1000维的向量 V1;
下边,FL直接输入到FC层得到向量V2;
最终的网络分类输入是 V1+V2(element-wise)

回答了以上三个问题,WAE网络的结构已经很清晰了,但是还是存在不少疑问的:
如何确定经过Encoding layer之后得到的两张图,一个是高频图,一个是低频图?
图片经过encoding layer ,之后还要经过两个VGG,参数确实是少了,但是创新点上,怎么感觉是单纯的CNN的堆叠。有点像inception的思想,原始图片分成两个通道,然后输入到两个CNN,再把输出进行相加。
- 至于auto-encoder,我一直存在疑问,怎么能说明 经过encoder得到的特征(code)再经过decoder得出来的图像和原始图像很接近,就可以证明 这个encoder提取出来的特征(code)是好的!?
我一直认为是因为decoder的“恢复”能力很强,可以恢复出原始图像,也就是说 decoder已经“学习”到encoder是如何“编码”的,decoder就可以很好的恢复原始图像,有decoder这一层因素在这,怎么就能说encoder提取出的特征(code)就是好的呢?
胡思乱想:
又是一篇用了 auto-encoder 来“约束”卷积神经网络提取出的特征。
虽然是 wavelet-like ,但是小波的思想在论文中没具体提到呢。。。
目前,从这篇paper没有啥启发~















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









