










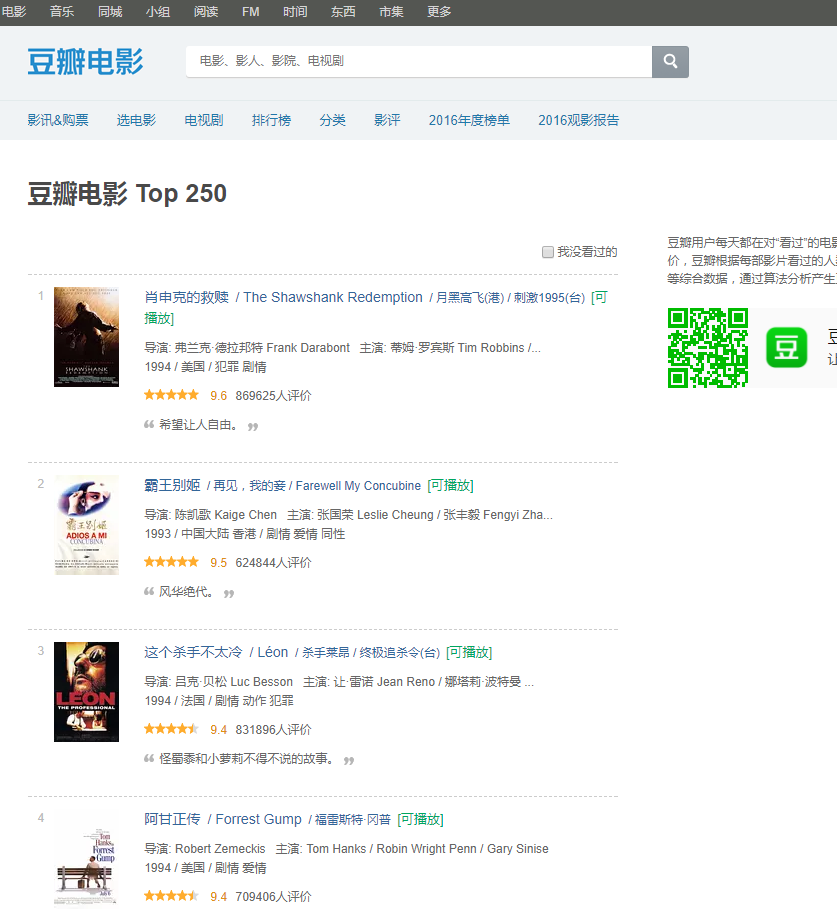
我们需要的信息是电影的序号、电影的名字,因此直接按上一节的方法查看网页代码,解析网页结构,提取我们所需要的信息,完成代码如下:
# coding = utf-8
import re
from urllib import request
from urllib import error
class DouBanSpider(object):
'''
本类主要用于抓取豆瓣中的电影
Attributes:
page: 表示当前所处理的页面
cur_url: 表示当前准备抓取页面的url
datas: 存储处理好的电影名称
_top_num: 用于记录当前的top号码
'''
def __init__(self):
self.page = 1
self.cur_url = 'http://movie.douban.com/top250?start={page}&filter=&type='
self.datas = []
self._top_num = 1
print("开始工作……")
def get_page(self, cur_page):
'''
param cur_page: 表示当前处理页
return: 返回抓取到的整个页面的HTML(unicode编码)
'''
url = self.cur_url
try:
# 因为一个页面有25部电影,所以这里 “* 25”
page = request.urlopen(url.format(page=(cur_page - 1) * 25)).read().decode("utf-8")
except error.URLError as e:
if hasattr(e, 'code'):
print("HTTPError: the server couldn`t deal with the request")
print("Error code: %s" % e.code)
elif hasattr(e, 'reason'):
print("URLError: failed to reach the server")
print("Reason : %s" % e.reason)
return page
def find_title(self, page):
'''
param page: 当前解析的HTML网页,找到电影排序号及电影名称
return: 返回
'''
tmp_data = []
movie_items = re.findall(r'<span.*?class="title">(.*?)</span>', page, re.S)
for index, item in enumerate(movie_items):
if item.find(" ") == -1:
tmp_data.append("Top" + str(self._top_num) + " " + item)
self._top_num += 1
self.datas.extend(tmp_data)
def start_spider(self):
# 爬虫入口
while self.page <= 5:
page = self.get_page(self.page)
self.find_title(page)
self.page += 1
def main():
# 程序入口
spider = DouBanSpider()
spider.start_spider()
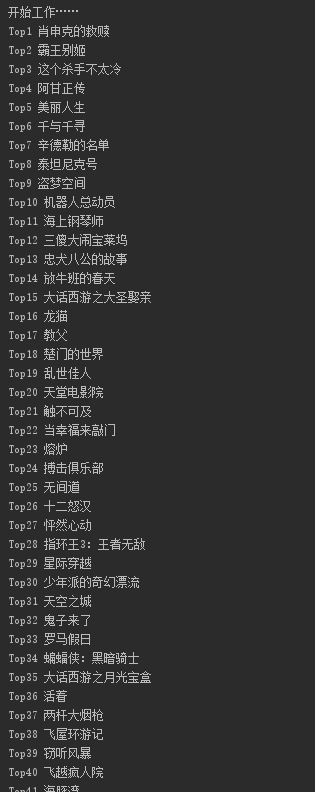
for item in spider.datas:
print(item)
if __name__ == '__main__':
main()















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









