









const/volatile关键字
const表示常量,较简单的用法就是定义程序的数字、字符串常量、代替宏定义等,例如
const int MAX_LEN = 1024;
const std::string NAME = "meto";从C++程序生命周期的角度来看,我们就会发现它和宏定义还是本质区别的:
const定义的常量在预处理阶段并不存在,直到运行阶段才出现。它叫只读变量更合适。
既然它是变量,那么使用指针获取地址,再强制写入也是可以的,但这种做法破坏了常量性,绝对不提倡。下面一个具有示范性质的实验:
const volatile int MAX_LEN = 1024; //需要加上volatile修饰,运行才能看到效果
auto ptr = const_cast<int*>(&MAX_LEN); //强制类型转换,去除常量性
*ptr = 2048;
cout << MAX_LEN << endl; //输出2048如果没有volatile,那么即使使用指针得到了常量的地址,并且尝试进行了各种修改,输出的仍然是常数1024.
const的使用方法
1.基本用法
int x = 100;
const int &rx = x; //常量引用
const int *px = &x; //常量指针"const &"成为“万能引用”,也就是它可以引用任何类型,不管是值、指针、左引用还是右引用。
string name = "test";
const string *ps1 = &name;
*ps1 = "spiderman"; //错误,不允许修改
string* const ps2 = &name; //指向变量,但指针本身不能修改
*ps2 = "spiderman"; //可以修改
const string* const ps3 = &name; //指向常量的常指针C++17新增了std::as_const(),可以无条件的把变量转换为常量引用。
因为std::as_const()返回的是引用类型,所以如果要使用类型推导就最好用auto&&或者decltype(auto)的形式,以保证推导出正确的类型。例如:
decltype(auto) s = std::as_count(name); //获取常量引用
const高级用法
class DemoClass final
{
private:
const long MAX_SIZE = 256; //const成员变量
int m_value = 100; //非const成员变量
public:
int get_value() const //const成员函数
{
return m_value;
}
void incr() //非const成员函数
{
m_value++;
}
};const函数成员含义是函数的执行过程是常量类型的,不会修改对象的状态(成员变量),也就是说,成员函数执行的是“只读操作”。编译器会检查const对象相关的代码,如果不是const成员函数,就不允许调用。
DemoClass obj;
auto&& cobj = std::as_const(obj); //对变量的const引用
cout << cobj.get_value() << endl; //调用const成员函数,正常
std::as_const(obj).incr(); //调用非const成员函数,编译不通过mutable关键字
mutable只能修饰类定义里面的成员变量,表示变量即使在const对象里也可以被修改。 允许const成员函数改写标记为mutable的成员变量。
用到的地方:对象内部用到了一个mutex来保证线程安全,有一个缓冲区来暂存数据,有一个原子变量来引用计数,这些都属于内部的隐私实现细节,外面看不到,变与不变不会改变外界看到的常量性,对于这些有特殊作用的成员变量,我们可以给它加上mutable,解除const的限制,让任何成员可以操作它。
class DemoClass final
{
private:
using mutex_type = int; //仅作为示例
mutable mutex_type m_mutex; //标记为mutable的成员变量
int m_value;
public:
void save_data() const
{
m_mutex++; //只可以修改标记为mutable的成员变量
m_value++; //修改其他会导致编译错误
}
}mutable不能乱用,太多的mutable让对象总处于变化状态,要少用、慎用。
constexpr关键字
constexpr用来实现真正编译期常量。
任何表达式、函数只要带上它,就会具有编译期常量的特性。能够用于编译期计算。例如:
constexptr int MAX = 100;
constexptr long mega_bits() //编译期常量函数
{
return 1024 * 1024;
}
array<int, MAX> arr = {0}; //编译期常量,可用于模板参数
assert(arr.size() == 100);
static_assert(mega_bits() == 1024 * 1024); //编译期常量,可用于静态断言
bitset<mega_bits()> bits; //编译期常量,可用于模板参数对于表达式,基本的要求不能含有运行时语法元素,不能是string/vector等需要运行时动态分配内存的复杂类型,通常只能是整数、字符串等字面量,而array因为能够在编译期确定长度,是可以引用constexpr的:
constexpr auto val = 100; //编译期整数常量
constexpr auto str = "hello"; //编译期字符串常量
constexpr array<int, 3> arr{1,2,3}; //编译期数组常量
constexpr vector<int> vec; //编译错误
constexpr string s = "str"; //编译错误
constexpr map<int, int> m; //编译错误常量引用、常量指针、常量函数总结(尽可能多用const,让代码更安全):
| const | 非const | |
|---|---|---|
| 对象(实例) | (const T) 对象只读,只能调用const成员函数 | 可以修改对象,调用任意成员函数 |
| 引用 | (const T&) 引用的对象只读,只能调用const成员函数 | |
| 指针 | (const T*) 指针指向的对象只读,只能调用const成员函数 | |
| 成员函数 | (func() const) 只能修改mutable成员变量,其他不允许修改 | 可以修改任意成员变量 |
异常的用法
try
{
int n = read_data(fd, ...); //读取数据,可能抛出异常
...
}
catch(...)
{
... //集中处理各种错误情况
}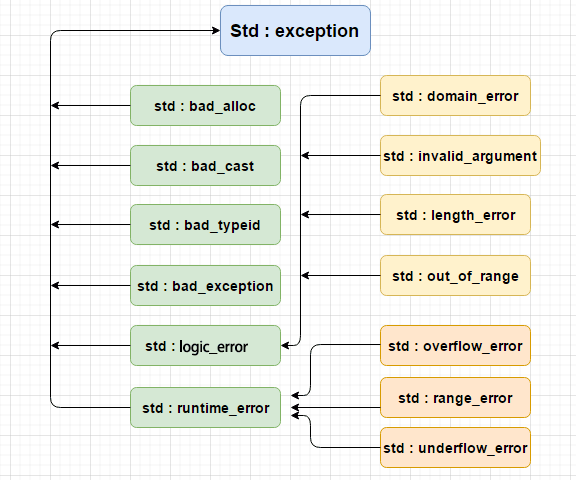
| 异常 | 描述 |
|---|---|
| std::exception | 该异常是所有标准 C++ 异常的父类。 |
| std::bad_alloc | 该异常可以通过 new 抛出。 |
| std::bad_cast | 该异常可以通过 dynamic_cast 抛出。 |
| std::bad_exception | 这在处理 C++ 程序中无法预期的异常时非常有用。 |
| std::bad_typeid | 该异常可以通过 typeid 抛出。 |
| std::logic_error | 理论上可以通过读取代码来检测到的异常。 |
| std::domain_error | 当使用了一个无效的数学域时,会抛出该异常。 |
| std::invalid_argument | 当使用了无效的参数时,会抛出该异常。 |
| std::length_error | 当创建了太长的 std::string 时,会抛出该异常。 |
| std::out_of_range | 该异常可以通过方法抛出,例如 std::vector 和 std::bitset<>::operator。 |
| std::runtime_error | 理论上不可以通过读取代码来检测到的异常。 |
| std::overflow_error | 当发生数学上溢时,会抛出该异常。 |
| std::range_error | 当尝试存储超出范围的值时,会抛出该异常。 |
| std::underflow_error | 当发生数学下溢时,会抛出该异常。 |
如果类的继承深度超过3层,就说明有点“过度设计”,因此我们最好选择上面的第一层或第二层的某个类型作为基类,不要再加深层次。
class my_exception : public std::runtime_error
{
public:
using thie_type = my_exception;
using supper_type = std::runtime_error;
public:
my_exception(const char* msg) : super_type(msg)
{}
my_exception() = default;
~my_exception() = default;
private:
int code = 0;
}抛出异常的时候,建议最好不要直接用throw关键字,而是将其封装成一个函数——通过引入一个中间层来获得更高的可读性、安全性和灵活性。
void raise(const char* msg) //封装throw的函数没有返回值
{
throw my_exception(msg); //抛出异常
}
try{
raise("error occured");
}catch(const exception &e)
{
cout << e.what() << endl; //what是exception的虚函数
}try-catch还有一个用法fuction-try:就是把整个函数体视为一个大try块,而catch块放在后面,与函数体同级并列。
void some_function()
try //函数名之后直接写try
{
...
}
catch(...) //catch块与函数体同级并列
{
...
}应当使用异常的判断标准:
- 不允许被忽略的错误
- 极少情况下才能发生的错误
- 验证影响流程,很难恢复到正常状态的错误
- 本地无法处理,必须穿透调用栈,传递到上层才能被处理的错误
保证不抛出异常
noexcept专门用来修饰函数,告诉编译器:这个函数不会抛出异常,编译器看到noexcept,就相当于得到了一个保证,可以对函数进行优化,不用付出栈展开的额外代码,降低异常处理的成本额。
void func_noexcept() noexcept //声明绝对不会抛出异常
{
cout << "noexcept" << endl;
}函数式编程
lambda表达式
auto func = [](int x)
{
cout << x * x << endl;
}
func(3); //调用lambda表达式因为lambda表达式是一个变量,所以我们“按需分配”,随时随地在调用点“就地定义函数”,限制它的作用域和生命周期,实现函数的局部化。
C++里的lambda表达式除了可以像普通函数那样被调用,还有一个普通函数所不具备的特殊本领,就是“捕获”外部变量,可以在内部的代码里直接操作。
int n = 10; //一个外部变量
auto func = [=](int x)
{
cout << x * n << endl; //直接操作外部变量
}
func(3); //调用lambda表达式函数式编程可以让程序不再是按步骤执行的"死程序",而是一个个“活函数”。
auto a = [](int x) {...} //a函数执行一个功能
auto b = [](double x) {...} //b函数执行一个功能
auto c = [](string str) {...} //b函数执行一个功能
auto f= [](...){...} //f函数执行一个功能
return f(a, b, c); //f调用a/b/c得到运算结果lambda形式
C++没有为lambda表达式引入新的关键字,用了一个特殊的形式方括号"[]",术语为lambda引出符,后面就跟普通函数一样,圆括号声明入参,花括号定义函数体。
auto f = [](){}; //空函数,什么都不做嵌套的时候,尽量让人一眼能看出lambda表达式的开始和结束,必要的时候可以用注释来强调。例如:
auto f2 = []()
{
cout << "lambda f2 << endl;
auto f3 = [](int x)
{
return x*x;
}; // lambda 3 //显式说明表达式结束
cout << f3(10) << endl;
}; // lambda f2lambda表达式赋值的时候总是使用auto来推导类型,这是因为每个lambda表达式都有一个特殊的类型,这个类型只有编译器才知道,我们无法直接写出来,所以用auto.
lambda表达式不需要像函数那样明确声明的返回类型,它可以自动推导(相当于auto),如果有时候必须明确指定的返回值,可以用"->type"形式来指定。例如
lambda变量捕获
- [=]表示按值捕获所有外部变量,表达式内部是值得复制,不能修改
- [&]表示按引用捕获所有外部变量,内部以引用的方式使用,可以修改
- []里也可以明确写出外部变量名,指定按值捕获或者按引用捕获
int x = 33; //一个外部变量
auto f1 = [=]() //lambda表达式,用"[=]"按值捕获
{
//x += 10; //x只读,不允许修改
};
auto f2 = [&]() //lambda表达式,用"[&]"按引用捕获
{
x += 10; //x引用,可以修改
};
auto f1 = [=, &x]() //lambda表达式,用"[&]"按引用捕获x,其余按值捕获
{
x += 20; //x是引用,可以修改
};"[=]"的按值捕获特性还有一个特例,可以给lambda表达式加上mutable,表示允许修改变量。注意这与按引用捕获不同,其修改的只是变量的内部复制,不影响外部变量的原值。
auto f4 = [=]() mutable
{
x += 10; //使用了mutable,可以修改
};当使用"[=]"按值捕获的时候,lambda表达式使用的是变量的独立副本,非常安全。而使用"[&]"的方式捕获引用就存在风险,当lambda表达式离定义 点很远的地方被调用的时候,引用的变量可能发生变化,甚至可能会失效,导致难以预料的后果。最好是在[]里显式写出变量列表,避免捕获不必要的变量。
class DemoLambda final
{
private:
int x = 0;
public:
auto print() //返回一个lambda表达式供外部使用
{
return [this]() //显式捕获this指针
{
cout << "member = " << x << endl;
}
}
}lambda泛型编程
在C++14里,lambda表达式又多了一个新领域,可以实现泛型化,相当于简化了的模板函数。
auto f = [](const auto& x)
{
return x + x;
};
cout << f(3) << endl; //参数类型是int
cout << f(0.618) << endl; //参数类型是double
string str = "matrix";
cout << f(str) << endl; //参数类型是stringauto虽然让lambda表达式实现了泛型,但类型推导完全由编译器控制,有时候我们还是想自己精确指明模板类型,C++20为lambda新增了新的泛型形式。与传统的模板函数类似,使用"<...>",但不需要关键字template:
auto f = []<typename T>(const T& x)
{
static_assert(is_integral_v<T>) //编译期断言,要求是整数类型
return x + x;
}内联名字空间
匿名空间主要是替代文件内的static声明, 即名称的作用域被限制在当前文件中,无法通过在另外的文件中使用extern声明来进行链接。如果不提倡使用全局static声明一个名称拥有internal链接属性,则匿名命名空间可以作为一种更好的达到相同效果的方法。
C++11内联名字空间与匿名名字空间差不多,里面的变量、函数、成员能够在外部直接使用,但也不排斥加名字空间,所以更加灵活,例如:
inline namespace tmp{ //内联名字空间,作用类似匿名名字空间
auto x = 0L;
auto str = "Hello";
}
cout << x << endl; //可以直接使用内部成员,不需要名字空间限定
cout << tmp::str << endl; //也可以加名字空间限定嵌套名字空间
//C++17之前
namespace a{
namespace b{
namespace c{
}
}
}
//C++17 简化的嵌套多层名字空间定义
namespace a::b::c{
...
}强类型枚举
C++中枚举类型来自C语言,基本相当于整数的别名,可以直接与整数互相转换,是一种弱类型,容易误用,非常不安全。
C++11强化了枚举,可以用enum class/struct形式定义枚举类。
枚举类是一种强类型,虽然它的语义与枚举相同,也是一些整数值的列表,但枚举成员不能随意转换成整数。而且必须添加类名限定才能使用。
enum class Company {
Apple, Google, Facebook
};
Company x = 1; //错误,不能从整数直接转换
auto v = Company::Apple; //必须加上类名限定,可以使用自动类型推导
int i = v; //错误,不能直接转换为整数
auto i = static_cast<int>(v); //可以显式强制转换枚举类虽然增强了安全性,但缺失了普通枚举的类型简便、易用的好处,所以C++20允许使用using来“打开”枚举类,这样它就和先前一样了:
using enum Company; //打开枚举作用域
auto v = Apple; //不再需要类名限定条件语句初始化
在C++17里,if/switch语句在圆括号的条件表达式中添加仅在本语句中生效的变量,免去了有时候必须在语句前声明临时变量的麻烦。
vector<int> v {1,2,3};
if(auto pos = v.end(); !v.empty()){ //在if语句里初始化变量
... //变量pos仅在if语句里失效
} //离开if语句,变量pos失效if/switch语句的形式很像是"半截"的for语句,只有前面两个表达式,没有第三个增量表达式,所以花括号里的代码也只会执行一次。在概念上近似于加上break的for语句。即:
if(init; cond){ //在if语句里初始化变量
... //初始化变量仅在if语句里有效
} //离开if语句,变量pos失效
for(init; cond;){ //在for语句里初始化变量,没有第三个表达式
... //初始化的变量仅在for语句有效
break; //执行语句后立即结束
} //离开for语句,init变量失败应用场景:
if(scoped_lock g; tasks.empty()){ //锁定互斥量后检查任务队列
... //if语句内互斥量被锁定
} //离开if语句,变量析构自动解锁二进制字面值
auto a = 10; //十进制
auto b = 010; //八进制
auto c = 0x10; //十六进制
auto x = 0b11010010; //C++14新增二进制,0b/0B前缀数字分位符
为了方便阅读源码里的数字,增强可读性,C++14标准提供了数字分位符的特性 ,允许在数字里使用单引号 “ ' ” 来分组,而且不限制分组长度。
auto a = 0b1011'0101;
auto b = 07'6'6;
auto c = 1'000'000;














 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









