









支持多卡部署
支持多机部署(非原生,nginx网关、ray等)
支持GPU、CPU混合运行
支持运行格式pt,safetensors,npcache,dummy,tensorizer,sharded_state,gguf,bitsandbytes,mistral,runai_streamer
环境信息
机器01
操作系统:Debain 12.9/Ubuntu 24.04
CPU:i7-10750H
内存:32G
显卡:GTX 1650(4G)
硬盘:SSD(1T)
IP:192.168.3.17
基础组件安装
创建python虚拟环境
python3 -m venv ~/vllm
source ~/vllm/bin/activate
安装python模块
# 使用清华大学python源,https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple
vllm --version
vllm -h
vllm serve -h
下载模型
modelscope download --model 'unsloth/DeepSeek-R1-Distill-Qwen-1.5B' --local_dir 'unsloth/DeepSeek-R1-Distill-Qwen-1.5B'
部署模型
# 部署safetensors模型
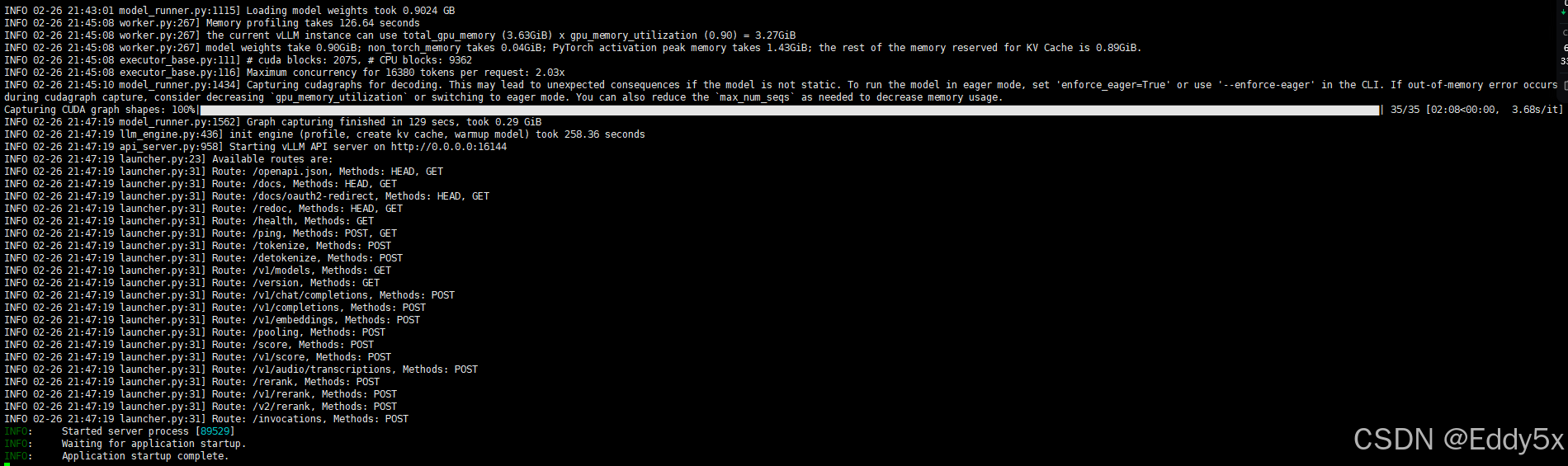
vllm serve ~/ollama/unsloth/DeepSeek-R1-Distill-Qwen-1.5B --enable-reasoning --reasoning-parser deepseek_r1 --dtype float16 --cpu-offload-gb 4 --max-model-len 16380 --api-key vl-5bgrMOCJ5OSBKQV5XbHz --port 16144
# 部署gguf量化模型
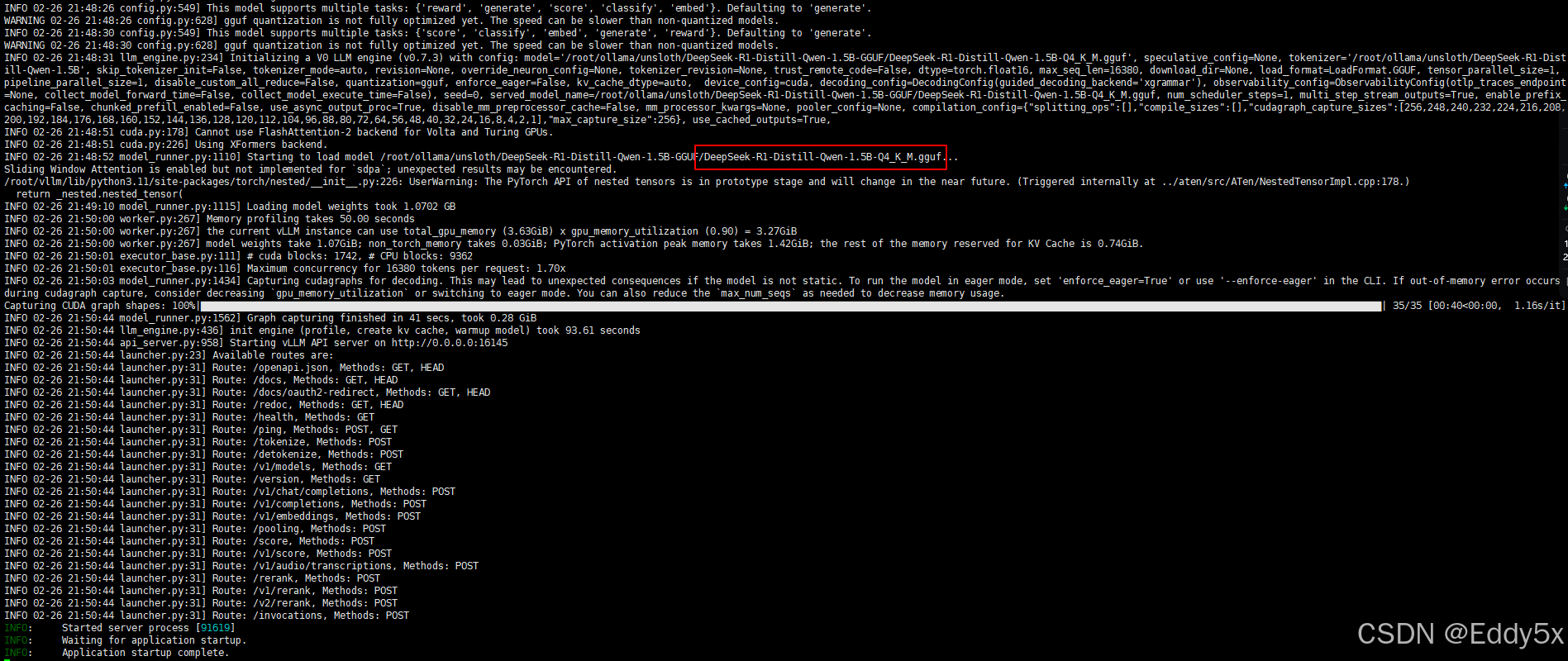
vllm serve ~/ollama/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf --tokenizer ~/ollama/unsloth/DeepSeek-R1-Distill-Qwen-1.5B --enable-reasoning --reasoning-parser deepseek_r1 --max-model-len 16380 --api-key vl-5bgrMOCJ5OSBKQV5XbHz --port 16145
部署效果


















 1115
1115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











