






 本文介绍如何利用cBioPortal平台高效下载癌症基因组数据集,包括使用R包cgdsr进行数据集分析,以及通过构建shell脚本自动化下载大量数据的方法。
本文介绍如何利用cBioPortal平台高效下载癌症基因组数据集,包括使用R包cgdsr进行数据集分析,以及通过构建shell脚本自动化下载大量数据的方法。
cBioPortal对癌症基因组数据集做了比较好的整合,为了进行数据集的下载、分析和可视化。
可以用网页工具或者它们提供的R包"cgdsr"对几个目标基因进行分析,或者下载他们从Broad Institute Firehose下载整理的数据集。
cBioPortal的数据集下载页面如下,可以直接点击下载按钮下载单个数据集, 如果要批量下载,就需要一点网络爬虫的小知识。
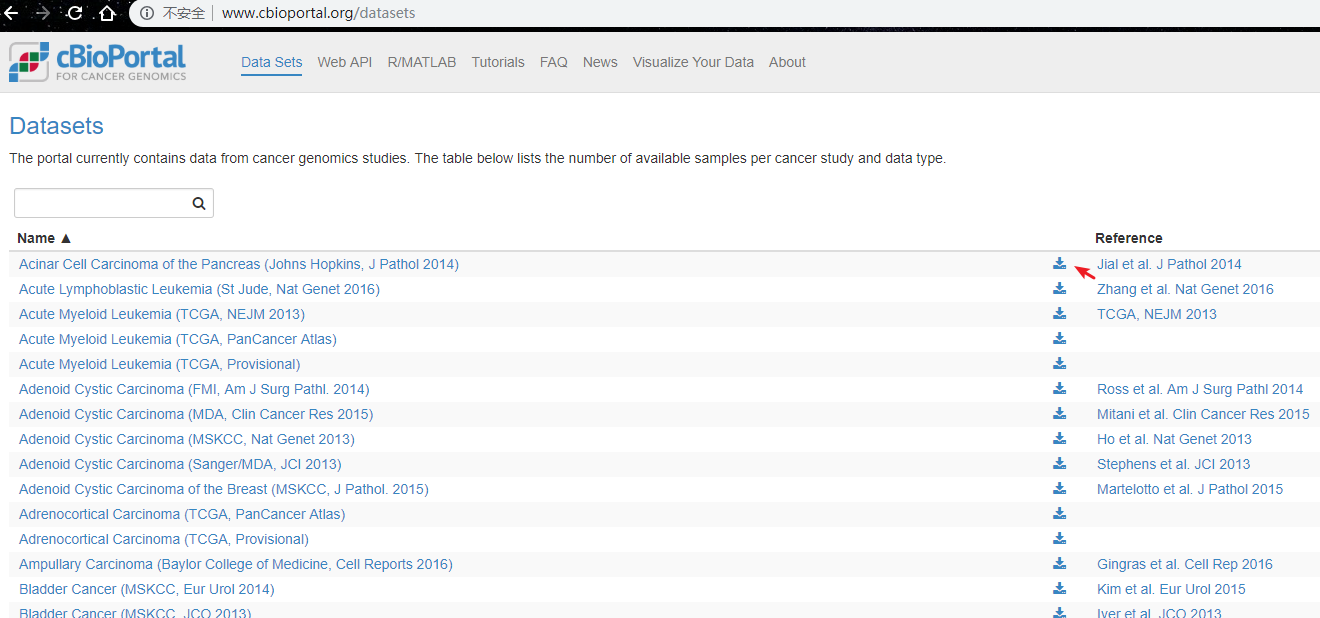
网页内容
使用Chrome浏览器的检查功能,寻找实际的下载地址
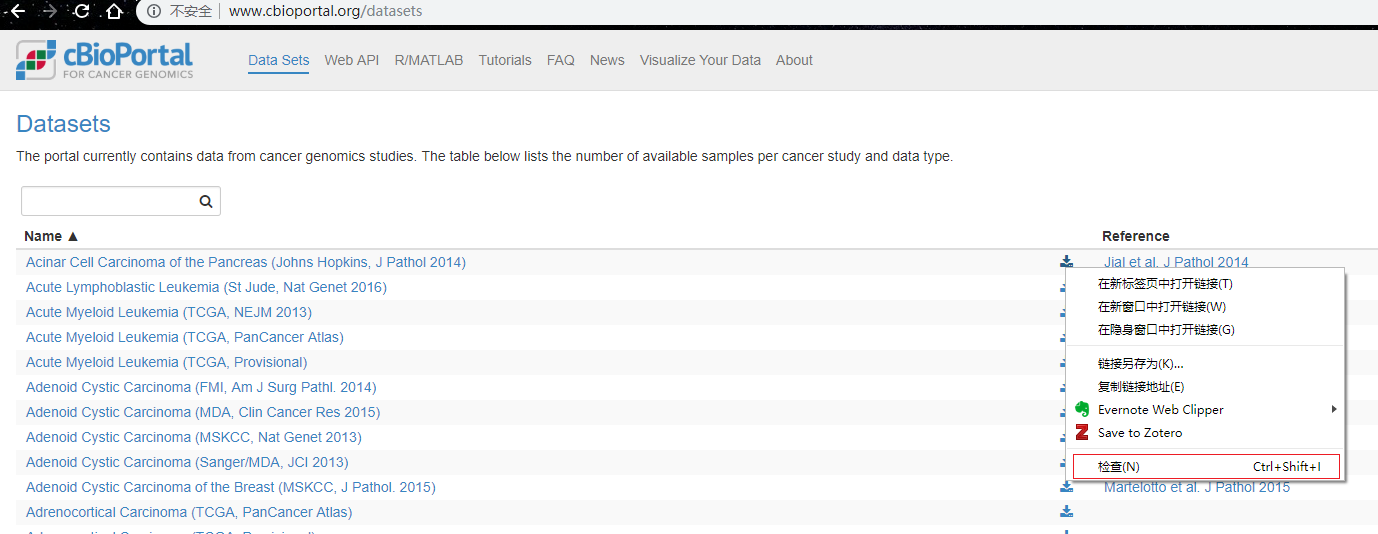
image.png
不难发现,下载链接是http://download.cbioportal.org/paac_jhu_2014.tar.gz

下载地址
一开始的想法是,用curl http://www.cbioportal.org/datasets下载网页,然后用grep找到所有的下载链接,但是通过检查原代码,我发现这个页面其实是动态加载,不能通过常规的爬虫手段。
根据我的爬虫经验,下一步就是找JSON包,一般这种延迟加载的网页都会接着向服务器发起申请,获取需要的数据,果不其然,被我找到了json包。
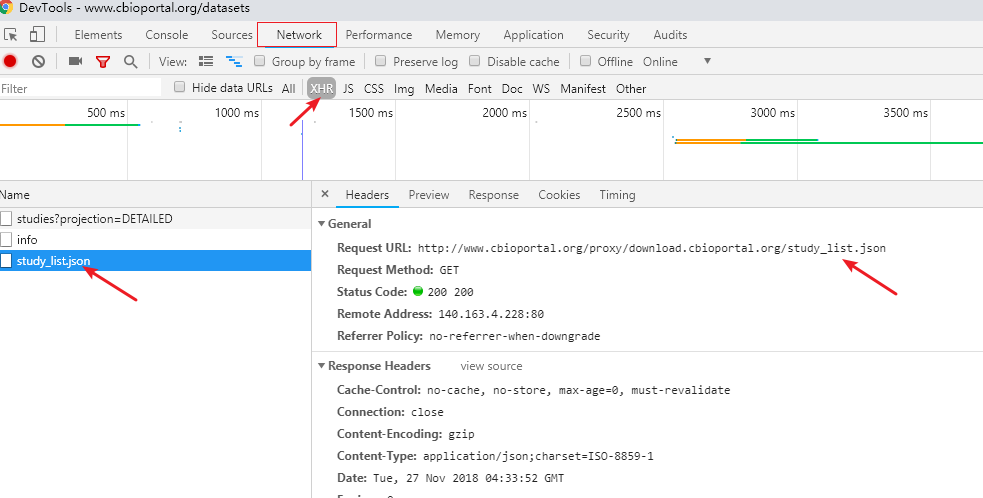
JSON
wget http://www.cbioportal.org/proxy/download.cbioportal.org/study_list.json
检查该文件,推测里面每一行都是之前下载链接中压缩包文件名前缀
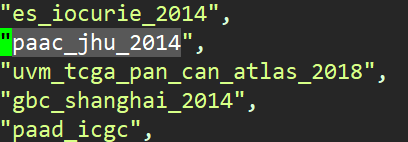
json内信息
构建一个下载shell脚本
for study in $(sed -e 's/"//g' -e 's/\[//' -e 's/\]//' -e 's/,//' study_list.json)
do
wget "http://download.cbioportal.org/${study}.tar.gz"
done
发现能够顺利下载,证明了猜测,就是下载速度非常的感人。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









