







ACM TOMM 2017最佳论文:让AI接手繁杂专业的图文排版设计工作近日,美国计算机学会会刊ACM TOMM宣布把2017 Nicolas D. Georganas Best Paper Award授予“Automatic Generation of Visual-Textual Presentation Layout”(图文排版的自动生成算法研究),该论文介绍了如何利用算法实现自动的图文排版。 https://www.msra.cn/zh-cn/news/features/acm-tomm-2017-best-paper-20170810告别拼接模板 —— 阿里妈妈动态描述广告创意 - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:云芑要问广告主最烧脑的是什么,那一定做创意图了。创意图是广告的呈现方式,是向消费者传达商品、品牌等信息的媒介, 也是广告能否完成投放、触达消费者的先决条件。为了…
https://www.msra.cn/zh-cn/news/features/acm-tomm-2017-best-paper-20170810告别拼接模板 —— 阿里妈妈动态描述广告创意 - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:云芑要问广告主最烧脑的是什么,那一定做创意图了。创意图是广告的呈现方式,是向消费者传达商品、品牌等信息的媒介, 也是广告能否完成投放、触达消费者的先决条件。为了… https://zhuanlan.zhihu.com/p/398758852告别拼接模板 —— 阿里妈妈动态描述广告创意 - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:云芑要问广告主最烧脑的是什么,那一定做创意图了。创意图是广告的呈现方式,是向消费者传达商品、品牌等信息的媒介, 也是广告能否完成投放、触达消费者的先决条件。为了…https://zhuanlan.zhihu.com/p/398758852平面设计自学入门教程:色彩篇(2/5) - 知乎初学平面设计,总觉得色彩搭配晦涩难懂。不过值得庆幸的是,早有专家学者归纳出了如下的 色彩理论,能够帮助你更好的认识理解色彩。 版权声明本文经“ GCFlearnFree.org”授权后,由@酷coo豆 翻译中文,并首发于平…https://zhuanlan.zhihu.com/p/28863186
https://zhuanlan.zhihu.com/p/398758852告别拼接模板 —— 阿里妈妈动态描述广告创意 - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:云芑要问广告主最烧脑的是什么,那一定做创意图了。创意图是广告的呈现方式,是向消费者传达商品、品牌等信息的媒介, 也是广告能否完成投放、触达消费者的先决条件。为了…https://zhuanlan.zhihu.com/p/398758852平面设计自学入门教程:色彩篇(2/5) - 知乎初学平面设计,总觉得色彩搭配晦涩难懂。不过值得庆幸的是,早有专家学者归纳出了如下的 色彩理论,能够帮助你更好的认识理解色彩。 版权声明本文经“ GCFlearnFree.org”授权后,由@酷coo豆 翻译中文,并首发于平…https://zhuanlan.zhihu.com/p/28863186
打算出一个创意合图的系列,在这个系列中,来看一下市面上主流的合图能力大概是如何的,创意合图以鹿班为首,有玲珑,稿定,特赞,阿里妈妈等创意合图的实验,合图大方向上属于视觉生成领域,面对不同的场景,选择受限或者非受限的方式,是业务性导向很强的算法落地场景,鹿班是极其典型的算法落地,在玲珑和稿定等上,看来就是一个很简单的合图工具,偏工具性质的,用阿里妈妈的话说就是拼接创意,并不涉及智能,智能创意合图还是一个很难的算法方向。从批量合图上升到创意合图,其实还有很多事情可做,从完整闭环上说,可以有智能素材,智能合图,智能优选,素材可以提供合图所需要的元素和布局以及模板库,优选则是结合人群或者其他因素做的增效行为,每一个环节都是有很大工作量的,从创意的工程角度上讲,实时合图,数据结构,图片存储都是需要能力支撑的。我们更多从算法角度讲合图的难点,我们在日常业务中主要面对是两种创意合图,第一是智能创意,输入商品图和文案得到banner,第二,业务方提供一个模板集,固定可以更改的商品位和文案,文案很多都是和sku进行绑定的,来进行合图,后者就是典型的拼接创意,目的在于批量合图,前者是智能创意,是有这布局,排版,微调,审美几个评价指标的创意图合成。本文是微软在2016年提出的图像文本合图框架,严格意义上是属于第一种类型,是智能创意。局部决策优化,配合特征化,不是全局的优化,全局优化可能会有四不像的风险。创意合图主要是海报的合图,输入海报图片和文字,就两步,第一考虑对图片的裁剪和识别,第二就是把文字粘贴到海报上,还是比较简单的应用场景,没有涉及到很多元素,传统banner图的创意合成,会涉及到大量的元素排版,文字商品布局排版,微调,颜色迁移,目标尺寸拓展等。此外这篇文章作为核心的思想还是美学设计上的知道,海报设计出来要吸引人,但是在电商的场景下,除了好看之外,还要符合产品设计的一些原则,而且banner图在模板布局差异不大的情况下,美学上的评估往往是确保badcase不要出现。
1.abstract
本文提出的系统是具有一组主题相关的布局模板和一个集成高级美学原则和低级图像特征的计算框架。布局模板是根据领域专家的先验知识设计的,用于定义空间布局(spatial layouts),语义颜色(semantic colors),调和颜色(harmonic color models)以及字体情感(font emotion)和大小约束(size constraints)。通过最小化文本侵入的代价,视觉空间的效用以及感知和语义中信息重要性的不匹配,受自动选择模板的约束并进一步保持颜色协调,将排版设计描述为一个energy optimization问题。专家知识做排版设计其实就是考虑规则,需要去综合的细节还是很多的,如果直接是layout生成又会面临生成布局不可靠的问题,因此大部分生成上的方案还是先验布局在筛选协调。
2.introduction
创意设计一个基本的挑战是如何设计一个由异构媒体元素(如图像和文本描述)组成的具有视觉吸引力的布局。
设计的基本要素是指六种基本视觉元素,color,line,shape,tone,texture和volume,在更高层次上,设计原则提供了使用和安排设计元素的关键方法,涉及特定规则,例如对称或非对称视觉结构中的视觉平衡,具有重复规则和对齐点的排版以及令人愉悦的颜色协调等。设计的美学不仅衡量元素组合的形式,还衡量视觉文本布局所传达的情感。
学术界也对自动生成视觉文本布局进行了很多次尝试。提出了视觉平衡(visual balance),平衡(equilibrium),统一(unity),密度(density)和比例(proportion)的计算美学规则。通过这些计算模型,视觉文本布局的生成通常被视为图形约束(graphical constraint)和能量优化(energy optimization)的问题。
特定领域的知识和内容特征在布局生成中都起着重要作用,在应用预定义模板之前,视觉文本呈现布局的良好设计应考虑主题相关、特定领域的美学原理和计算内容特征。
2.related work
设计视觉文本布局是一个多学科问题,可以分为三个阶段,1.根据目标媒体的尺寸标准组合图像;2.在重叠图像上排版文本;3.为文本元素着色。
2.1 image composition
为了解决原始图像与不同媒体尺寸标准之间的不匹配问题,需要调整图像大小以符合目标布局并保留重要区域,例如面部和显著区域。1.最直接的裁剪,2.在一些基本美学准则下缩放和裁剪图像来优化照片构图,例如三分法,对角线优势和视觉平衡,这块和智能构图很像,在创意中我们有单独的智能构图的效率工具。本文只应用图像裁剪和缩放来保留图像的本质(image cropping and scaling)。从模板尺寸向目标尺寸迁移是个重要的环节,在我们的创意合图中,我们会将尺寸作为模板筛选的一个选择,先选到和目标尺寸相近的模板,再利用尺寸拓展去微调,当然了,这里的裁剪是对输入图的裁剪,我们的目标尺寸变换是对模板的变换,还是有很大却别的。
2.2 automated layout
如何确定媒体中文本和图形元素的大小和位置仍然是个挑战。将自动化布局问题作为具有美学规则和视觉感知规则的优化问题来解决,通过最小化energy,包括文本位置,大小和颜色,将文本和图形的交互视为优化问题,并且还引入基于模板的约束来保证优化的性能。这一步其实很重要,本文也用了一个非常合理的建模方式来优化这个问题,但是图像元素其实只有背景一个,其实就是背景和文本元素的排版问题,文本元素不止一个,且位置不固定,图形元素默认是背景元素只有一个,是文本在背景上排版的问题。
2.3 color design model
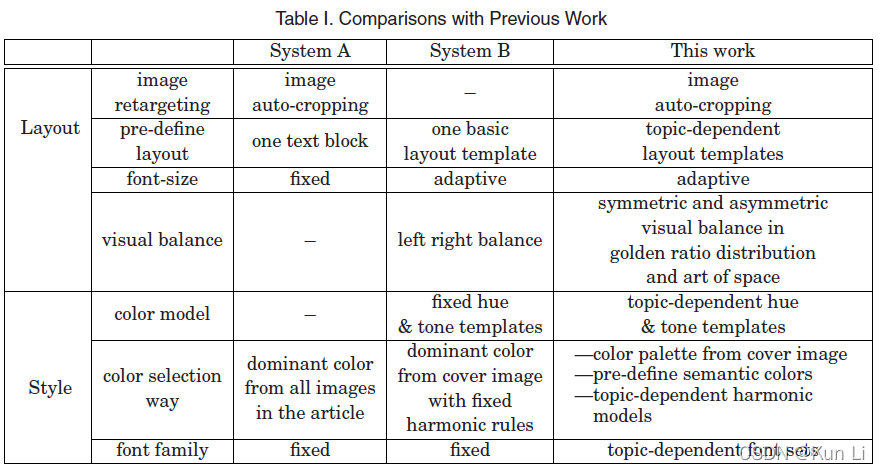
3.template design
主题相关的模板设计是由视觉文本布局自动生成过程中的两个主要观察结果驱动的,1.难以准确描述人类感知的视觉和文本元素,2.人们在设计视觉文本媒体时运用了高级经验和不可感心理。为了弥合特定领域的布局设计和计算内容特征之间的差距,我们引入了主题相关模板,用于约束视觉和文本之间的交互。模板有两个方面定义:空间布局和主题相关风格。在空间布局中,采用黄金比例分布的对象和非对称视觉平衡以及空间艺术都被考虑在内,风格设计包括主题相关的字体,字体大小约束,语义颜色和颜色协调模型。列出了常见的设计样式点:
Textual information completeness 为了使杂志封面视觉完整,文本元素不应超出背景图像的边界或相互重叠。
Visual information maximization 图像的大小应调整为目标分辨率,同时保留重要的视觉信息(即图像区域),如人脸、文本、显著对象、人类参与区域等。此外,嵌入的文本元素不应遮挡显著区域。
Spatial layout reasonableness 要想制作出自然、吸引人的杂志封面,文字元素的位置应遵循审美原则。 例如,对称平衡遵循人类审美感知的关键规则,文本应放置在背景图像的空白处。
Perception consistency 文本元素在视觉感知和语义感知中的重要性是一致的。 因此,重要的文本应该在非显着区域以更独特的文本大小、字体和更高对比度的颜色显示。
Color harmonization: 从视觉感知的角度来看,文本元素的颜色应该是和谐的、有感染力的。
Textual information readability: 为了让读者一目了然,需要适当大小的文本元素。 此外,文本元素和背景图像之间的颜色对比应该可以提高文本信息对读者的可用性。

3.1 aesthetic principles
3.1.1 spatial layout
杂志封面定义了16种常见的空间布局,不同的主题,空间分布的布局也不同,在排版文本元素之前,空间布局根据主题约束和布局覆盖在图像上时的侵入程度进行排序。
3.1.2 topic-dependent style
收集了8个最常见的主题,包括fashion,economy,food&drink,travel,entertainment,IT&Tech,sports,politics,对于每个主题,我们收集了800个媒体海报来总结设计原则。我们定义了5种样式:
Font Emotion:将字体情感和字体系列相关联,有四种字体系列,Masthead,Headline,CoverLines,Subtitle。
Font Size Constraints:字体带下对于引导读者焦点很重要,定义了四个连续的流,和字体情感对齐,Masthead,Headline,CoverLines和Subtitle。
Semantic Colors:每个主题支持20中语义颜色。
Harmonic Color Model:对于每个主题,我们根据主题的属性从Tokumaru的8个色调协调模板中对齐一个或两个颜色协调模型。Tokumaru介绍了8种hue distribution和10种tone distribution。
3.2 template samples
我们总共涵盖了8个最常用的主题,定义了16种常见的空间布局,对于每个主题,设计了20种语义颜色,4种字体情况和1到2种颜色协调模型的主题相关样式。
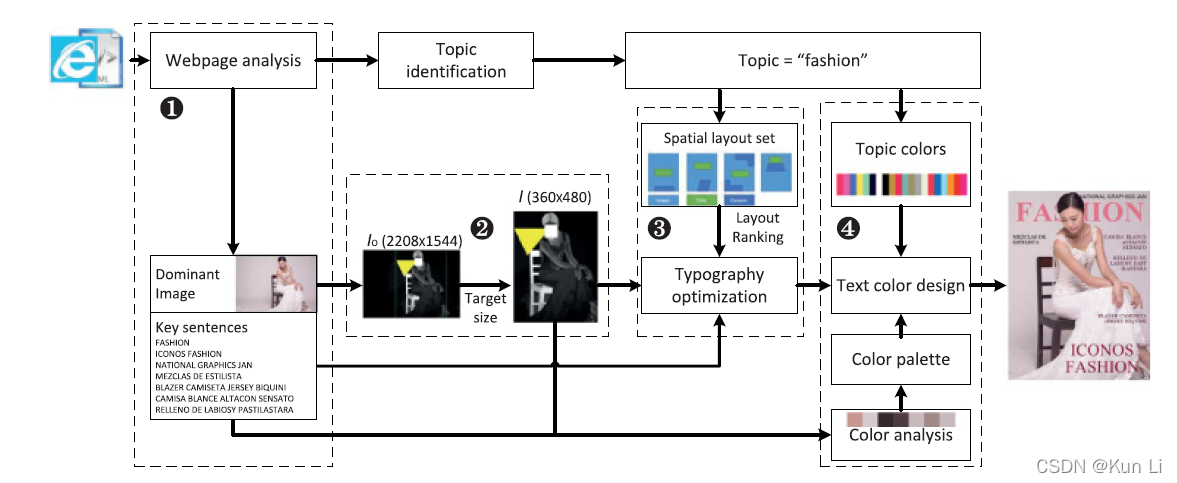
1.素材生成器,用户可以直接上传图片和文字,或者我们可以分析网页以获取主导图片和关键句子;2.图像合成,原始图像被自动裁剪和缩放以匹配目标布局大小;3.排版优化,在所选布局模板的空间约束下,文本覆盖在调整大小的图像上;4.文本颜色设计,其中考虑对全局颜色协调和主题相关风格,对文本进行重新着色。
上面这四步,基本就是微软这个automated layout的核心了,从主题词获取模板集和,排序后产生模板,有了模板,就可以根据输入图,文字等做排版优化,模板上的位置如何优化呢?这是核心问题,我们做的banner方案,其实选中模板之后,主要的工作是微调,商品和文案区域,尤其是文案区域是需要大幅度调整的,但是还会参考模板的文案区域,banner中限制了文案区域只有一个,但在这个场景中,多块的文案区域怎么结合图像信息在已有的空间约束下调整,就是个很难的问题了?最后是给文本上色。
图2中给出了两个具有特定定义的模板示例,杂志封面样式布局模板定义具有四种类型的模板元素,Masthead(刊头),Coverlines(封面线),Headline(标题),Subtitle(副标题)。对于每种类型的元素,我们预先定义了图像百分比范围内黄色区域中显示区域,黄色区域的设计考虑了空间布局的美学原则,例如b中的设计假设当显著对象位于图像的左下角时,文本应该限制在预定义的区域,引导文本元素从上到下流动,实际的文本区域可能会根据图像重要性有所不同,以避免被显著对象遮挡。相应的,字体大小,字体系列和文本对齐方式的范围被定义为模板中的样式。
4.generation of visual-textual layout
除了预定义的布局模板之外,在视觉文本布局的自动生成中还应考虑基于内容的图像特征,例如显著图,通过结合显著性,人脸,文本和注视注意力图对原始图像进行处理,得到视觉感知图,根据视觉感知图调整图像大小以匹配目标布局大小并保留重要区域。然后使用调整大小的图像根据空间分布对布局模板进行排名。使用调整大小的图像,给定的句子和空间布局,文本通过阶段3中的energy优化叠加在背景图像上。

4.1 image composition
resolution mismatch问题,提出了cropping-and-scaling-based image resizing算法来处理。裁剪的原则就是尽可能保留掩码下的最大区域且转换为目标尺寸。
4.2 typography
视觉文本布局的排版被定义为将文本叠加到背景图像上的过程。但是注意的是背景是有布局的。一个句子在图像上的表示通常被视为一个文本块,文本块的轮廓被定义为相应句子的边界框,显示这些文本块时,遵循:首先,文本块不应与原始图像中的显着视觉对象重叠太多。 重叠区域被定义为文本侵入。 其次,文本块应充分利用空闲的视觉空间。 第三,具有重要语义信息的文本块应显示在背景图像非显着区域的重要位置。因此,我们将排版表述为一个能量优化问题,以最大限度地减少文本侵入的成本、空闲视觉空间的浪费以及感知和语义中信息重要性的不匹配,并限制自动选择的模板。
排版的输入是句子s和处理的图像I,句子的顺序表示重要性的顺序,因此用u表示s的语义重要性的权重,u=N/i,i越在前,重要性越大,u1>u2>u3>...>un。为避免文本侵入图像I中的显著对象,句子相应的换行,在传统的基于网格的方法中,图像以固定的宽度和高度进行网格化,文本被视为一系列单独的字符,每个字符占据一个网格,布局死板。我们提出了文本块的概念(text block),Li=(pi,hi,(xi,yi)),pi=(Di,Ui,Fi),pi表示轮廓形状,轮廓形状取决于换行方式,对齐方式和文本的字体系列,Di表示换行方式,一个句子s有m个词,有2^(m-1)种换行方式,Ui={left,center,right}是块中的对齐方式,Fi={TimesNewRoman,segoe,geogia,verdana,calibri}包含每个字体系列的纵横比,确定轮廓的形状后,句子中字符的高度hi将缩放形状并控制文本块Li的轮廓大小。(xi,yi)是文本块左上点相对于图像左上点的像素级位移。Li描述了句子s在背景图像I上的表示。所有的文本块的并集定义为L={Li},在视觉图像上呈现所有文本内容,进一步我们将文本区域定义为R(L),文本块覆盖的每个像素都属于R(L)。
energy优化包含三个部分:
![]()
Es是文本侵入到图像I上显著视觉对象的代价,Eu表示空闲视觉空间,Em代表语义重要性u和文本块的视觉感知重要性wi之间的不匹配。
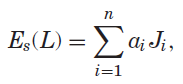
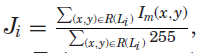
Im是二值化的显著区域,只计算文本块区域的二值化像素和255之比,这是刻画文本入侵程度的,其值越大越说明文本占据的背景区域越多,α表示每个模板中每个元素的权重比,在这个case中是{0.1,0.1,0.7,0.1}对应到Masthead,Headline,CoverLines,Subtitle。
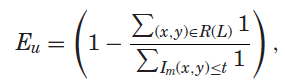
![]()
t是二值化图Im在文本块中像素最大阈值,Eu鼓励利用空闲区域,因此在文本块区域中阈值在最大阈值下的区域是希望尽可能多利用的,字体大小和阈值成反比,就是说阈值高,那么很可能是显著区域,这时候文字要大一点,不是显著区域,文字要小一点,是比较奇怪的逻辑,但是从合图的这张看,也有道理,动态优化的过程上将,阈值小的,可能就是文字块和显著区域的交集很少,那文字越小,不是越能避开这个区域。
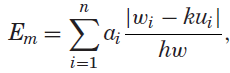
![]()
Ia是图像中的注视区域,人在图像中有个注视角度,有一片区域就是注视区域u,文本块在注视区域的像素称之为wi,k是调整最小化Em的拟合系数,energy通过注视注意力将重要句子与有吸引力的区域对齐。设置μu=μm=0.5,当视觉图像中无法检测到人脸时,将忽略Em,使得μm=0。
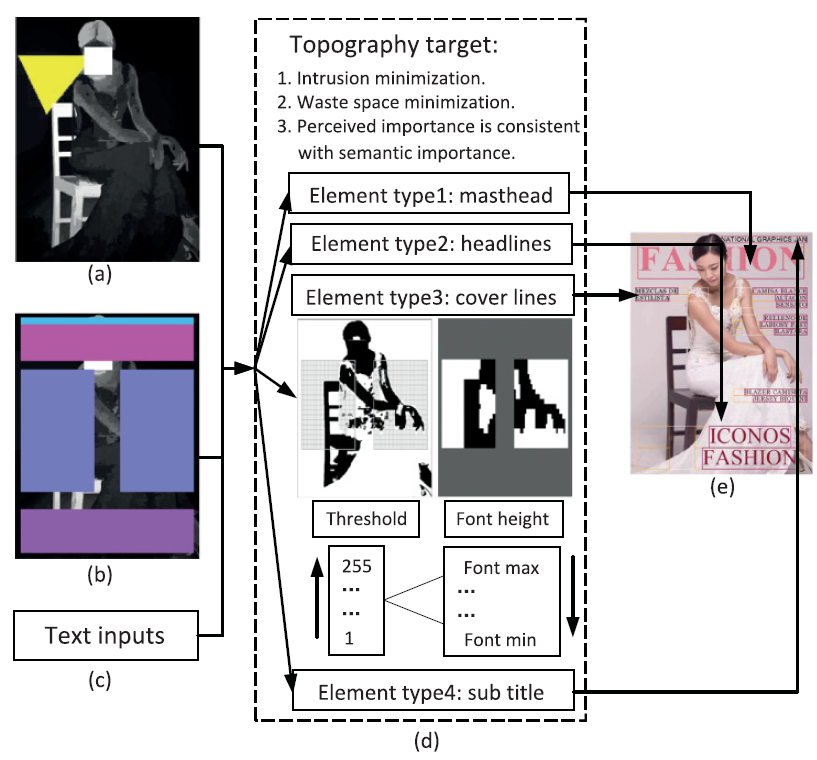
排版过程,1.视觉重要性图(灰色)和注视注意力(黄色);2.从排名前5的模板中选出模板,模板的区域不是精准的,文案是需要重排的;3.输入文本;4.排版,例如:其中定义为E(L)将通过迭代控制正面高度在次优化中将其最小化。5.在自下而上的图像特征和自上而下的空间布局约束下的排版结果。
L={Li},其中Li=(pi,hi,(xi,yi))很大,pi=(Di,Ui,Fi)表示轮廓形状,带有mi个单词的句子si,Di的空间为2^(mi-1),Ui空间是3,Fi空间是5,字符hi的高度是1到h,(xi,yi)的意味空间就是整个图像I,每个句子的si的复杂度是Oi=2^(mi-1)x3x5xhxwxh,解空间的总复杂度是O=2^(m-N)x(3x5xhxwxh)^N,通常句子的数量N为3-6,文本内容中的总字数为30-60,w/h是图像I的分辨率,无法在可接受时间内找到全局最优解,为了可解,我们假设布局中的元素类型作为能量优化过程的系列子问题来单独处理。
4.2.1 ranking of templates.
考虑到设计师的模板设计,有16种不同视觉平衡的空间设计,每个模板都去尝试太耗时间,因此提出了一种简单有效的排名方式:
![]()
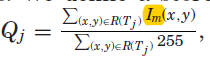
Tj是模板中的元素,R(Tj)是表示j类型的掩码区域,会过滤得分最高的5个模板。
4.2.2 energy minimization
为了解决复杂度问题,每个元素的排版都是单独的,将阈值t从1增加到256,阈值越小,文本侵入越少,但放置文本的可用空间也越小,一旦确定阈值,系统会将文本放置在Im(x,y)低于当前阈值的非显著区域,阈值逐渐增加,知道所有的文本都在约束下插入到图像中。通过最大限度的减少空白区域,在给定的范围内选字体大小,最大字体大小不仅由其自身约束决定,还受其他类型模板元素的约束。
4.3 harmonic color design
颜色协调有两个要求:1.保持文本颜色和背景图像全局协调,2.保持文本的局部可读性。调色板有7种颜色,前4种来自显著物体,后3种来自非显著物体,同时语义颜色由图像主题标识主要是借助topic-dependent harmonic models,用于文本颜色生成。根据主题模板中主色的定义,从调色板中选择主色,主色的定义在不同的主题模板中是不同的,在时尚模板中就定义为出现频率最高的颜色,语义颜色通过和主色在analogous hue type中的最大匹配分数来选出,提取响应最大颜色作为本文的基础颜色,然后根据基础颜色确定其余文本颜色。
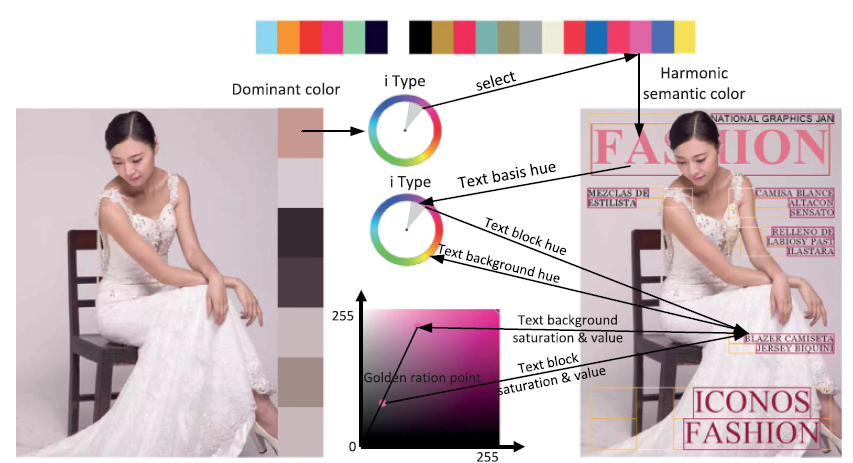
首先,从自动调整大小的图像的显著区域中提取主色,然后,在analogous type harmony model中选择具有主色的语义色,布局的masthed设置成语义色,最终其他文本的hue值由i type hue model来决定,为了补偿和背景的对比,我们将文本的tone设置为背景tone与tone空间中饱和度值坐标中尽可能远的相反方向之间的黄金比例。
在时尚主题中,主色被定义为显著区域中出现频率最高的颜色,据此,选择调色板中第一种颜色作为主色,反映视觉的基色,通过主题的analogous hue type,在analogous hue type中有最大匹配分数主色将作为文本的基本色,在杂志封面中在Masthead位置放基本色,基于基本色,通过topic-dependent harmonic models和局部图像特征来识别其余文本。
5.experiment
作者也用了人工来对比的评估实验。
综合来看,本文属于纯传统方法的图文自动生成,对模板的依赖还是很高的,一个好的模板几乎决定了全部,但是由于海报场景的相对简单性,16个不同布局已经能很好的处理所有可能的布局情况,当然了现在看,这是个在图像上添加文本的问题,文本的位置是由模板和energy函数来控制的,文本位置的多样化其实还弱化了16个模板中文本位置的限制,传统的banner场景其实只有一个文案区域,对于文案区域实际是重排的,但是由于有众多元素,这些元素基本是与模板强绑定的,让这些元素产生和文本一样的自由度是几乎不可能的,文案区域由于重排,在内部确实有可能产生很高的自由度,甚至有原来的模板完全不同的文案布局也是可以的,我们现在就是单独给文案模块维护自己的文案模块,布局的建模其实也比较简单,就是长宽高和换行的预测。本文采用的是文本块的方式,文本块无法处理文本本身的多样性,但是在局部确实有个最优解,理想情况,不对文字有过多要求的话,文本块确实不错的思路,这就类比banner中的文案区域,只不过海报场景有几个文本块,banner就只有一个,做banner场景,其实会对文本块做更细的划分,至少要到行的调整。另外,本文的这个设计,对energy的要求还是有点重,energy能够优化和平衡好已有模板的约束吗?好在已有模板提供了掩码区域,相当于给了一层还不错的先验,颜色模型这块应该主要是借鉴前人的,感觉没说清楚到底是个什么流程。
本文的布局是从每个主题下800个模板中抽象出来的,有概括性,模板中的元素也不是固定的属性和特征,而是有一个相对的概念,除了个数是强制的,很多属性是约束性质的,在我们传功的banner设计中,没有这么想,或者说,这么做,自由度太高,很难收敛,通常具体的属性,除了颜色之外几乎都是复用的,本文在energy之前还有很多可分析的区域,也来自于输入图像是背景,这种有点像场景图的意思,banner中输入是商品图和文案,对于商品图没有太多可操作性的空间,大部分的操作空间还是留给了模板,选择设计好的模板也是为了先验知识,用各种gan生成出来的不靠谱,并且电商是强类型场景,它本身设计就有很强的规则性,自有度不高的,相反,审美的品味可能会差很多,还是商品本文或者促销本身更有吸引力,更能提升ctr。最终这三个组合的energy能不能有效果,我还是很存疑的,可惜,没有开源代码。

















 5326
5326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









