







自sora之后,我也要多思考,transformer的scaling law在各个子领域中是不是真的会产生智能,conv的叠加从resnet之后就讨论过,宽或者深都没有办法做到极限,大概sam这种思路是最好的实证。
1.introduction

引入了ViT adaptation策略和detail capture module。
2.Methodology
2.2 Overall architecture
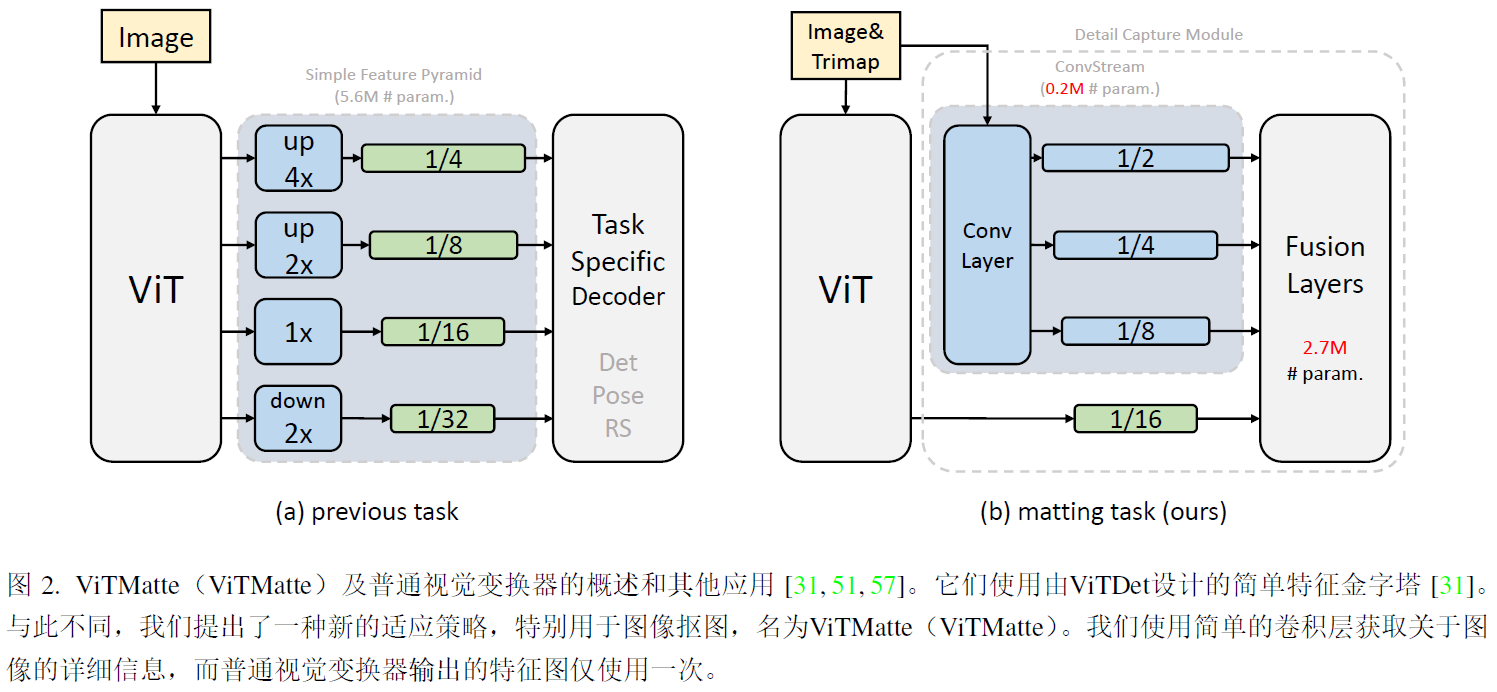
给定一个RGB图像HXWX3以及其对应的trimap HXWX1,按通道连接它们并输入到ViTMatte中,ViT作为基础特征提取器,生成一个stride=16的单个特征图,detail capture模块由一系列卷积层组成,用于捕捉和融合图像matting中的详细信息,简单的在不同尺度上采样和融合特征,以预测最终的alpha。
2.3 Vision transformer adaptation
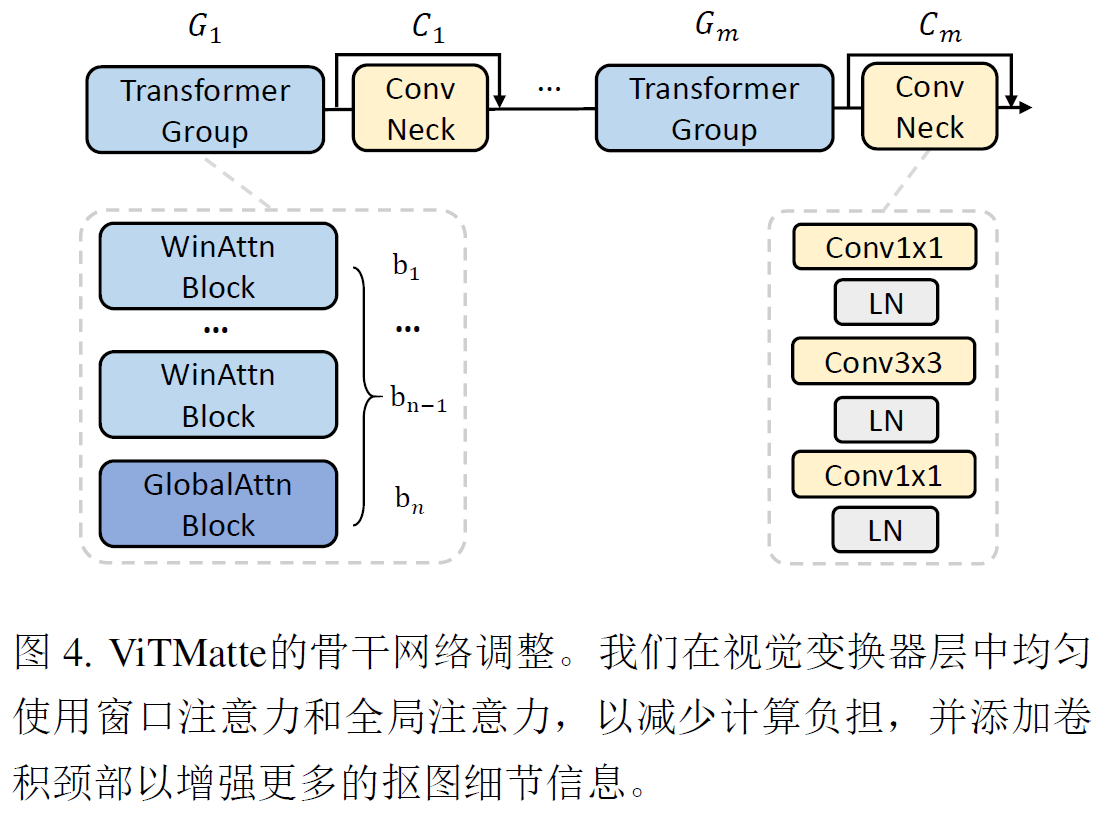
将普通VIT中的block分层m组G,每个组中包含n个transformer块,对于G中的块,我们仅在最后一个块bn中应用全局注意力,而在其他块中使用窗口注意力,而非全局注意力。在每组transformer块后面加入一个卷积块,并利用残差连结将每组的结果前馈,卷积块等于组数,采用ResBottleneck。
2.4 Detail capture module
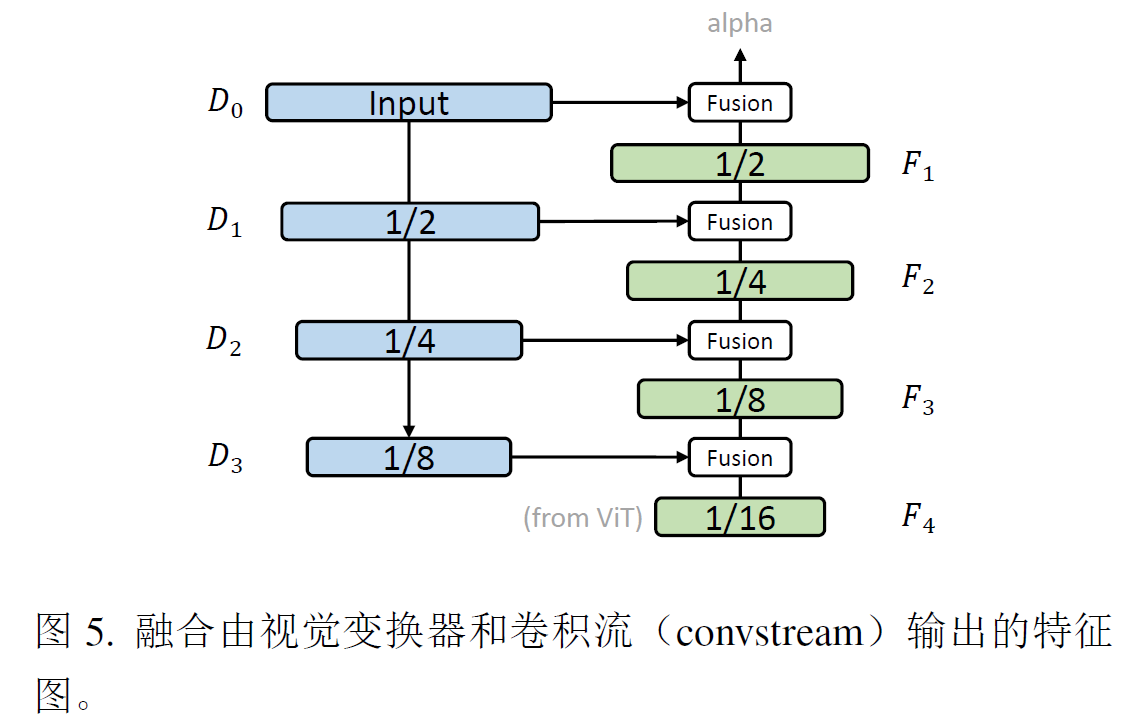
已经加入一个轻量级的细节捕捉模块,以有效的捕捉更精细的细节,该模块包括一个卷积流和一个简单的融合策略。由一些列的3x3conv组成,每一层包括一个卷积层,核大小为3,批归一化和relu,双线性插值。
2.5 Training scheme
ViT初始权重(DINO和MAE的预训练权重初始化ViTMatte-S和ViTMatte-B),并随机初始化额外部分,输入通道是4个,而不是3个,随机裁剪512x512,在两个V100上训练了100个epoch,ViTMatte-B的bs为32,ViTMatte-S的bs为20.
3.experiments
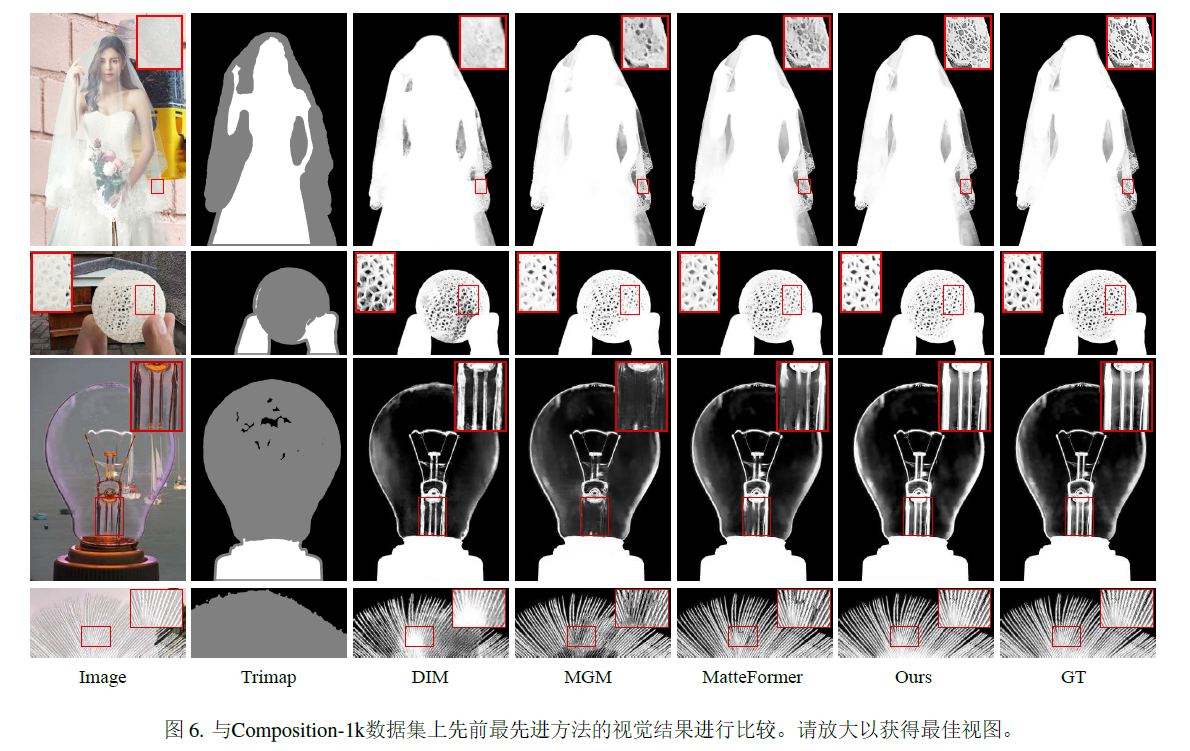

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









