







 本文介绍了最大熵模型作为分类器的思想,通过条件熵最大化来确定分类概率。最大熵模型认为对于未知事件,假设它们等可能是最优选择。文章讨论了特征函数和限制条件,以及如何使用拉格朗日乘数法解决带有约束条件的优化问题,最终求解模型参数以确定概率分布。
本文介绍了最大熵模型作为分类器的思想,通过条件熵最大化来确定分类概率。最大熵模型认为对于未知事件,假设它们等可能是最优选择。文章讨论了特征函数和限制条件,以及如何使用拉格朗日乘数法解决带有约束条件的优化问题,最终求解模型参数以确定概率分布。
先推荐两个链接,都是讲最大熵的,强的一批。
http://blog.csdn.net/erli11/article/details/24718655
http://blog.csdn.net/v_july_v/article/details/40508465
一.思路
最大熵其实也是个用来做分类器的思想,用的是条件熵最大的意义(这一点可以看到跟极大似然估计很像),最大熵模型在做分类的时候其实也是判断
P(y|x)概率的大小的,从而决定归类。但是这里的p(y|x)不是跟朴素贝叶斯一样从样本数据中获得先验概率然后计算,而是通过条件熵最大而求得
每个讲解最大熵模型的都会用这么个例子,一个色子,6面,问人掷每面的概率是多少,每个人一定会说每面都是1/6,为什么每个人会说1/6,而不是说什么1是1/3,2是1/2这样子的组合呢,因为每个人潜意识里面觉得这样子最“保险”,那么“最保险”到底代表着什么意思呢?因为均匀分布刚好是熵最大的模型,而最大熵模型认为,对于那些不知道的事件,认为他们是等可能的是最好的,也满足最大熵的情况。
二.特征函数和限制条件
看过最大熵模型的人都知道会有这么一个限制条件,
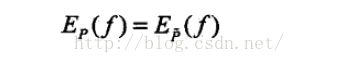
那么这个特征函数到底代表什么
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









