






可视化理解LSTM

点击下方卡片,关注“FightingCV”公众号
回复“AI”即可获得超100G人工智能的教程
点击进入→FightingCV交流群
本文利用可视化的呈现方式,带你深入理解LSTM模型结构。
最近在学习LSTM应用在时间序列的预测上,但是遇到一个很大的问题就是LSTM在传统BP网络上加上时间步后,其结构就很难理解了。
同时其输入输出数据格式也很难理解,网络上有很多介绍LSTM结构的文章,但是都不直观,对初学者是非常不友好的。我也是苦苦冥思很久,看了很多资料和网友分享的LSTM结构图形才明白其中的玄机。
本文内容如下:
一、传统的BP网络和CNN网络 二、LSTM网络 三、LSTM的输入结构 四、pytorch中的LSTM 4.1 pytorch中定义的LSTM模型 4.2 喂给LSTM的数据格式 4.3 LSTM的output格式 五、LSTM和其他网络组合
一、传统的BP网络和CNN网络
BP网络和CNN网络没有时间维,和传统的机器学习算法理解起来相差无几,CNN在处理彩色图像的3通道时,也可以理解为叠加多层,图形的三维矩阵当做空间的切片即可理解,写代码的时候照着图形一层层叠加即可。如下图是一个普通的BP网络和CNN网络。


BP网络
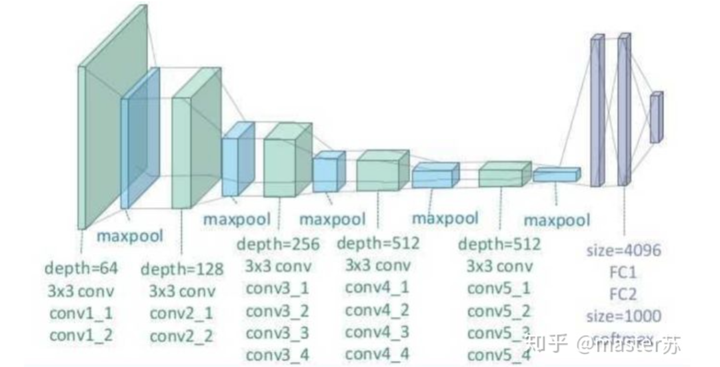

CNN网络
图中的隐含层、卷积层、池化层、全连接层等,都是实际存在的,一层层前后叠加,在空间上很好理解,因此在写代码的时候,基本就是看图写代码,比如用keras就是:
# 示例代码,没有实际意义model = Sequential()model.add(Conv2D(32, (3, 3), activation='relu')) # 添加卷积层model.add(MaxPooling2D(pool_size=(2, 2))) # 添加池化层model.add(Dropout(0.25)) # 添加dropout层 model.add(Conv2D(32, (3, 3), activation='relu')) # 添加卷积层model.add(MaxPooling2D(pool_size=(2, 2))) # 添加池化层model.add(Dropout(0.25)) # 添加dropout层 .... # 添加其他卷积操作 model.add(Flatten()) # 拉平三维数组为2维数组model.add(Dense(256, activation='relu')) 添加普通的全连接层model.add(Dropout(0.5))model.add(Dense(10, activation='softmax')) .... # 训练网络
二、LSTM网络
当我们在网络上搜索看LSTM结构的时候,看最多的是下面这张图:


RNN网络
这是RNN循环神经网络经典的结构图,LSTM只是对隐含层节点A做了改进,整体结构不变,因此本文讨论的也是这个结构的可视化问题。
中间的A节点隐含层,左边是表示只有一层隐含层的LSTM网络,所谓LSTM循环神经网络就是在时间轴上的循环利用,在时间轴上展开后得到右图。
看左图,很多同学以为LSTM是单输入、单输出,只有一个隐含神经元的网络结构,看右图,以为LSTM是多输入、多输出,有多个隐含神经元的网络结构,A的数量就是隐含层节点数量。
WTH?思维转不过来啊。这就是传统网络和空间结构的思维。
实际上,右图中,我们看Xt表示序列,下标t是时间轴,所以,A的数量表示的是时间轴的长度,是同一个神经元在不同时刻的状态(Ht),不是隐含层神经元个数。
我们知道,LSTM网络在训练时会使用上一时刻的信息,加上本次时刻的输入信息来共同训练。
举个简单的例子:在第一天我生病了(初始状态H0),然后吃药(利用输入信息X1训练网络),第二天好转但是没有完全好(H1),再吃药(X2),病情得到好转(H2),如此循环往复知道病情好转。因此,输入Xt是吃药,时间轴T是吃多天的药,隐含层状态是病情状况。因此我还是我,只是不同状态的我。
实际上,LSTM的网络是这样的:


LSTM网络结构
上面的图表示包含2个隐含层的LSTM网络,在T=1时刻看,它是一个普通的BP网络,在T=2时刻看也是一个普通的BP网络,只是沿时间轴展开后,T=1训练的隐含层信息H,C会被传递到下一个时刻T=2,如下图所示。上图中向右的五个常常的箭头,所指的也是隐含层状态在时间轴上的传递。
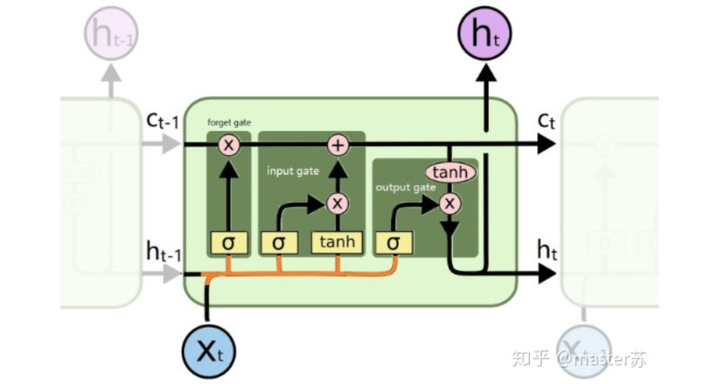

注意,图中H表示隐藏层状态,C是遗忘门,后面会讲解它们的维度。
三、LSTM的输入结构
为了更好理解LSTM结构,还必须理解LSTM的数据输入情况。仿照3通道图像的样子,在加上时间轴后的多样本的多特征的不同时刻的数据立方体如下图所示:
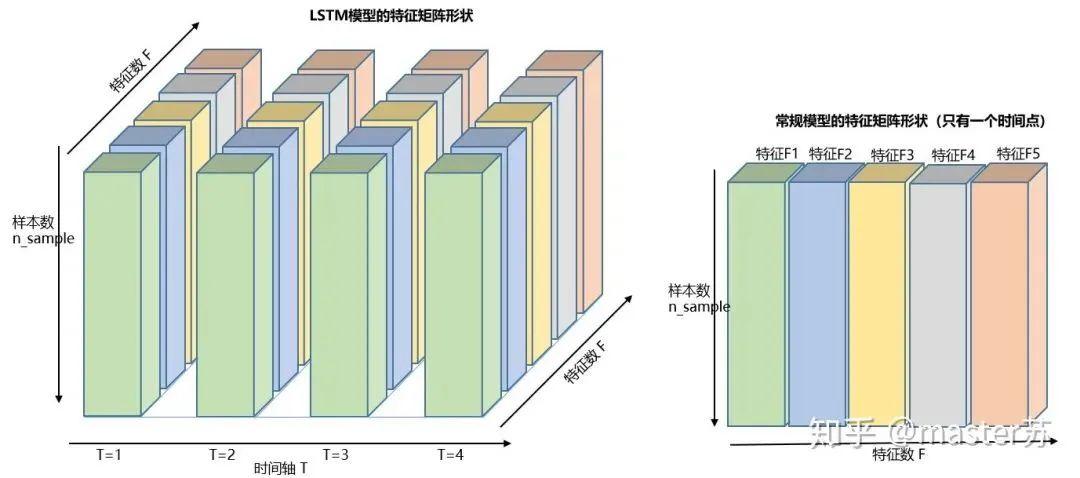

三维数据立方体
右边的图是我们常见模型的输入,比如XGBOOST,lightGBM,决策树等模型,输入的数据格式都是这种(N*F)的矩阵,而左边是加上时间轴后的数据立方体,也就是时间轴上的切片,它的维度是(N*T*F),第一维度是样本数,第二维度是时间,第三维度是特征数,如下图所示:


这样的数据立方体很多,比如天气预报数据,把样本理解成城市,时间轴是日期,特征是天气相关的降雨风速PM2.5等,这个数据立方体就很好理解了。在NLP里面,一句话会被embedding成一个矩阵,词与词的顺序是时间轴T,索引多个句子的embedding三维矩阵如下图所示:
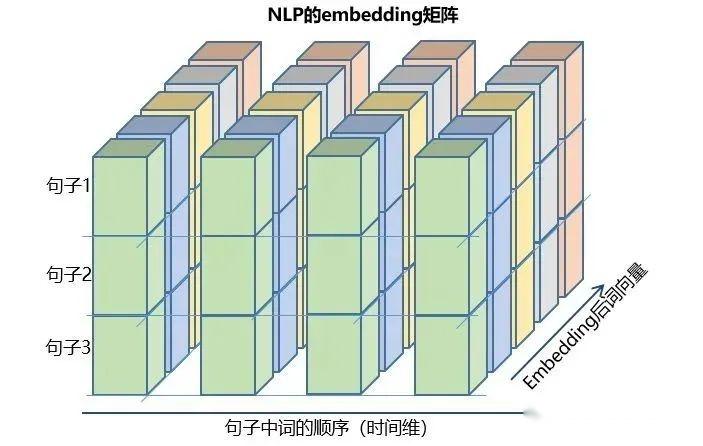

四、pytorch中的LSTM
4.1 pytorch中定义的LSTM模型
pytorch中定义的LSTM模型的参数如下
classtorch.nn.LSTM(*args,**kwargs)参数有: input_size:x的特征维度 hidden_size:隐藏层的特征维度 num_layers:lstm隐层的层数,默认为1 bias:False则bihbih=0和bhhbhh=0. 默认为True batch_first:True则输入输出的数据格式为 (batch, seq, feature) dropout:除最后一层,每一层的输出都进行dropout,默认为: 0 bidirectional:True则为双向lstm默认为False
结合前面的图形,我们一个个看。
(1)input_size:x的特征维度,就是数据立方体中的F,在NLP中就是一个词被embedding后的向量长度,如下图所示:


(2)hidden_size:隐藏层的特征维度(隐藏层神经元个数),如下图所示,我们有两个隐含层,每个隐藏层的特征维度都是5。注意,非双向LSTM的输出维度等于隐藏层的特征维度。
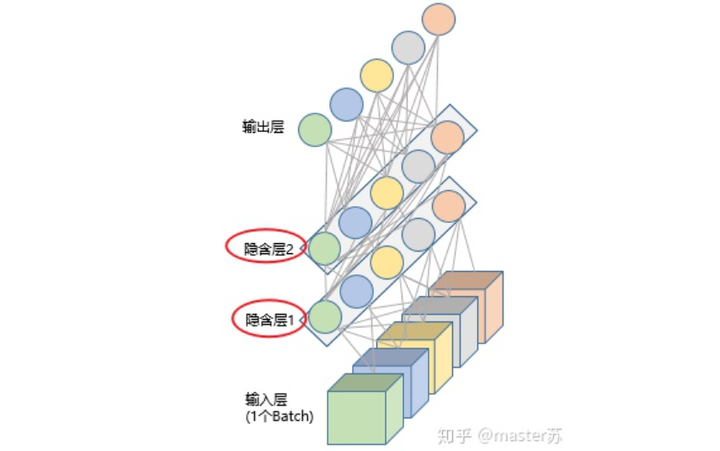

(3)num_layers:lstm隐层的层数,上面的图我们定义了2个隐藏层。
(4)batch_first:用于定义输入输出维度,后面再讲。
(5)bidirectional:是否是双向循环神经网络,如下图是一个双向循环神经网络,因此在使用双向LSTM的时候我需要特别注意,正向传播的时候有(Ht, Ct),反向传播也有(Ht', Ct'),前面我们说了非双向LSTM的输出维度等于隐藏层的特征维度,而双向LSTM的输出维度是隐含层特征数*2,而且H,C的维度是时间轴长度*2。


4.2 喂给LSTM的数据格式
pytorch中LSTM的输入数据格式默认如下:
input(seq_len, batch, input_size)参数有: seq_len:序列长度,在NLP中就是句子长度,一般都会用pad_sequence补齐长度 batch:每次喂给网络的数据条数,在NLP中就是一次喂给网络多少个句子 input_size:特征维度,和前面定义网络结构的input_size一致。
前面也说到,如果LSTM的参数 batch_first=True,则要求输入的格式是:
input(batch, seq_len, input_size)
刚好调换前面两个参数的位置。其实这是比较好理解的数据形式,下面以NLP中的embedding向量说明如何构造LSTM的输入。
之前我们的embedding矩阵如下图:


如果把batch放在第一位,则三维矩阵的形式如下:


其转换过程如下图所示:
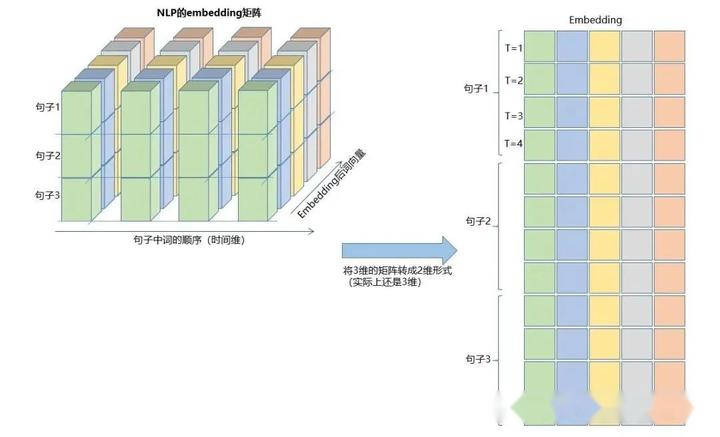

看懂了吗,这就是输入数据的格式,是不是很简单。
LSTM的另外两个输入是 h0和 c0,可以理解成网络的初始化参数,用随机数生成即可。
h0(num_layers * num_directions, batch, hidden_size)c0(num_layers * num_directions, batch, hidden_size)参数: num_layers:隐藏层数 num_directions:如果是单向循环网络,则num_directions=1,双向则num_directions=2 batch:输入数据的batch hidden_size:隐藏层神经元个数
注意,如果我们定义的input格式是:
input(batch, seq_len, input_size)
则H和C的格式也是要变的:
h0(batc,num_layers * num_directions, h, hidden_size)c0(batc,num_layers * num_directions, h, hidden_size)
4.3 LSTM的output格式
LSTM的输出是一个tuple,如下:
output,(ht,ct)=net(input) output: 最后一个状态的隐藏层的神经元输出 ht:最后一个状态的隐含层的状态值 ct:最后一个状态的隐含层的遗忘门值
output的默认维度是:
output(seq_len, batch, hidden_size * num_directions)ht(num_layers * num_directions, batch, hidden_size)ct(num_layers * num_directions, batch, hidden_size)
和input的情况类似,如果我们前面定义的input格式是:
input(batch,seq_len,input_size)
则ht和ct的格式也是要变的:
ht(batc,num_layers*num_directions,h,hidden_size)ct(batc,num_layers*num_directions,h,hidden_size)
说了这么多,我们回过头来看看ht和ct在哪里,请看下图:


output在哪里?请看下图:


五、LSTM和其他网络组合
还记得吗,output的维度等于隐藏层神经元的个数,即hidden_size,在一些时间序列的预测中,会在output后,接上一个全连接层,全连接层的输入维度等于LSTM的hidden_size,之后的网络处理就和BP网络相同了,如下图:


用pytorch实现上面的结构:
import torchfrom torch import nn class RegLSTM(nn.Module): def __init__(self): super(RegLSTM, self).__init__() # 定义LSTM self.rnn = nn.LSTM(input_size, hidden_size, hidden_num_layers) # 定义回归层网络,输入的特征维度等于LSTM的输出,输出维度为1 self.reg = nn.Sequential( nn.Linear(hidden_size, 1) ) def forward(self, x): x, (ht,ct) = self.rnn(x) seq_len, batch_size, hidden_size= x.shape x = y.view(-1, hidden_size) x = self.reg(x) x = x.view(seq_len, batch_size, -1) return x
当然,有些模型则是将输出当做另一个LSTM的输入,或者使用隐藏层ht,ct的信息进行建模,不一而足。
好了,以上就是我对LSTM的一些学习心得,看完记得关注点赞。
参考链接:
https://zhuanlan.zhihu.com/p/94757947
https://zhuanlan.zhihu.com/p/59862381
https://zhuanlan.zhihu.com/p/36455374
https://www.zhihu.com/question/41949741/answer/318771336
https://blog.csdn.net/android_ruben/article/details/80206792
链接:
https://zhuanlan.zhihu.com/p/139617364
本文仅作学术交流,如有侵权,请联系后台删除。
往期回顾
基础知识
【CV知识点汇总与解析】|损失函数篇
【CV知识点汇总与解析】|激活函数篇
【CV知识点汇总与解析】| optimizer和学习率篇
【CV知识点汇总与解析】| 正则化篇
【CV知识点汇总与解析】| 参数初始化篇
【CV知识点汇总与解析】| 卷积和池化篇 (超多图警告)
最新论文解析
CVPR2022 | Attention机制是为了找最相关的item?中科大团队反其道而行之!
ECCV2022 Oral | SeqTR:一个简单而通用的 Visual Grounding网络
如何训练用于图像检索的Vision Transformer?Facebook研究员解决了这个问题!
ICLR22 Workshop | 用两个模型解决一个任务,意大利学者提出维基百科上的高效检索模型
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
MM2022|兼具低级和高级表征,百度提出利用显式高级语义增强视频文本检索
MM2022 | 用StyleGAN进行数据增强,真的太好用了
MM2022 | 在特征空间中的多模态数据增强方法
ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
ECCV2022|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
CVPR2022|比VinVL快一万倍!人大提出交互协同的双流视觉语言预训练模型COTS,又快又好!
CVPR2022 Oral|通过多尺度token聚合分流自注意力,代码已开源
CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索

分享
分享
分享
分享















 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









