







深度优先遍历
深度优先遍历(DepthFirstSearch),也有称为深度优先搜索,简称为DFS。

约定右手原则:在没有碰到重复顶点的情况下,分叉路口始终是向右手边走,每路过一个顶点就做一个记号。
如果再细心观察,你会发现整个遍历过程就像是一棵树的前序遍历!

广度优先遍历
广度优先遍历(BreadthFirstSearch),又称为广度优先搜索,简称BFS。
代码:
<span style="font-family:Microsoft YaHei;font-size:14px;">/*邻接矩阵的广度遍历算法*/
#include "stdio.h"
#include "stdlib.h"
#define OK 1
#define ERROR 1
#define FALSE 0
#define TRUE 1
typedef int Status; //Status是函数的类型,其值是函数结果状态代码
typedef int Boolean;//Boolean是布尔类型,其值是TRUE或FALSE
//图的邻接矩阵存储结构
typedef char VertexType;//顶点类型应由用户定义
typedef int EdgeType;//边上的权值类型应由用户定义
#define MAXVEX 100 //最大顶点数,应由用户定义
typedef struct
{
VertexType vexs[MAXVEX];//顶点表
EdgeType arc[MAXVEX][MAXVEX];//邻接矩阵,可看做边表
int numVertexes,numEdge;//图中当前的顶点数和边数
}MGraph;
//***********用到的队列结构与函数***********
//链队列的结构
typedef int QElemType;//这里QElemType的类型假设为int
typedef struct QNode //结点结构
{
QElemType data;
struct QNode *next;
}QNode,*QueuePtr;
typedef struct //队列的链表结构
{
QueuePtr front,rear;//队头、队尾指针
}LinkQueue;
//初始化队列:
Status initQueue(LinkQueue *q)
{
q->front = q->rear = (QueuePtr)malloc(sizeof(QNode));
if(!q->front)
return ERROR;
q->front->next = NULL;
return OK;
}
//入队:插入元素e为q的新的队尾元素
Status EnQueue(LinkQueue *q,QElemType e)
{
QueuePtr s = (QueuePtr)malloc(sizeof(QNode));
if(!s)//存储分配失败
return ERROR;
s->data = e;
s->next = NULL;
q->rear->next = s;
q->rear = s;
return OK;
}
//出队
//若队列不为空,删除q的队头元素,用e返回其值,并返回OK,否则返回ERROR
Status DeQueue(LinkQueue *q,QElemType *e)
{
QueuePtr p;
if(q->front==q->rear)
return ERROR;
p = q->front->next;
*e = p->data;
q->front->next = p->next;
if(q->rear==p)//若队头是队尾,则删除后将rear指向头结点
q->rear = q->front;
free(p);
return OK;
}
//判断是否为空队列,若为空队列则返回1,否则返回0
Status QueueEmpty(LinkQueue q)
{
if(q.front == q.rear)
return 1;
return 0;
}
//******************************************************
//建立无向图的邻接矩阵表示
void CreatMGraph(MGraph *G)
{
int i,j,k;
printf("输入顶点数和边数:\n");
scanf("%d,%d",&G->numVertexes,&G->numEdge);//输入顶点数和边数
getchar();
printf("输入顶点字符:\n");
for(i=0;i<G->numVertexes;i++) //读入顶点信息,建立顶点表
scanf("%c",&G->vexs[i]);
for(i=0;i<G->numVertexes;i++)
for(j=0;j<G->numVertexes;j++)
G->arc[i][j] =0;//邻接矩阵初始化
for(k=0;k<G->numEdge;k++)//读入numEdges条边,建立邻接矩阵
{
printf("输入边(vi,vj)上的下标i,下标j:\n");
scanf("%d,%d",&i,&j);
G->arc[i][j]=1;
G->arc[j][i]=G->arc[i][j];//因为是无向图,矩阵对称
}
}
Boolean visited[MAXVEX];//访问标记的数组
//邻接矩阵的深度优先递归算法
void DFS(MGraph G,int i)
{
int j;
visited[i] = TRUE;
printf("%c ",G.vexs[i]);
for(j=0;j<G.numVertexes;j++)
if(G.arc[i][j]==1 && !visited[j])
DFS(G,j);//对未访问的邻接顶点递归调用
}
//邻接矩阵的深度遍历算法
void DFSTraverse(MGraph G)
{
int i;
for(i=0;i<G.numVertexes;i++)
visited[i]=FALSE;//初始所有顶点状态都是未被访问过
for(i=0;i<G.numVertexes;i++)
if(!visited[i])
DFS(G,i);
}
//邻接矩阵的广度遍历算法
void BFSTraverse(MGraph G)
{
int i,j;
LinkQueue Q;
for(i=0;i<G.numVertexes;i++)
{
visited[i] = FALSE;
}
initQueue(&Q); //初始化一辅助用的队列
for(i=0;i<G.numVertexes;i++)//对每一个顶点做循环
{
if(!visited[i]) //若是未被访问过就处理
{
visited[i] = TRUE; //设置当前顶点访问过
printf("%c ",G.vexs[i]);//打印顶点
EnQueue(&Q,i); //将此顶点入队列
while(!QueueEmpty(Q))//若当前顶点不为空
{
DeQueue(&Q,&i); //将队中元素出队列,赋值给i
for(j=0;j<G.numVertexes;j++)
{
//判断其他顶点若与当前顶点存在边且未被访问过
if(G.arc[i][j] ==1 && !visited[j])
{
visited[j] = TRUE;//将找到的此顶点标记为已访问
printf("%c ",G.vexs[j]);//打印此顶点
EnQueue(&Q,j);//将找到的此顶点入队列
}
}
}
}
}
}
int main()
{
MGraph G;
CreatMGraph(&G);
printf("\n深度遍历:");
DFSTraverse(G);
printf("\n广度遍历:");
BFSTraverse(G);
return 0;
}</span>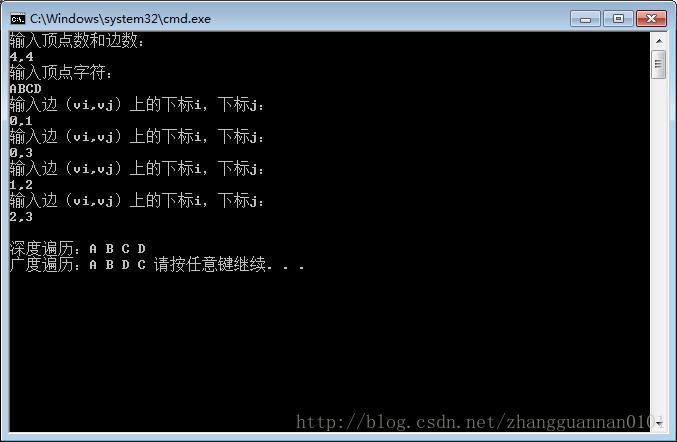















 4240
4240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









