







1,概述
首次看多目标检测的文章。文中指出多目标检测有两个框架:1)BoW,2)DL。BoW还没看过。当然本文用的是DL中的CNN(好处多多)。
首先,这篇文章是在程明明提出BING以后的一次应用。本文提出了一种HCP的框架结构(Hypotheses-CNN-Pooling),检测方法是利用BING和HS提取提取hypotheses作为CNN的输入,每个hypotheses产生一个c维的预测结果,然后通过max pooling得到最终的多目标检测。
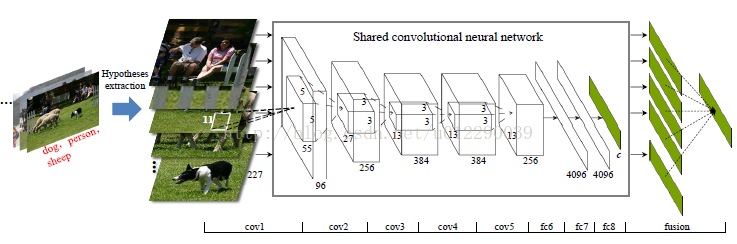
2,训练
HCP的框架结构与“Imagenetclassification with deep convolutional neural networks”提到的结构相似。
Shared cnn的训练分两个部分:
1)initializationof HCP
这一部分又分为两步:
第一步:pre-trainingon single-label image set
对整幅图片resize,pre-train,提取patches扔到CNN中去训练;
第二步:image-tine-tuningon multi-label image set
把整幅图片(没有crop)resize以后作为训练样本得到c维的预测结果pi = [pi1; pi2; :::pic],label vecter为yi = [yi1; yi2;:::yic],The ground-truth probability vector定义为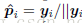
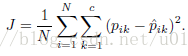
作者提到这一步很关键(I-FT),如果没有效果下降很明显。至于原因,3.2中有提到,多目标与单目标有很大的区别。
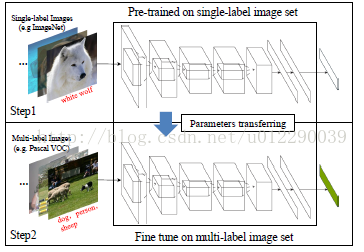
2)Hypotheses-fine-tuning
这一部分(H-FT)也很重要,因为对于去噪很关键。利用BING和HS得到的Hypotheses产生多个c维向量后max pool得到预测结果后利用第一部分第二步中的loss function微调
3,优点
1) nobounding box annotation 文中的训练采用的是label,costly少泛化能力高
2) 去噪能力好(前面提到)。
3) Hypotheses数量任意,没有明确的标签要求。
4) Sharedcnn可以用single label imageset微调,解决多目标训练效率低的问题
5) 输出即结果















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









