






进程退出意味着进程生命期的结束,系统资源被回收,进程从操作系统环境中销毁。进程异常退出是进程在运行过程中被意外终止,从而导致进程本来应该继续执行的任务无法完成。
首先我们来看导致进程异常退出的这两类情况:
●第一类:向进程发送信号导致进程异常退出;
●第二类:代码错误导致进程运行时异常退出。
第一类:向进程发送信号导致进程异常退出
信号:
UNIX 系统中的信号是系统响应某些状况而产生的事件,是进程间通信的一种方式。信号可以由一个进程发送给另外进程,也可以由核发送给进程。
信号处理程序:
信号处理程序是进程在接收到信号后,系统对信号的响应。根据具体信号的涵义,相应的默认信号处理程序会采取不同的信号处理方式:
●终止进程运行,并且产生 core dump 文件。
●终止进程运行。
●忽略信号,进程继续执行。
●暂停进程运行。
●如果进程已被暂停,重新调度进程继续执行。
前两种方式会导致进程异常退出,是本文讨论的范围。实际上,大多数默认信号处理程序都会终止进程的运行。
在进程接收到信号后,如果进程已经绑定自定义的信号处理程序,进程会在用户态执行自定义的信号处理程序;反之,内核会执行默认信号程序终止进程运行,导致进程异常退出。
图1.默认信号处理程序终止进程运行
所以,通过向进程发送信号可以触发默认信号处理程序,默认信号处理程序终止进程运行。在 UNIX 环境中我们有三种方式将信号发送给目标进程,导致进程异常退出。
方式一:调用函数 kill() 发送信号
我们可以调用函数 kill(pid_t pid, int sig) 向进程 ID 为 pid 的进程发送信号 sig。这个函数的原型是:
#include
#include
int kill(pid_t pid, int sig);
调用函数 kill() 后,进程进入内核态向目标进程发送指定信号;目标进程在接收到信号后,默认信号处理程序被调用,进程异常退出。
清单 1. 调用 kill() 函数发送信号
/* sendSignal.c, send the signal ‘ SIGSEGV ’ to specific process*/
#include
#include
int main(int argc, char* argv[])
{
char* pid = argv[1];
int PID = atoi(pid);
kill(PID, SIGSEGV);
return 0;
}
上面的代码片段演示了如何调用 kill() 函数向指定进程发送 SIGSEGV 信号。编译并且运行程序:
[root@machine ~]# gcc -o sendSignal sendSignal.c
[root@machine ~]# top &
[1] 22055
[root@machine ~]# ./sendSignal 22055
[1]+ Stopped top
[root@machine ~]# fg %1
top
Segmentation fault (core dumped)
上面的操作中,我们在后台运行 top,进程 ID 是 22055,然后运行 sendSignal 向它发送 SIGSEGV 信号,导致 top 进程异常退出,产生 core dump 文件。
方式二:运行 kill 命令发送信号
用户可以在命令模式下运行 kill 命令向目标进程发送信号,格式为:
kill SIG*** PID
在运行 kill 命令发送信号后,目标进程会异常退出。这也是系统管理员终结某个进程的最常用方法,类似于在 Windows 平台通过任务管理器杀死某个进程。
在实现上,kill 命令也是调用 kill 系统调用函数来发送信号。所以本质上,方式一和方式二是一样的。
操作演示如下:
[root@machine ~]# top &
[1] 22810
[root@machine ~]# kill -SIGSEGV 22810
[1]+ Stopped top
[root@machine ~]# fg %1
top
Segmentation fault (core dumped)
方式三:在终端使用键盘发送信号
用户还可以在终端用键盘输入特定的字符(比如 control-C 或 control-\)向前台进程发送信号,终止前台进程运行。常见的中断字符组合是,使用 control-C 发送 SIGINT 信号,使用 control-\ 发送 SIGQUIT 信号,使用 control-z 发送 SIGTSTP 信号。
在实现上,当用户输入中断字符组合时,比如 control-C,终端驱动程序响应键盘输入,并且识别 control-C 是信号 SIGINT 的产生符号,然后向前台进程发送 SIGINT 信号。当前台进程再次被调用时就会接收到 SIGINT 信号。
使用键盘中断组合符号发送信号演示如下:
[root@machine ~]# ./loop.sh ( 注释:运行一个前台进程,任务是每秒钟打印一次字符串 )
i’m looping …
i’m looping …
i’m looping … ( 注释:此时,用户输入 control-C)
[root@machine ~]# ( 注释:接收到信号后,进程退出 )
对这类情况的思考
这类情况导致的进程异常退出,并不是软件编程错误所导致,而是进程外部的异步信号所致。但是我们可以在代码编写中做的更好,通过调用 signal 函数绑定信号处理程序来应对信号的到来,以提高软件的健壮性。
signal 函数的原型:
#include
void (*signal(int sig, void (*func)(int)))(int);
signal 函数将信号 sig 和自定义信号处理程序绑定,即当进程收到信号 sig 时自定义函数 func 被调用。如果我们希望软件在运行时屏蔽某个信号,插入下面的代码,以达到屏蔽信号 SIGINT 的效果:
(void)signal(SIGINT, SIG_IGN);
执行这一行代码后,当进程收到信号 SIGINT 后,进程就不会异常退出,而是会忽视这个信号继续运行。
更重要的场景是,进程在运行过程中可能会创建一些临时文件,我们希望进程在清理这些文件后再退出,避免遗留垃圾文件,这种情况下我们也可以调用 signal 函数实现,自定义一个信号处理程序来清理临时文件,当外部发送信号要求进程终止运行时,这个自定义信号处理程序被调用做清理工作。代码清单 2 是具体实现。
清单 2. 调用 signal 函数绑定自定义信号处理程序
/* bindSignal.c */
#include
#include
#include
void cleanTask(int sig) {
printf( "Got the signal, deleting the tmp file\n" );
if( access( "/tmp/temp.lock", F_OK ) != -1 ) {
if( remove( "/tmp/temp.lock" ) != 0 )
perror( "Error deleting file" );
else
printf( "File successfully deleted\n" );
}
printf( "Process existing...\n" );
exit(0);
}
int main() {
(void) signal( SIGINT, cleanTask );
FILE* tmp = fopen ( "/tmp/temp.lock", "w" );
while(1) {
printf( "Process running happily\n" );
sleep(1);
}
if( tmp )
remove( "/tmp/temp.lock" );
}
运行程序:
[root@machine ~]# ./bindSignal
Process running happily
Process running happily
Process running happily ( 注释:此时,用户输入 control-C)
Got the signal, deleting the tmp file ( 注释:接收到信号后,cleanTask 被调用 )
File successfully deleted ( 注释:cleanTask 删除临时文件 )
Process existing... ( 注释:进程退出 )
第二类:编程错误导致进程运行时异常退出
相比于第一类情况,第二类情况在软件开发过程中是常客,是编程错误,进程运行过程中非法操作引起的。
操作系统和计算机硬件为应用程序的运行提供了硬件平台和软件支持,为应用程序提供了平台虚拟化,使进程运行在自己的进程空间。在进程看来,它自身独占整台系统,任何其它进程都无法干预,也无法进入它的进程空间。
但是操作系统和计算机硬件又约束每个进程的行为,使进程运行在用户态空间,控制权限,确保进程不会破坏系统资源,不会干涉进入其它进程的空间,确保进程合法访问内存。当进程尝试突破禁区做非法操作时,系统会立刻觉察,并且终止进程运行。
所以,第二类情况导致的进程异常退出,起源于进程自身的编程错误,错误的编码执行非法操作,操作系统和硬件制止它的非法操作,并且让进程异常退出。
在实现上,操作系统和计算机硬件通过异常和异常处理函数来阻止进程做非法操作。
异常和异常处理函数
当进程执行非法操作时,计算机会抛出处理器异常,系统执行异常处理函数以响应处理器异常,异常处理函数往往会终止进程运行。
广义的异常包括软中断 (soft interrupts) 和外设中断 (I/O interrupts) 。外设中断是系统外围设备发送给处理器的中断,它通知处理器 I/O 操作的状态,这种异常是外设的异步异常,与具体进程无关,所以它们不会造成进程的异常退出。本文讨论的异常是指 soft interrupts,是进程非法操作所导致的处理器异常,这类异常是进程执行非法操作所产生的同步异常,比如内存保护异常,除 0 异常,缺页异常等等。
处理器异常有很多种,系统为每个异常分配异常号,每个异常有相对应的异常处理函数。以 x86 处理器为例,除 0 操作产生 DEE 异常 (Divide Error Exception),异常号是 0;内存非法访问产生 GPF 异常 (General Protection Fault),异常号是 13,而缺页 (page fault) 异常的异常号是 14。当异常出现时,处理器挂起当前进程,读取异常号,然后执行相应的异常处理函数。如果异常是可修复,比如内存缺页异常,异常处理函数会修复系统错误状态,清除异常,然后重新执行一遍被中断的指令,进程继续运行;如果异常无法修复,比如内存非法访问或者除 0 操作,异常处理函数会终止进程运行。
图 2. 异常处理函数终止进程运行
实例以及分析
实例一:内存非法访问
这类问题中最常见的就是内存非法访问。内存非法访问在 UNIX 平台即 segmentation fault,在 Windows 平台这类错误称为 Access violation。
内存非法访问是指:进程在运行时尝试访问尚未分配(即,没有将物理内存映射进入进程虚拟内存空间)的内存,或者进程尝试向只读内存区域写入数据。当进程执行内存非法访问操作时,内存管理单元 MMU 会产生内存保护异常 GPF(General Protection Fault),异常号是 13。系统会立刻暂停进程的非法操作,并且跳转到 GPF 的异常处理程序,终止进程运行。
这种编程错误在编译阶段编译器不会报错,是运行时出现的错误。清单 3 是内存非法访问的一个简单实例,进程在执行第 5 行代码时执行非法内存访问,异常处理函数终止进程运行。
清单 3. 内存非法访问实例 demoSegfault.c
#include
int main()
{
char* str = "hello";
str[0] = 'H';
return 0;
}
编译并运行:
[root@machine ~]# gcc demoSegfault.c -o demoSegfault
[root@machine ~]# ./demoSegfault
Segmentation fault (core dumped)
[root@machine ~]# gdb demoSegfault core.24065
( 已省略不相干文本 )
Core was generated by `./demoSegfault'.
Program terminated with signal 11, Segmentation fault.
分析:实例中,字符串 str 是存储在内存只读区的字符串常量,而第 5 行代码尝试更改只读区的字符,所以这是内存非法操作。
进程从开始执行到异常退出经历如下几步:
1、进程执行第 5 行代码,尝试修改只读内存区的字符;
2、内存管理单元 MMU 检查到这是非法内存操作,产生保护内存异常 GPF,异常号 13;
3、处理器立刻暂停进程运行,跳转到 GPF 的异常处理函数,异常处理函数终止进程运行;
4、进程 segmentation fault,并且产生 core dump 文件。GDB 调试结果显示,进程异常退出的原因是 segmentation fault。
实例二:除 0 操作
实例二是除 0 操作,软件开发中也会引入这样的错误。当进程执行除 0 操作时,处理器上的浮点单元 FPU(Floating-point unit) 会产生 DEE 除 0 异常 (Divide Error Exception),异常号是 0。
清单 4. 除 0 操作 divide0.c
#include
int main()
{
int a = 1, b = 0, c;
printf( "Start running\n" );
c = a/b ;
printf( "About to quit\n" );
}
编译并运行:
[root@machine ~]# gcc -o divide0 divide0.c
[root@machine ~]# ./divide0 &
[1] 1229
[root@machine ~]# Start running
[1]+ Floating point exception(core dumped) ./divide0
[root@xbng103 ~]# gdb divide0 /corefiles/core.1229
( 已省略不相干文本 )
Core was generated by `./divide0'.
Program terminated with signal 8, Arithmetic exception.
分析:实例中,代码第 7 行会执行除 0 操作,导致异常出现,异常处理程序终止进程运行,并且输出错误提示:Floating point exception。
异常处理函数内幕
异常处理函数在实现上,是通过向挂起进程发送信号,进而通过信号的默认信号处理程序终止进程运行,所以异常处理函数是“间接”终止进程运行。详细过程如下:
1、进程执行非法指令或执行错误操作;
2、非法操作导致处理器异常产生;
3、系统挂起进程,读取异常号并且跳转到相应的异常处理函数;
a、异常处理函数首先查看异常是否可以恢复。如果无法恢复异常,异常处理函数向进程发送信号。发送的信号根据异常类型而定,比如内存保护异常 GPF 相对应的信号是 SIGSEGV,而除 0 异常 DEE 相对应的信号是 SIGFPE;
b、异常处理函数调用内核函数 issig() 和 psig() 来接收和处理信号。内核函数 psig() 执行默认信号处理程序,终止进程运行;
3、进程异常退出。
在此基础上,我们可以把图2进一步细化如下:
图3. 异常处理函数终止进程运行(细化)
异常处理函数执行时会检查异常号,然后根据异常类型发送相应的信号。
再来看一下实例一(代码清单 3)的运行结果:
[root@machine ~]# ./demoSegfault
Segmentation fault (core dumped)
[root@machine ~]# gdb demoSegfault core.24065
( 已省略不相干文本 )
Core was generated by `./demoSegfault'.
Program terminated with signal 11, Segmentation fault.
运行结果显示进程接收到信号 11 后异常退出,在 signal.h 的定义里,11 就是 SIGSEGV。MMU 产生内存保护异常 GPF(异常号 13)时,异常处理程序发送相应信号 SIGSEGV,SIGSEGV 的默认信号处理程序终止进程运行。
再来看实例二(代码清单 4)的运行结果
[root@machine ~]# ./divide0 &
[1] 1229
[root@machine ~]# Start running
[1]+ Floating point exception(core dumped) ./divide0
[root@xbng103 ~]# gdb divide0 /corefiles/core.1229
( 已省略不相干文本 )
Core was generated by `./divide0'.
Program terminated with signal 8, Arithmetic exception.
分析结果显示进程接收到信号 8 后异常退出,在 signal.h 的定义里,8 就是信号 SIGFPE。除 0 操作产生异常(异常号 0),异常处理程序发送相应信号 SIGFPE 给挂起进程,SIGFPE 的默认信号处理程序终止进程运行。
“信号”是进程异常退出的直接原因
信号与进程异常退出有着紧密的关系:第一类情况是因为外部环境向进程发送信号,这种情况下发送的信号是异步信号,信号的到来与进程的运行是异步的;第二类情况是进程非法操作触发处理器异常,然后异常处理函数在内核态向进程发送信号,这种情况下发送的信号是同步信号,信号的到来与进程的运行是同步的。这两种情况都有信号产生,并且最终都是信号处理程序终止进程运行。它们的区别是信号产生的信号源不同,前者是外部信号源产生异步信号,后者是进程自身作为信号源产生同步信号。
所以,信号是进程异常退出的直接原因。当进程异常退出时,进程必然接收到了信号。
避免和调试进程异常退出
建议
软件开发过程中,我们应当避免进程异常退出,针对导致进程异常退出的这两类问题,对软件开发者的几点建议:
1、通常情况无需屏蔽外部信号。信号作为进程间的一种通信方式,异步信号到来意味着外部要求进程的退出;
2、绑定自定义信号处理程序做清理工作,当外部信号到来时,确保进程异常退出前,自定义信号处理程序被调用做清理工作,比如删除创建的临时文件。
3、针对第二类情况,编程过程中确保进程不要做非法操作,尤其是在访问内存时,确保内存已经分配给进程(映射入进程虚拟地址空间),不要向只读区写入数据。
问题调试和定位
进程异常退出时,操作系统会产生 core dump 文件,cored ump 文件是进程异常退出前内存状态的快照,运行 GDB 分析 core dump 文件可以帮助调试和定位问题。
首先,分析 core dump 查看导致进程异常退出的具体信号和退出原因。
使用 GDB 调试实例一(代码清单 3)的分析结果如下:
[root@machine ~]# gdb demoSegfault core.24065
( 已省略不相干文本 )
Core was generated by `./demoSegfault'.
Program terminated with signal 11, Segmentation fault.
分析结果显示,终止进程运行的信号是 11,SIGSEGV,原因是内存非法访问。
然后,定位错误代码。
在 GDB 分析 core dump 时,输入“bt”指令打印进程退出时的代码调用链,即 backtrace,就可以定位到错误代码。
用 gcc 编译程序时加入参数 -g 可以生成符号文件,帮助调试。
重新编译、执行实例一,并且分析 core dump 文件,定位错误代码:
[root@machine ~]# gcc -o demoSegfault demoSegfault.c -g
[root@machine ~]# ./demoSegfault &
[1] 28066
[1]+ Segmentation fault (core dumped) ./demoSegfault
[root@machine ~]# gdb demoSegfault /corefiles/core.28066
( 已省略不相干文本 )
Core was generated by `./demoSegfault'.
Program terminated with signal 11, Segmentation fault.
#0 0x0804835a in main () at demoSegfault.c:5
5 str[0] = 'H';
(gdb) bt
#0 0x0804835a in main () at demoSegfault.c:5
(gdb)
在加了参数 -g 编译后,我们可以用 gdb 解析出更多的信息帮助我们调试。在输入“bt”后,GDB 输出提示错误出现在第 5 行。
最后,在定位到错误代码行后,就可以很快知道根本原因,并且修改错误代码。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/m0_74282605/article/details/130093766
1-内核错误处理方式
当内核出现致命错误时,只要cpu还能正常运行,那么最重要的就是向用户输出详细的错误信息,以及保存问题出现时的错误现场。以上致命错误可包含以下两种类型:
-
(1)硬件能检测到的错误,如非法内存访问,非法指令等,此时cpu会触发异常,并进入异常处理流程。在异常处理流程中会触发oops或panic。
-
(2)内核代码进入某些代码无法处理的异常分支,此时程序若继续执行可能会导致无法预知的后果,此时相关的代码会主动进入oops或panic。
其中panic的含义为惊恐、恐慌,即内核将无法继续进行,它会根据配置确定是否dump crash内存,向关心panic事件的模块发送notifier通知,以及打印panic相关的系统信息,最后将系统挂起或重启。
oops的严重程度低于panic,因此在一般情况下其只是输出相关的错误信息,并退出进程,而并不会挂起内核。但是若oops发生在中断上下文,或内核配置了panic_on_oops选项,则它也会进入panic。
2-arm64异常信息寄存器
对于arm64架构,若cpu由于内存访问错误等原因进入异常,则可通过esr寄存器获取异常原因,并通过far寄存器获取异常内存的地址信息。其中esr寄存器定义如下:
上图中EC表示异常类型,如以下为其中的一些典型取值:
-
(1)b100000:来自低异常等级的指令错误,如用户态的非法指令
-
(2)b100001:当前异常等级的指令错误
-
(3)b100010:pc对齐错误
-
(4)b100100:来自低异常等级的data abort异常,如用户态的内存异常
-
(5)b100101:当前异常等级的data abort异常
-
(6)b100110:栈指针sp对齐错误
-
(7)b101111:serror中断,它属于异步异常,一般来自外部abort,如内存访问总线时产生的abort异常等
IL表示异常发生时的指令长度,其取值如下:
-
(1)0:表示16位的thumb指令长度
-
(2)1:表示32位的arm指令长度
ISS表示每种类型的具体原因,它的取值会根据EC的不同而不同,如以EC为data abort为例,其相应的ISS定义如下(具体含义可参考armv8 trm):
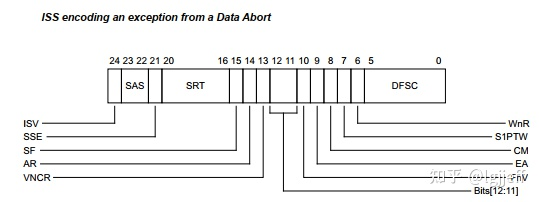
其中DFSC(data fault status code)用于给出data abort相关的信息,以下为其部分定义:
另外对于data abort类型异常,abort地址对于分析异常原因至关重要,因此armv8架构通过far寄存器提供了该地址的值(虚拟地址),其相应的寄存器定义如下:

3-异常处理流程
内核发生同步异常后,会根据异常发生时所处的异常等级(在当前异常等级,还是在低于当前异常等级中触发),和其所使用的栈指针类型(sp_el0还是sp_el1),跳转到相应的异常处理入口。
异常处理函数在执行一些上下文保存,栈指针切换等基础工作后,将跳转到特定类型的handler。如cpu在异常发生时处于arm64模式下,且使用的栈指针为sp_el1时,则其将会跳转到el1h_64_sync_handler中。
该函数会根据esr_el1寄存器中EC中的值,获取其对应的异常类型,然后调用特定异常类型相关的处理函数。在该函数中一般会通过esr_el1寄存器中ISS的值获取其具体的异常原因,并执行相应的处理。
在处理流程中,若异常确实为非法操作引起(异常并不一定是错误,如缺页异常,断点、单步调试等debug异常都是正常的代码处理逻辑),则会调用oops或panic向用户报告错误,并退出当前进程或挂起系统。
由于内核的异常种类繁多,而其处理流程又大同小异,因此下面将以arm64模式下,内核非法地址访问为例。其相应的处理流程如下:

3.1 data abort处理流程
el1h_64_sync_handler首先读取esr_el1寄存器的值,然后解析其中EC的内容,并根据EC值调用其对应的处理函数,如对于data abort将会调用el1_abort,以下为其代码实现:
asmlinkage void noinstr el1h_64_sync_handler(struct pt_regs *regs)
{
unsigned long esr = read_sysreg(esr_el1);
switch (ESR_ELx_EC(esr)) {
case ESR_ELx_EC_DABT_CUR:
case ESR_ELx_EC_IABT_CUR:
el1_abort(regs, esr);
break;
case ESR_ELx_EC_PC_ALIGN:
el1_pc(regs, esr);
break;
…
default:
__panic_unhandled(regs, "64-bit el1h sync", esr);
}
}
el1_abort会调用do_mem_abort,该函数会根据esr_el1寄存器中DFSC的值,调用其相应的处理函数,这些函数通过以下所示的fault_info变量定义:
static const struct fault_info fault_info[] = {
…
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 0 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 1 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 2 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 3 translation fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 8" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 access flag fault" },
…
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
以下为do_mem_abort的代码流程:
void do_mem_abort(unsigned long far, unsigned int esr, struct pt_regs *regs)
{
const struct fault_info *inf = esr_to_fault_info(esr); (1)
unsigned long addr = untagged_addr(far); (2)
if (!inf->fn(far, esr, regs)) (3)
return;
if (!user_mode(regs)) { (4)
pr_alert("Unhandled fault at 0x%016lx\n", addr);
mem_abort_decode(esr);
show_pte(addr);
}
arm64_notify_die(inf->name, regs, inf->sig, inf->code, addr, esr);
}
![]()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
(1)根据DFSC的值在fault_info数组中选择其相应的处理函数指针
-
(2)由于arm64架构可利用虚拟地址空闲的高位bit存储tag信息,以支持MTE特性。因此在获取其实际虚拟地址时需要将相应的tag信息先移除
-
(3)调用fault_info中获取到的回调函数,对于非法地址访问错误,其相应的回调函数为do_translation_fault
-
(4)若异常为未知异常,则通过以下流程直接执行错误处理
do_translation_fault根据异常是由用户态触发还是内核态触发,分别调用其对应等的处理函数,其代码如下:
static int __kprobes do_translation_fault(unsigned long far,
unsigned int esr,
struct pt_regs *regs)
{
…
if (is_ttbr0_addr(addr))
return do_page_fault(far, esr, regs); (1)
do_bad_area(far, esr, regs); (2)
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
(1)用户态处理函数
-
(2)内核态处理函数
对于内核态情形,其最终会调用die_kernel_fault执行实际的错误处理,其代码如下:
static void die_kernel_fault(const char *msg, unsigned long addr,
unsigned int esr, struct pt_regs *regs)
{
…
mem_abort_decode(esr); (1)
show_pte(addr); (2)
die("Oops", regs, esr); (3)
bust_spinlocks(0);
do_exit(SIGKILL); (4)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
(1)它会解析esr_el1寄存器的值,并分别打印其相关的内容,如EC、IL、DFSC等
-
(2)该函数会打印异常地址对应的页表信息,包括pgd、p4d、pud、pmd和pte等
-
(3)执行实际的die操作,该流程将在下一节重点介绍
-
(4)杀死当前进程
3.2 die处理流程
die函数主要执行oops相关流程,且若异常为中断流程中触发或设置了panic_on_oops选项,则进一步通过panic将系统挂起。其主要流程如下:
void die(const char *str, struct pt_regs *regs, int err)
{
…
ret = __die(str, err, regs); (1)
if (regs && kexec_should_crash(current))
crash_kexec(regs); (2)
…
if (in_interrupt())
panic("%s: Fatal exception in interrupt", str);
if (panic_on_oops) (3)
panic("%s: Fatal exception", str);
…
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
(1)调用die相关通知链对应的通知,使其执行die相关的操作,并打印oops相关的信息
-
(2)若需要crash系统,则通过该函数启动一个新的crash内核,并通过新内核将系统内存信息dump出来,以供事后分析。如可通过kdump或ramdump方式配置相应的crash内核
-
(3)若异常发生在中断中,或设置了panic_on_oops,则调用panic挂起系统
3.3 panic处理流程
当内核走到panic时表明其已无法继续运行下去,因此需要执行一些系统挂死前的准备工作,其主要包含以下部分:
-
(1)在smp系统中,一个cpu正在处理panic时,可能另一个cpu也会触发panic。而该流程主要用于一些错误信息收集、内存转储等工作,并不需要也不支持并发操作。因此对于后续触发的cpu不需要执行该流程
-
(2)若正在使用kgdb对内核进行调试,则显然希望调试器能继续执行调试工作。故此时不会真正将系统挂死,而是将控制权转交给调试器
-
(3)若内核配置了kdump等内存转储功能,则在panic时将启动转储相关的流程
-
(4)在smp系统挂死之前,需要停止所有其它cpu的运行,以使系统真正地停下来
-
(5)最后,打印相关的系统信息后,使系统重启或进入死循环
其相应的代码实现如下:
void panic(const char *fmt, ...)
{
…
this_cpu = raw_smp_processor_id();
old_cpu = atomic_cmpxchg(&panic_cpu, PANIC_CPU_INVALID, this_cpu);
if (old_cpu != PANIC_CPU_INVALID && old_cpu != this_cpu) (1)
panic_smp_self_stop();
…
pr_emerg("Kernel panic - not syncing: %s\n", buf);
…
kgdb_panic(buf); (2)
if (!_crash_kexec_post_notifiers) {
printk_safe_flush_on_panic();
__crash_kexec(NULL); (3)
smp_send_stop(); (4)
} else {
crash_smp_send_stop(); (5)
}
atomic_notifier_call_chain(&panic_notifier_list, 0, buf); (6)
printk_safe_flush_on_panic();
kmsg_dump(KMSG_DUMP_PANIC); (7)
if (_crash_kexec_post_notifiers)
__crash_kexec(NULL); (8)
…
panic_print_sys_info(); (9)
if (!panic_blink)
panic_blink = no_blink;
if (panic_timeout > 0) {
pr_emerg("Rebooting in %d seconds..\n", panic_timeout);
for (i = 0; i < panic_timeout * 1000; i += PANIC_TIMER_STEP) {
touch_nmi_watchdog();
if (i >= i_next) {
i += panic_blink(state ^= 1);
i_next = i + 3600 / PANIC_BLINK_SPD;
}
mdelay(PANIC_TIMER_STEP); (10)
}
}
if (panic_timeout != 0) {
if (panic_reboot_mode != REBOOT_UNDEFINED)
reboot_mode = panic_reboot_mode;
emergency_restart(); (11)
}
…
pr_emerg("---[ end Kernel panic - not syncing: %s ]---\n", buf);
suppress_printk = 1;
local_irq_enable();
for (i = 0; ; i += PANIC_TIMER_STEP) {
touch_softlockup_watchdog();
if (i >= i_next) {
i += panic_blink(state ^= 1);
i_next = i + 3600 / PANIC_BLINK_SPD;
}
mdelay(PANIC_TIMER_STEP); (12)
}
}
![]()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
-
(1)若先前已经有cpu正在处理panic流程,则本cpu不再重复处理,只需将当前cpu停止
-
(2)打印panic原因信息
-
(3)若panic流程会执行内存转储,则所有系统相关信息都会被保存到转储文件中,因此就不需要调用后面的通知链,因此可直接调用转储操作。但是转储操作也不是100%保险,因此若不是对其绝对信任,则会设置_crash_kexec_post_notifiers,它会先执行通知链调用和log dump相关流程,再调用内核转储操作
__crash_kexec函数会根据当前是否设置了转储内核确定是否实际执行转储操作,若执行转储则会通过kexec将系统切换到新的kdump内核,并且不再会返回。若不执行转储则继续执行后续流程 -
(4 - 5)停止当前cpu之外的其它cpu运行
-
(6)调用关心panic事件相关模块向其注册的通知
-
(7)dump内核log buffer中的log信息
-
(8)若设置了_crash_kexec_post_notifiers,则根据是否设置了kexec内核,确定是否执行内存转储操作
-
(9)若不执行内存转储,则打印系统相关信息
-
(10)若设置了panic_timeout超时值,则执行超时等待操作
-
(11)若设置了panic_timeout超时值,在超时等待完成后重启系统
-
(12)若未设置panic_timeout超时值,则将系统设置为死循环状态,使其挂死
4-如何手动触发oops和panic
在编码流程中,可能有一些非期望的代码分支,当系统进入这些分支表明出现了一些问题或严重错误。根据问题严重等级的不同,我们可能希望程序能打印一些警告信息,或者将系统设置为oops,甚至panic状态。
为此,内核提供了一些相关的宏和函数用于支持上述需求,以下为其中一些常用的定义:
-
(1)WARN_ON():打印警告信息和调用栈,但不会进入oops或panic
-
(2)BUG_ON():打印bug相关信息,并进入oops流程
-
(3)panic():该函数将直接出发panic流程,将系统设置为挂死状态
除了通过编码方式以外,用户还可以通过sysrq魔术键触发panic流程,下面为通过proc方式触发sysrq相关panic流程的命令:
echo c > /proc/sysrq-trigger
- 1
原文链接:https://zhuanlan.zhihu.com/p/545307249















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









