







 本文详细介绍了Hadoop MapReduce的工作机制,包括作业提交、任务分配和执行过程,以及任务失败的情况。作业提交涉及JobClient与JobTracker的交互,任务分配侧重数据本地化策略,任务执行中每个任务在独立的JVM中运行,保证了任务与TaskTracker的隔离。最后讨论了作业的完成和不同类型的失败情况。
本文详细介绍了Hadoop MapReduce的工作机制,包括作业提交、任务分配和执行过程,以及任务失败的情况。作业提交涉及JobClient与JobTracker的交互,任务分配侧重数据本地化策略,任务执行中每个任务在独立的JVM中运行,保证了任务与TaskTracker的隔离。最后讨论了作业的完成和不同类型的失败情况。
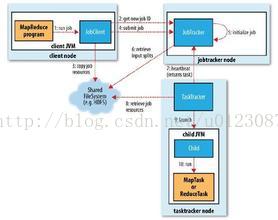
图1 Hadoop运行MapReduce作业的工作原理
作业的提交
JobClient的runJob()方法是用于新建JobClient实例并调用其submitJob()方法的便捷方式(步骤1)。提交作业后,runJob()每秒轮询作业的进度,如果发现上次报告后有改变,便把进度报告到控制台。作业完成后,如果成功,就显示作业计数器。如果失败,导致作业失败的错误被记录到控制台。
JobClient的submitJob()方法所实现的作业提交过程如下。
- 向JobTracker请求一个新的作业ID(步骤2)。
- 检查作业的输出说明。例如,如果没有指定输出目录或输出目录已经存在,作业就不提交,错误抛回给MapReduce程序。
- 计算作业的输入分片。如果分片无法计算,比如因为输入路径不存在,作业就不提交,错误抛回给MapReduce程序。
- 将运行所需的资源(包括作业JAR文件、配置文件和计算所得的输入分片)复制到一个以作业ID命名的目录下jobtracker的文件系统中。作业JAR的副本较多(由mapred.submit.replication属性控制,默认值为10),因此在运行作业的任务时,集群中有很多个副本可提供tasktracker访问。(步骤3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6777
6777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









