







AI Agents可通过与外部系统交互、执行复杂工作流程以及在各项操作中保持上下文感知能力,来扩展大语言模型(LLMs)的功能。Amazon Bedrock Agents通过将基础模型(FMs)与数据源、应用程序以及用户输入进行编排,借助API集成和知识库扩充来完成以目标为导向的任务,从而实现上述功能。
然而,以往将这些Agent连接到各种企业系统时会造成开发瓶颈,因为每次集成都需要编写自定义代码并进行持续维护,这一标准化难题拖慢了整个企业数字生态系统中情境化AI辅助功能的交付速度。而这一问题可通过使用模型上下文协议(Model Context Protocol,MCP)来解决,该协议为LLM连接到数据源和工具提供了一种标准化方式。
如今,MCP为Agent提供了对一系列可访问工具的标准接入途径,您可以利用这些工具来完成各种任务。假以时日,MCP能够通过各种平台提升Agent和工具的可发现性,让Agent能够共享上下文信息,并拥有通用工作空间以实现更高效的交互,同时还能在整个行业范围内提升Agent的互操作性。
本文将展示如何构建Amazon Bedrock Agents,其使用MCP访问数据源来快速构建生成式AI应用程序。借助Amazon Bedrock Agents,您的Agent可像本示例一样,通过基于MCP的工具快速组建而成。
InlineAgent( foundation_model="us.anthropic.claude-3-5-sonnet-20241022-v2:0", instruction="You are a friendly assistant for resolving user queries", agent_name="SampleAgent", action_groups=[ ActionGroup( name="SampleActionGroup", mcp_clients=[mcp_client_1, mcp_client_2],)],).invoke(input_text=”Convert 11am from NYC time to London time”)左右滑动查看完整示意
本文示例演示了通过MCP连接Amazon Cost Explorer、Amazon CloudWatch和Perplexity AI,从而构建一个用于分析您的亚马逊云科技云服务支出情况的Agent。您可以使用本文中引用的代码,将您的Agent连接到其他MCP服务器,以解决业务难题。不妨设想未来存在这样的世界:Agent可以访问不断增长的MCP服务器列表,并利用这些服务器完成各种任务。
模型上下文协议(MCP)
由Anthropic开发的开源协议MCP,提供了一种标准化方式,可将AI模型连接到几乎任何数据源或工具。借助客户端——服务器架构,MCP使开发者能够通过轻量级MCP服务器公开其自有数据,同时将AI应用构建为连接这些服务器的MCP客户端。
通过这种架构,MCP支持用户构建更强大的上下文感知型AI Agents,它们能够无缝访问所需的信息和工具。无论需要连接外部系统、内部数据存储还是各类工具,现在您都可以使用MCP以统一方式与它们进行交互。此外,MCP的客户端——服务器架构还有另外一项优势:当MCP服务器更新时,您的Agent无需修改应用程序代码即可访问新功能。
MCP架构
MCP采用客户端——服务器架构,该架构包含以下组件,如下图所示。
主机:指需要通过MCP协议访问数据的程序或AI工具,例如Claude Desktop、集成开发环境(IDE)或其他任何AI应用程序。
客户端:与服务器保持一对一连接的协议客户端。
服务器:通过标准化MCP协议公开功能的轻量级程序。
本地数据源:MCP服务器可安全访问的数据库、本地数据源及服务。
远程服务:MCP服务器可通过API在互联网上访问的外部系统。
客户端——服务器架构:
https://modelcontextprotocol.io/introduction#general-architecture

下文将介绍如何设置能够利用MCP服务器的Amazon Bedrock Agents。
使用MCP与
Amazon Bedrock Agents
以下将逐步介绍如何将您偏好的MCP服务器连接Amazon Bedrock Agents,该Agent可用于完成用户所提供任务的操作组。以及介绍Amazon Bedrock Inline Agent SDK通过管理复杂的工作流编排,简化调用Inline Agent的流程。该SDK还内置了MCP客户端实现,使您能够直接访问MCP服务器提供的工具。如果不使用此SDK,开发者必须编写并维护自定义代码,用于以下任务。
解析响应流。
处理返回控制流。
管理Agent交互之间的状态。
协调API调用。
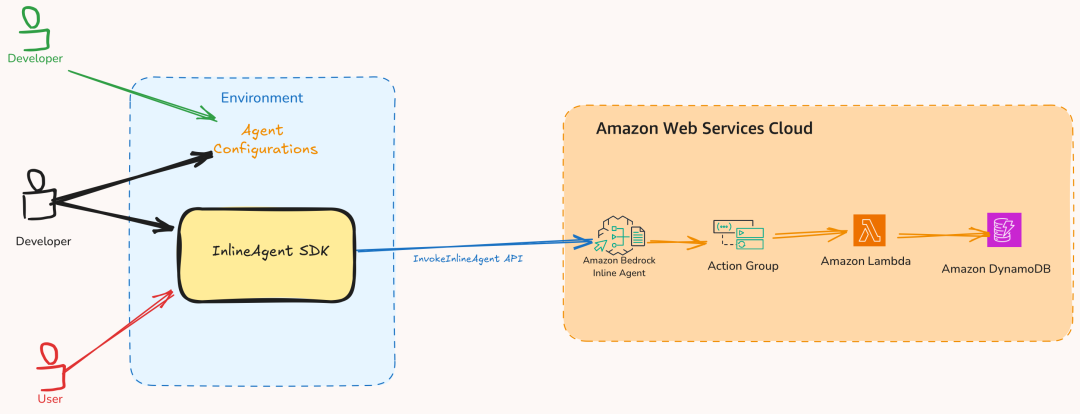
在创建Agent的过程中,开发者须为每个需要与Agent进行通信的MCP服务器创建特定的MCP客户端。当Agent被调用时,它会确定完成用户任务所需的工具。如果需要使用MCP服务器上的工具,它会利用对应的MCP客户端请求该服务器执行工具。
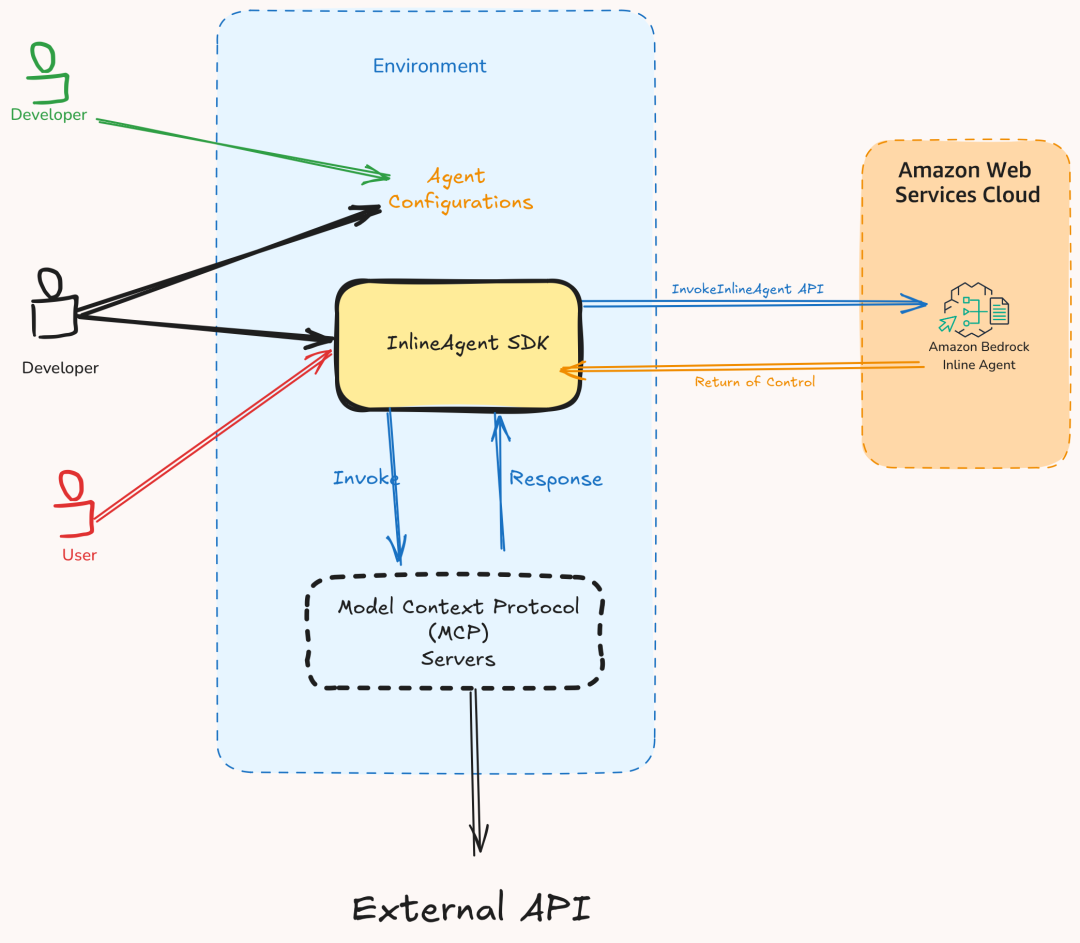
为编排这一工作流,您需要利用Amazon Bedrock Agents的返回控制功能,下图说明了Agent处理使用两种工具的请求的端到端流程。在第一个流程中,采取的是基于Amazon Lambda的操作;而在第二个流程中,Agent使用的是MCP服务器。
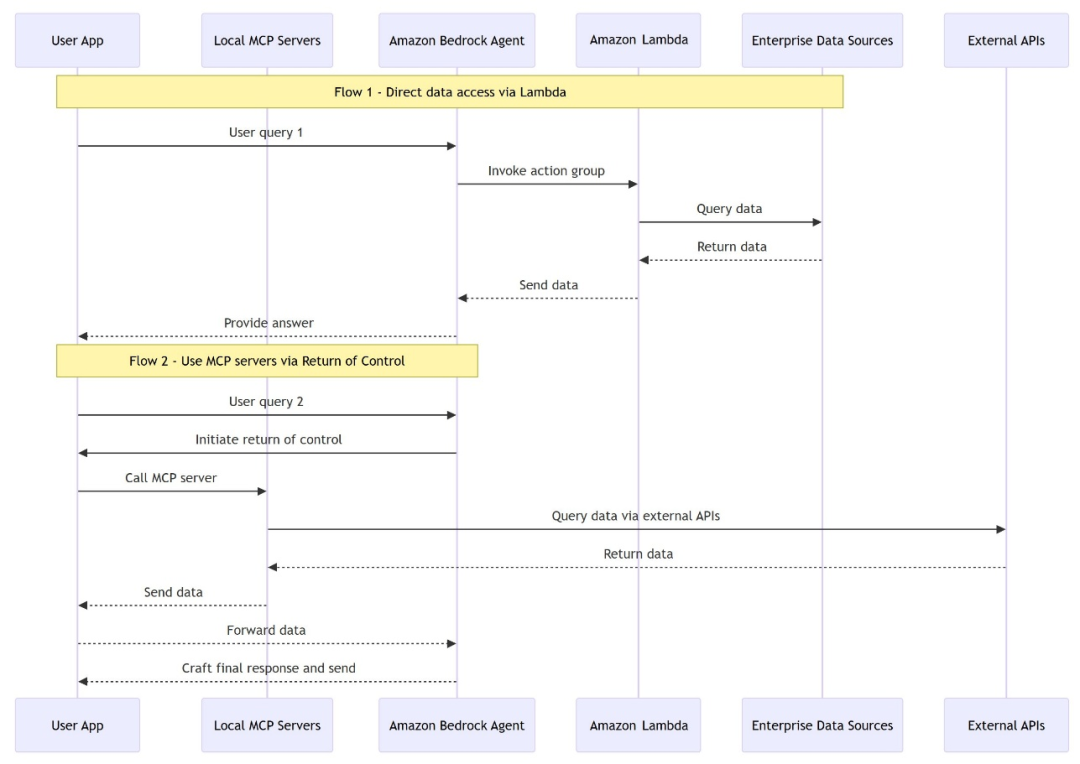
使用案例
您管理Amazon Bedrock等不同亚马逊云科技服务支出的方式下文将通过一项示例,展示Amazon Bedrock Agents如何使用MCP服务器。
当您提出“帮助我了解过去几周关于Amazon Bedrock的支出情况”或“上个月我在不同地区和实例类型中的Amazon EC2成本是多少?”等类似问题时,并希望得到人类可读的数据分析结果,而非仪表盘上的原始数据。系统会解读您的意图,并准确提供您所需要的内容,无论您需要的是详细分解、趋势分析、可视化展示或是成本节约建议。这非常有用,因为您感兴趣的是建议而非数据。
您可以使用两个MCP服务器来实现这一目标:
用于检索亚马逊云科技支出数据的自定义MCP服务器。
用于解释数据的Perplexity AI开源MCP服务器。
您可以将这两个MCP服务器作为操作组添加到内联Amazon Bedrock Agents中,然后您就拥有一个可改变亚马逊云科技支出管理方式的AI Agent。
本文所有代码,您均可参阅GitHub代码库查找。
GitHub代码库:
https://github.com/awslabs/amazon-bedrock-agent-samples/tree/main/src/InlineAgent
下文将介绍如何使用Inline Agent创建此Agent。
您可以使用Inline Agent在运行时动态定义和配置Amazon Bedrock Agents。它们为Agent功能提供了更大的灵活性和控制力,使用户能够根据需要指定FM、指令、操作组、防护和知识库,而无需依赖预配置的控制平面设置。
值得一提的是,您也可以通过InvokeAgent API使用RETURN_CONTROL来编排这种行为,而无需Inline Agent。
Inline Agent:
https://docs.aws.amazon.com/bedrock/latest/userguide/agents-create-inline.html
InvokeAgent API:
https://docs.aws.amazon.com/bedrock/latest/APIReference/API_agent-runtime_InvokeAgent.html
Amazon Bedrock Agents中的MCP组件
1.主机:这是Amazon Bedrock Inline Agent,该Agent将MCP客户端添加为操作组,当用户提出亚马逊云科技支出相关问题时,可通过RETURN_CONTROL调用操作组。
2.客户端:您将创建两个客户端,分别与各自的服务器建立一对一连接。一个是具有特定成本服务器参数的成本资源管理器客户端,另一个是具有Perplexity服务器参数的Perplexity AI客户端。
3.服务器:您将创建两个MCP服务器,每个服务器都在本地运行,并通过标准输入或输出与应用程序通信。或者您也可以配置客户端与远程MCP服务器通信。
第一个是用于访问Amazon Cost Explore和Amazon CloudWatch Logs(获取Amazon Bedrock模型调用日志数据)的MCP服务器,以及用于检索亚马逊云科技支出数据的MCP服务器。
第二个是Perplexity AI MCP服务器,用于解释亚马逊云科技支出数据。
4.数据源:MCP服务器与Amazon Cost Explore API、Amazon CloudWatch Logs和Perplexity AI搜索API等远程数据源通信。
RETURN_CONTROL:
https://docs.aws.amazon.com/bedrock/latest/userguide/agents-returncontrol.html
标准输入或输出:
https://modelcontextprotocol.io/docs/concepts/transports#standard-input%2Foutput-stdio
准备条件
要开始实施本文章中的解决方案,您需要具备以下准备条件。
亚马逊云科技账户。
熟悉基础模型和Amazon Bedrock。
安装Amazon CLI并设置凭证。
Python 3.11或更高版本。
Amazon CDK CLI。
为Anthropic的Claude 3.5 Sonnet v2启用模型访问权限。
您需要拥有AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY,以便使用服务器的环境变量设置设置这些凭证。
两个MCP服务器作为Docker守护进程运行,因此需要在计算机上安装并运行Docker。
MCP服务器在本地计算机上运行,需要访问亚马逊云科技服务和Perplexity API。有关Amazon IAM的更多信息,请参阅《管理Amazon IAM用户访问密钥》。
请确保您的凭证包括对Amazon Cost Explorer和Amazon CloudWatch的Amazon IAM只读访问权限。您可以通过使用AWSBillingReadOnlyAccess和CloudWatchReadOnlyAccess管理Amazon IAM权限来实现这一点。Perplexity API密钥可从Perplexity Sonar API页面获取。
运行步骤
具备上述准备条件后,即可按以下步骤实施解决方案。
1.导航至InlineAgent GitHub代码库。
2.按照设置步骤进行操作。
3.导航至cost_explorer_agent,该文件夹包含本文章的代码。
InlineAgent GitHub代码库:
https://github.com/awslabs/amazon-bedrock-agent-samples/tree/main/src/InlineAgent
设置步骤:
https://github.com/awslabs/amazon-bedrock-agent-samples/tree/main/src/InlineAgent#setup
cost_explorer_agent:
https://github.com/awslabs/amazon-bedrock-agent-samples/tree/main/src/InlineAgent/examples/mcp/cost_explorer_agent
cd examples/mcp/cost_explorer_agent左右滑动查看完整示意
4.使用示例文件在cost_explorer_agent目录下创建.env文件。
示例文件:
https://github.com/awslabs/amazon-bedrock-agent-samples/blob/main/src/InlineAgent/examples/mcp/cost_explorer_agent/.env.example
AWS_ACCESS_KEY_ID=AWS_SECRET_ACCESS_KEY=AWS_REGION=BEDROCK_LOG_GROUP_NAME=PERPLEXITY_API_KEY5*注:虽然本文演示了使用亚马逊云科技访问密钥以简化操作,并聚焦于MCP使用场景上,但在生产环境中,强烈建议您使用Amazon IAM角色,而非长期访问密钥。如果必须使用访问密钥,请遵循以下安全最佳实践:切勿公开共享或暴露您的访问密钥(包括在代码库中)。通过将Amazon IAM策略的范围限定为仅包含所需权限来执行最小权限原则,并定期轮换访问密钥(建议每90天轮换一次)。此外,使用Amazon CloudTrail监控访问密钥的使用情况同样重要,并尽可能考虑使用通过Amazon STS获取的临时凭证。
5.构建aws-cost-explorer-mcp服务器。
git clone https://github.com/aws-samples/sample-cloud-spend-mcp-server.gitcd sample-cloud-spend-mcp-serverdocker build -t aws-cost-explorer-mcp .左右滑动查看完整示意
6.现在您可以调用Agent来深入了解亚马逊云科技服务支出情况,请运行python main.py执行Agent,处理查询内容如下。

Agent与两个MCP服务器建立连接,并访问其相关工具,然后Agent利用特定工具执行顺序计划。
使用代码解释器生成成本分布的可视化表示(条形图)
使用Amazon Cost Explorer MCP服务器分析支出模式。
与Perplexity MCP服务器交互,检索有关Amazon Bedrock的全面信息。
Connected to server with tools: ['get_bedrock_daily_usage_stats', 'get_bedrock_hourly_usage_stats', 'get_ec2_spend_last_day', 'get_detailed_breakdown_by_day']Connected to server with tools: ['perplexity_ask']
Thought: Let me break this down into parts:1. First, I'll ask about Amazon Bedrock using Perplexity2. Then I'll get the cost breakdown for the last 7 days3. Finally, I'll create a visualization of the spending data
Tool use: perplexity_ask with these inputs: messages[[{role=user, content=What is Amazon Bedrock? Provide a concise explanation.}] (array)]
Tool use: get_detailed_breakdown_by_day with these inputs: days[7 (integer)]
Thought: Let me analyze the data and create a visualization of the top services by cost. I'll use Python to process the data and create a bar chart.
Code interpreter:Generated code```import pandas as pdimport matplotlib.pyplot as plt...```
Code interpreter output:aws_costs.png (image/png)Directory output created successfully
Thought: Now I can provide a comprehensive answer about Amazon Bedrock and the cost analysis. Amazon Bedrock is a fully managed service that provides access to foundation models (FMs) from leading AI companies through a single API. Based on the cost analysis of the last 7 days, your top spending services were:
1. Amazon Neptune: $242. Amazon SageMaker: $5673. EC2 (Compute + Other): $4544. Amazon OpenSearch Service: $345. Amazon Bedrock: $12356. Amazon Q: $178左右滑动查看完整示意
点击观看下方演示视频,了解具体操作。
了解Agent生成的输出之后,下文将继续介绍生成这些输出的重要代码。
1.创建MCP客户端:在config.py文件中定义两个MCP客户端,用于与您的两个MCP服务器进行通信。
为成本探索器和Perplexity客户端定义了服务器参数。该解决方案使用StdioServerParameters,它配置了客户端应如何通过标准输入/输出(stdio)流进行通信,包含服务器通过API访问所需数据的必要参数。
# Cost server parameterscost_server_params = StdioServerParameters( command="/usr/local/bin/docker", args=["run","-i","--rm","-e","AWS_ACCESS_KEY_ID","-e","AWS_SECRET_ACCESS_KEY","-e","AWS_REGION","-e","BEDROCK_LOG_GROUP_NAME","-e","stdio","aws-cost-explorer-mcp:latest",], env={"AWS_ACCESS_KEY_ID": AWS_ACCESS_KEY_ID,"AWS_SECRET_ACCESS_KEY": AWS_SECRET_ACCESS_KEY,"AWS_REGION": AWS_REGION,"BEDROCK_LOG_GROUP_NAME": BEDROCK_LOG_GROUP_NAME,},)# Perplexity server parametersperplexity_server_params = StdioServerParameters( command="/usr/local/bin/docker", args=["run", "-i", "--rm", "-e", "PERPLEXITY_API_KEY", "mcp/perplexity-ask"], env={"PERPLEXITY_API_KEY": PERPLEXITY_API_KEY},)左右滑动查看完整示意
在main.py中导入MCP服务器参数,并用于创建两个MCP客户端。
2.配置Agent操作组:main.py创建的操作组将MCP客户端组合成供Agent访问的单一界面,以便Agent能够根据需要,通过控制权的返回,要求应用程序调用其中任何一个MCP服务器。
# Create action group with both MCP clientscost_action_group = ActionGroup( name="CostActionGroup", mcp_clients=[cost_explorer_mcp_client, perplexity_mcp_client])左右滑动查看完整示意
3.创建Inline Agent:可通过以下配置创建Inline Agent。
基础模型:选择驱动Agent的FM,可以是Amazon Bedrock上提供的任何模型,本例使用Anthropic的Claude 3.5 Sonnet模型。
Agent指令:为Agent提供指导性指令,包含编排用户查询响应的步骤,这些指令将锚定Agent处理各类查询的方式。
Agent名称:指定Agent的名称。
操作组:定义Agent可访问的操作组,可包含单个或多个操作组,每个组可访问多个MCP客户端或Amazon Lambda。此外,您还可配置Agent使用代码解释器来生成、运行和测试应用程序代码。
# Create and invoke the inline agentawait InlineAgent( foundation_model="us.anthropic.claude-3-5-sonnet-20241022-v2:0", instruction="""You are a friendly assistant that is responsible for resolving user queries. You have access to search, cost tool and code interpreter. """, agent_name="cost_agent", action_groups=[ cost_action_group, { "name": "CodeInterpreter", "builtin_tools": { "parentActionGroupSignature": "AMAZON.CodeInterpreter" }, }, ],).invoke( input_text="<user-query-here>")左右滑动查看完整示意
您可以通过此示例在Amazon Bedrock上构建Inline Agent,该Agent能够与多个MCP服务器建立连接,并将其客户端整合为单一操作组,供Agent统一访问.
总结
Anthropic MCP协议为将FM连接到数据源连接提供了标准化方案,现在您可以通过Amazon Bedrock Agents使用这一功能。本文演示了如何结合Amazon Bedrock与MCP的强大功能,实现应用程序构建,以全新视角帮助您理解和管理亚马逊云科技服务支出。
企业现在能够为团队提供自然、对话式的复杂财务数据访问方式,同时借助Perplexity等数据源的上下文智能增强响应质量。随着AI技术发展,将模型安全接入企业核心系统的能力价值日益凸显。无论是改善客户服务、优化运营流程,还是获取深度业务洞察,Amazon Bedrock与MCP的集成都为AI创新提供了灵活基础。您可参阅代码示例,进一步探索该MCP集成方案。
代码示例:
https://github.com/awslabs/amazon-bedrock-agent-samples/tree/main/src/InlineAgent/examples/mcp
以下是通过将Amazon Bedrock Agents连接到MCP服务器可构建内容的示例。
多数据源Agent:可从Amazon Bedrock知识库、SQLite数据库甚至本地文件系统等不同数据源检索数据。
开发者效率助手Agent:与Slack和GitHub的MCP服务器集成,提升团队协作与开发效率。
机器学习实验追踪Agent:对接Comet ML的Opik MCP服务器,直接在开发环境中管理、可视化并跟踪机器学习实验。
本篇作者

Mark Roy
亚马逊云科技首席机器学习架构师,帮助客户设计和构建生成式AI解决方案。自2023年初以来,他的工作重点是牵头开展解决方案架构设计工作,以助力亚马逊云科技推出面向开发者的旗舰生成式AI产品:Amazon Bedrock。Mark的工作涉及众多应用场景,主要聚焦于生成式AI、Agent以及在企业范围内推广机器学习规模化应用。他已为保险、金融服务、媒体与娱乐、医疗保健、公用事业和制造业等领域公司提供过帮助。Mark持有六项亚马逊云科技认证,包括机器学习专项认证。

Eashan Kaushik
亚马逊云科技人工智能与机器学习专家解决方案架构师。他致力于打造前沿的生成式AI解决方案,同时坚持以客户为中心的工作理念。

Madhur Prashant
亚马逊云科技人工智能与机器学习解决方案架构师。他热衷于人类思维与生成式人工智能的交叉融合,兴趣领域在于生成式AI,特别是构建对客户有益无害的解决方案。

Amit Arora
亚马逊云科技人工智能与机器学习专家架构师,致力于帮助企业客户使用基于云的机器学习服务快速扩展创新成果。Amit还是华盛顿特区乔治城大学数据科学与分析硕士课程的兼职讲师。

Andy Palmer
亚马逊云科技战略客户部技术总监。他的团队在多个专业领域提供专业解决方案架构技能,包括人工智能与机器学习、生成式AI、数据和分析、安全、网络和开源软件。Andy及其团队一直走在引导最先进的客户探索生成式AI之旅的前沿,并帮助寻找将这些新工具应用于现有问题领域以及全新创新和产品体验的方法。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9436
9436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









