







在企业上云旅程的起点,电话销售团队承担着至关重要的角色,他们不仅需要快速了解客户需求,还要通过精准话术激发客户兴趣,推动转化。然而,当前销售话术的准备工作面临诸多挑战:
信息获取难:销售人员需要手动收集、筛选和整合大量数据,费时费力。
通话质量受限:缺乏实时、个性化的话术支持,影响客户沟通效果。
传统LLM方案存在局限:单纯依赖大语言模型(LLM)生成话术,容易产生“幻觉”问题,且无法准确调用企业内部知识。
为帮助企业客户解决这些痛点,本文采用检索增强生成(RAG)技术,结合Amazon Bedrock和Dify,打造智能销售话术推荐系统。
该方案通过构建企业知识库,利用先进的检索算法,精准匹配电话销售客户需求,并生成高质量、可信赖的话术内容,为电话销售团队提供强有力的支持。
解决方案架构
方案基于Amazon Bedrock构建高效数据摄取与RAG,并利用Dify生成销售话术。Web爬虫和Amazon EventBridge定期更新知识库,将数据存储至Amazon S3并导入Amazon Bedrock知识库。查询时,Dify编排工作流并调用Amazon Bedrock RetrieveAndGenerate API进行检索和生成,流程如下图。

下文将对这两部分流程进行详述。
数据摄取流程
1.Web爬虫:在Amazon Lambda或Amazon EC2部署爬虫,从各种在线数据源收集信息。
2.Amazon EventBridge:定期触发爬虫,确保知识库时效性。
3.Amazon S3:存储爬虫收集的原始数据或手动上传内部文档。
4.Amazon Bedrock知识库:支持多种分块策略与向量嵌入(如Amazon OpenSearch Serverless),提高检索效率。
在线查询流程
1.用户查询输入。
2.Dify编排工作流:构建自定义工作流完成复杂文本生成。
3.Amazon Bedrock RetrieveAndGenerate API:
提供查询分解、元数据过滤、重排序等功能,优化检索效果。
生成的回复包含引文信息,便于人工验证。
4.响应输出:通过Dify返回用户。
下图是基于Dify构建的工作流示意,基于诸如LLM节点、代码执行模块等多种组件,通过拖拉拽和简单的配置,即可快速搭建LLM应用,不需要开发能力。此外,Dify提供了很多内置工具,还可以自定义工具,弥补Dify原有工具的局限性。
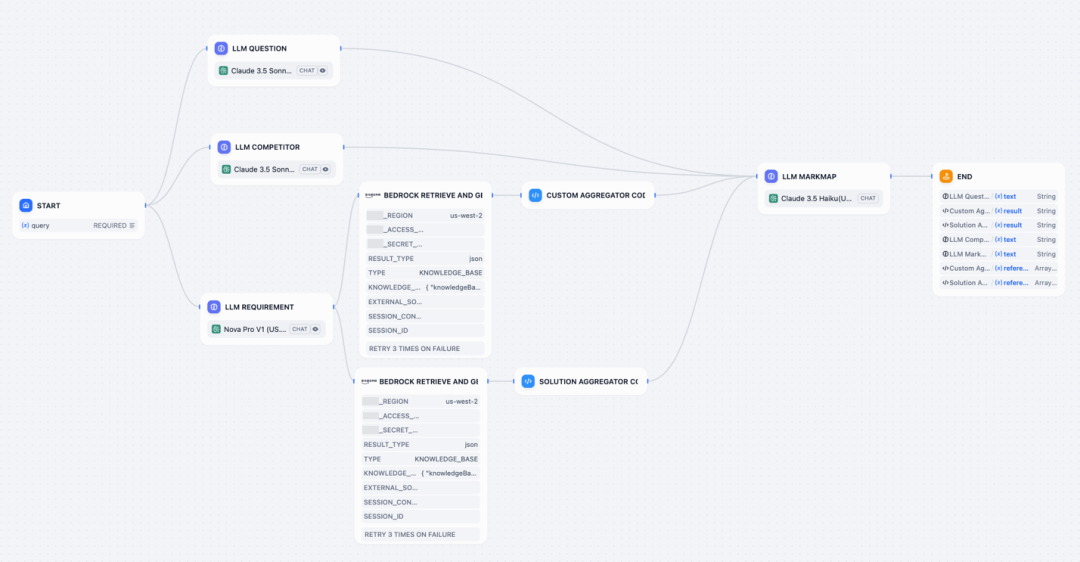
实施细节
RAG实现思路比较清晰明了,但是在实际生产落地时,仍有很多工程化的问题亟需解决。随着知识库中的文档数量增加,检索准确率往往有所下降,在海量文档中高效准确地检索信息成为RAG系统的主要瓶颈。
为提升检索准确率,以下是一些常用的优化思路。
元数据过滤
元数据过滤是一种在检索前缩小搜索范围的有效方法。通过为每个文档添加诸如主题、时间、作者等结构化的元数据标签,可以在执行语义搜索之前先基于元数据标签做一次预筛选。
具体的实施步骤如下:
设计合适的元数据schema:确保元数据标签能够覆盖业务中的关键属性。
在文档入库时自动或手动添加元数据标签。
查询阶段的元数据预筛选:在执行语义搜索之前,基于用户查询和上下文对文档集合进行元数据筛选,只保留相关文档。
仅对过滤后的文档子集执行向量检索:减少计算资源消耗,同时提高检索速度和响应准确性。
值得一提的是,Amazon Bedrock知识库目前支持自动生成查询过滤(Auto-Generated Metadata Filtering),扩展了手动元数据过滤(Manual Metadata Filtering)的功能。该功能可自动识别查询中的关键属性,并智能应用元数据筛选条件。用户可以在不手动构建复杂过滤规则的情况下,自动筛选出高相关性的文档,从而优化RAG系统的整体表现。
例如:
1.查询:“How to file a claim in Washington”。
2.自动生成的过滤条件:“state=Washington”。
3.最终检索的文档:仅包含Washington州相关的文档,而非全国范围的所有索赔指南。
如果文档本身有高置信度、贴合业务的元数据标签,则可以考虑此种优化思路。
重排序(Re-ranking)
排序是一种后处理技术,用于在初始向量检索之后,通过更复杂的评分机制对Top-K检索结果进行重新排序,以提升最终返回内容的精准度与相关性。
Amazon Bedrock知识库内置Re-rank模型,可自动对检索结果进行重新排序,确保最相关的文档排在前面。该模型利用深度语义匹配(Deep Semantic Matching)技术,以更精细的方式计算查询与文档之间的匹配度,相比于仅基于向量相似度的检索方式,能够提供更高质量的结果。
知识质量
知识质量对RAG系统的性能至关重要。数据质量越高,数据的组织结构越清晰,信息的可检索性越强。反之,若知识库中的信息密度较低,回答一个问题可能需要引用多个文本块,从而在LLM的上下文窗口中插入更多文本。这不仅增加了token的消耗和计算成本,还可能导致关键信息因湮没在大量文本中而被稀释,使得LLM失焦。
所以,清洗数据在构建知识库中十分重要,降低与业务无关信息出现在知识库中的可能性。此外,为了提高数据块的信息密度,可以考虑利用LLM作为事实提取器,从原始文档中筛选和提炼关键信息。
查询重写(Query Rewriting)
查询重写是一种从客户的查询入手,以优化RAG性能的策略。其旨在通过改写、扩展或分解用户查询,提高检索系统的召回率和准确性,确保重写后的用户问题能够更贴合、更匹配知识库中的文档。
Amazon Bedrock知识库支持Query Decomposition(查询分解)是查询重写的一个子类。具体做法为:先将复杂查询拆解为多个子查询,并分别检索相关内容,然后动态组合子查询的结果,生成更全面的答案。
例如,针对查询“2022年FIFA世界杯上谁得分更高,阿根廷队还是法国队?”,Amazon Bedrock知识库可能会首先生成以下子查询,然后再生成最终答案:
阿根廷队在2022年FIFA世界杯决赛中进了多少球?
2022年FIFA世界杯决赛中法国队进了多少球?
通过拆分长查询,分别搜索再整合答案,提高对复杂问题的支持能力。
总结
在方案研发阶段与企业客户电话销售团队展开深度需求调研,锚定业务痛点与技术可行性的最佳结合点。基于场景化建模与ROI分析,构建起兼顾技术可行性与商业回报的解决方案框架,重点通过双轮驱动实现价值闭环。
1.通过生产级RAG优化确保落地可靠性。尽管RAG基础架构逻辑简明,但在应对高并发、低延迟的业务场景时,企业客户可通过元数据过滤、重排序(Re-ranking)、知识质量提升和查询重写等技术攻关,将平均响应时间压缩至800ms以内,对话术生成准确率提升至92%以上。特别是在知识库动态更新、会话状态保持等工程细节上,形成了标准化处理范式。
2.为电话销售部门创造可量化的业务价值。据企业客户反馈,实际部署后,销售团队成功实现三大提升:话术准备效率提升70%、首次接触转化率提升18%、异议处理采纳率提高32%。系统生成的个性化推荐话术,可依据电话销售客户画像自动匹配保险产品卖点与抗辩策略,真正成为销售人员的智能作战助手。
需要特别说明的是,当前技术方案结合了Amazon Bedrock的托管服务优势与Dify的流程编排能力,实际项目中亦可采用亚马逊云科技的不同技术栈实现。
亚马逊云科技始终主张根据企业的数据规模、成本预算和运维能力进行定制化设计,人工智能从来都不是单选题,而是需要持续探索的最优解。

附录
Dify部署方式:
https://github.com/aws-samples/dify-self-hosted-on-aws
本篇作者

朱文倩
亚马逊云科技解决方案架构师,负责亚马逊云科技云计算方案咨询和设计。同时致力于生成式AI应用方面的研究和推广,并通过可实施的解决方案,帮助客户取得业务价值。

杨广文
亚马逊云科技解决方案顾问,致力于云计算、生成式AI的市场挖掘和洞察分析,具有丰富的云和AI咨询经验,为客户提供数字化转型咨询,帮助加速企业客户业务发展和创新。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9437
9437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









