







1.启动MCP Server
在启动了RagFlow 服务的基础上,通过开放API-KEY,从前台登录到RagFlow,点击右上角的图标进入设置。


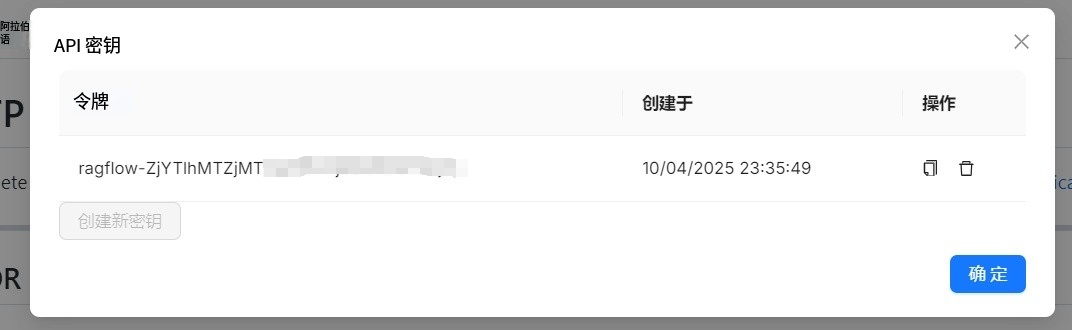
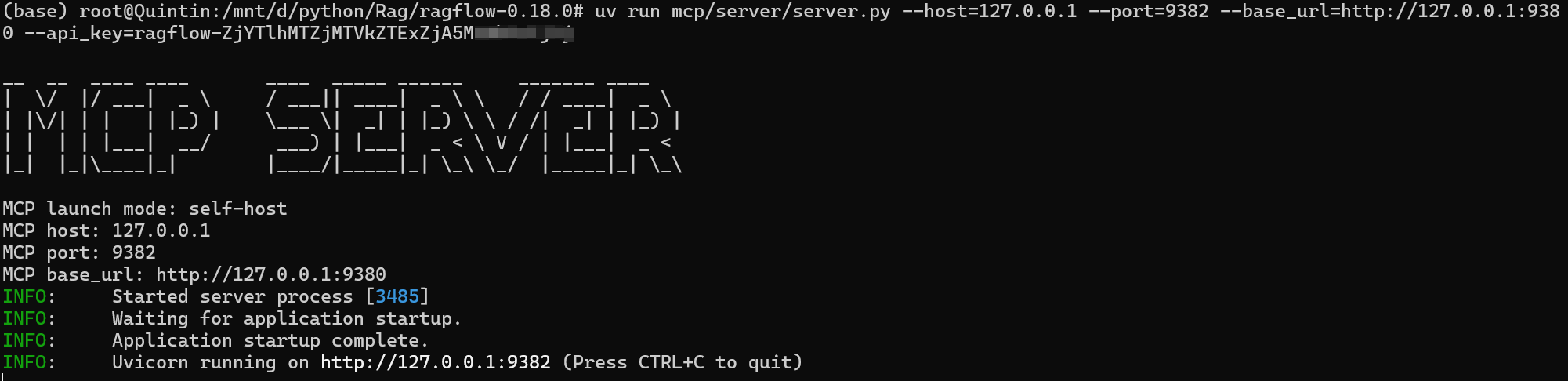
获取到APIKEY 之后,可以通过如下命令启动MCP Server
uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 --api_key=ragflow-xxxxx
2.通过客户端进行MCP Server 调用
2.1 在默认的client 代码中,提供的dataset id 是示例。需要修改为自己的
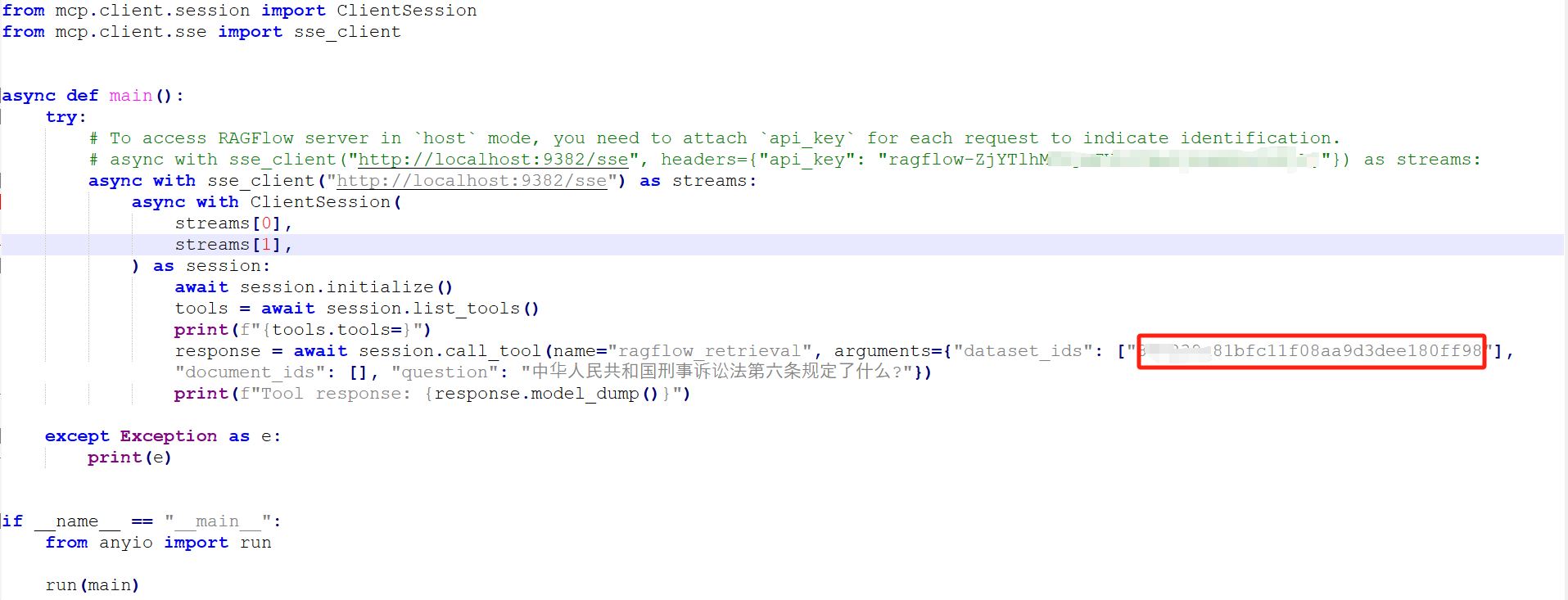
client 代码:
from mcp.client.session import ClientSession
from mcp.client.sse import sse_client
async def main():
try:
# To access RAGFlow server in `host` mode, you need to attach `api_key` for each request to indicate identification.
# async with sse_client("http://localhost:9382/sse", headers={"api_key": "ragflow-ZjYTlhMTZjMTVkZTExZjA5MzNkYzFjYj"}) as streams:
async with sse_client("http://localhost:9382/sse") as streams:
async with ClientSession(
streams[0],
streams[1],
) as session:
await session.initialize()
tools = await session.list_tools()
print(f"{tools.tools=}")
response = await session.call_tool(name="ragflow_retrieval", arguments={"dataset_ids": ["换成自己的"], "document_ids": [], "question": "中华人民共和国刑事诉讼法第六条规定了什么?"})
print(f"Tool response: {response.model_dump()}")
except Exception as e:
print(e)
if __name__ == "__main__":
from anyio import run
run(main)到数据库中,查看knowledgebase 表,找到对应知识库的id,这里我选择我本地法律条文的知识库,并获取其id。![]()
代码修改完毕之后,在RagFlow根目录下执行
source .venv/bin/activate
python mcp/client/client.py
即可通过MCP Server 进行当前知识库的检索。目前RagFlow 的MCP Server 仅提供了少量功能,后续扩展空间很大


















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











