









转载整理自https://blog.csdn.net/haoji007/article/details/80361587
https://www.jianshu.com/p/da4641f50000
三种图片
(1)原图
(2)图像分类分割
(3)图像物体分割
见下图:

两套数据集
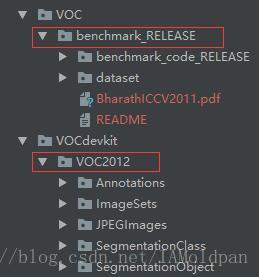
(1)benchmark_RELEASE( Semantic Boundaries Dataset(henceforth abbreviated as SBD))
是增强数据集,只包含边界(如下图)
http://home.bharathh.info/pubs/codes/SBD/download.html![]()
Please note that the train and val splits included with this dataset are different from the splits in the PASCAL VOC dataset. In particular some "train" images might be part of VOC2012 val.(sbd中训练集和验证集的划分方式与PASCAL中的不同,所以sbd中的train samples 可能包含了PASCAL中的val)
数据集分为20类,包括背景为21类,分别如下:
- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
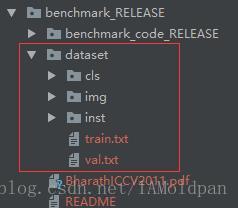
文件夹中的图片类型:
cls: 图像分类分割.mat标注信息(每个类别对应一个特定的数值,有多少类就有多少数值)
img: 分割图像(原始图像)
inst: 图像物体分割.mat标注信息(只要在一幅图中将不同物体分割显示出来即可而不是对不同的物体进行类别标记。)
ps : .mat文件每个值对应着一个像素, 相当于一张一通道的灰度图, 值对应的是像素点所属的类别,背景为0.
(2)VOC2012
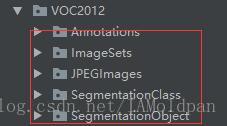
1)Annotation中包含了对应图片的xml信息
2)SegmentationClass中的png图用于图像分割分类
是三通道彩色图(与.Mat文件不同,每个像素值不是0-20,而是对应着不同的RGB分量)
SegmentationClass中的pre_encoded中png图三通道的值相同,其中数字代表类别(与benchmark中的.mat文件表示方式类似),
可以发现这里的RGB都是同一个值,其中人代表的RGB值为(15,15,15),而飞机代表的为(1,1,1),也就是说,precoded中的图片相比于之前的png图将不同类别代表的颜色(假如飞机为(0,255,255))“变为”了1而人代表15,和benchmark中的数据集分类的表示方式就类似了。
3)SegmentationObject中的png图则仅仅对图中不同的物体进行的分割,不对其物体所属的类别进行标注:
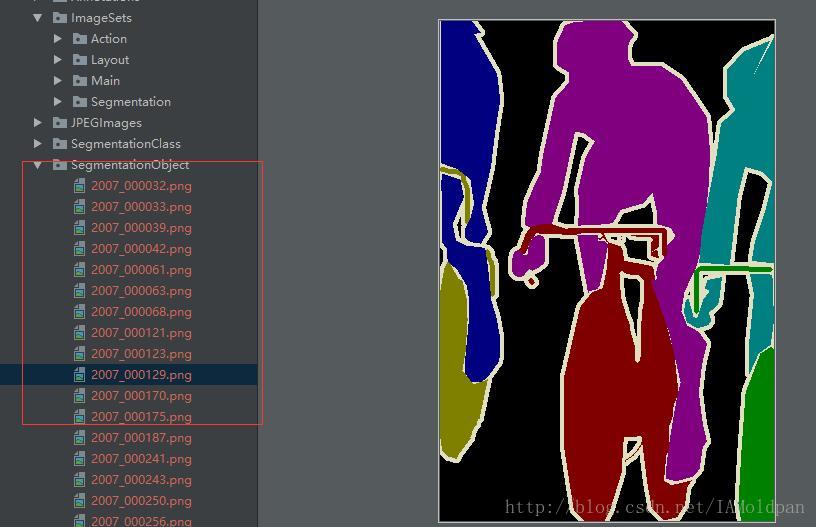
显然,上面的很多人都被标记了不同的颜色,当然仅仅是为了分离出来。
3)JPEGimages则放了我们需要的图片
这些图片一共有17125张,我们并不是都使用,我们仅对train.txt和val.txt中列出的图像进行使用,而其他的图像则用于不同的任务中。















 5519
5519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









