







 本文探讨了特征选择中的K-L变换,对比了聚类变换的局限性,详细解释了最优描述和最优区分两种K-L变换方法,旨在找到使类间距离最大化和分类效果最佳的特征。
本文探讨了特征选择中的K-L变换,对比了聚类变换的局限性,详细解释了最优描述和最优区分两种K-L变换方法,旨在找到使类间距离最大化和分类效果最佳的特征。
上一讲说到,各个特征(各个分量)对分类来说,其重要性当然是不同的。
舍去不重要的分量,这就是降维。
聚类变换认为:重要的分量就是能让变换后类内距离小的分量。
类内距离小,意味着抱团抱得紧。
但是,抱团抱得紧,真的就一定容易分类么?
如图1所示,根据聚类变换的原则,我们要留下方差小的分量,把方差大(波动大)的分量丢掉,所以两个椭圆都要向y轴投影,这样悲剧了,两个重叠在一起,根本分不开了。而另一种情况却可以这么做,把方差大的分量丢掉,于是向x轴投影,很顺利就能分开了。因此,聚类变换并不是每次都能成功的。
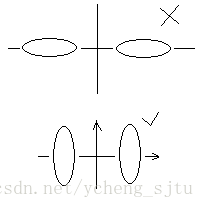
图1
摧枯拉朽的K-L变换
K-L变换是理论上“最好”的变换:是均方误差(MSE,MeanSquare Error)意义下的最佳变换,它在数据压缩技术中占有重要地位。
聚类变换还有一个问题是,必须一类一类地处理,把每类分别变换,让它们各自抱团。
K-L变换要把所有的类别放在一起变换,希望通过这个一次性的变换,让它们分的足够开。
K-L变换认为:各类抱团紧不一定好区分。目标应该是怎么样让类间距离大,或者让不同类好区分。因此对应于2种K-L变换。
其一:最优描述的K-L变换(沿类间距离大的方向降维)
首先来看个二维二类的例子,如图2所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9485
9485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









