










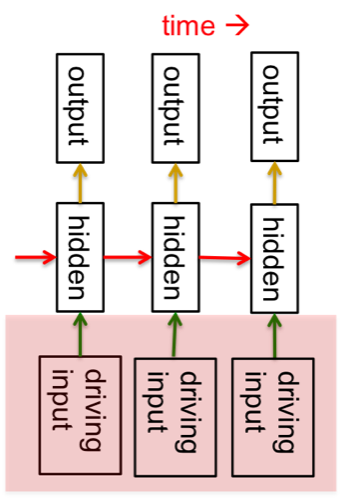
序列建模
用机器学习对序列建模的意义
将输入序列变化到另一个域上的输出序列,例如:
将声压信号转化成单词序列。
若没有目标序列,可以通过预测输入序列中的下一段来作为学习信号。
这种方法介于监督学习与无监督学习之间,它使用了监督学习的训练方法,但并不需要一个单独的学习信号。
序列的无记忆模型
自回归模型(Autoregressive models)
通过使用固定数量的历史序列项,来预测未来序列项。即所谓的“delay taps”,如图1。

前馈神经网络(Feed-forward neural nets)
通过引入一个隐含非线性神经元来产生自回归模型。如图2。

让模型具有记忆
通过给生成模型加入具有内部动态的隐含状态层,能够使模型具有记忆:
- 与非记忆模型不同,记忆模型能够在其隐藏状态层中存储很长时间,而且没有简单的标准去判断多远以前的事件对现在没有影响。
- 如果隐含层动态是有噪音的,而且其输出也是有噪音的。那么我们将无从得知其真正的隐含层状态。
- 因此只能在隐含层空间推断出概率分布。
通过观测值来推测隐含状态通常是困难的。
然而以下有2种典型模型的隐含状态计算起来比较方便。
线性动态系统(Linear Dynamical Systems)
线性动态系统工程师比较常用,其隐含层状态是带有高斯噪声的线性动态,如图3所示。
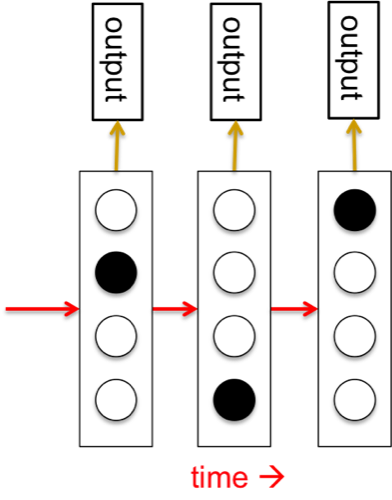
隐马尔可夫模型(Hidden Markov Models)
隐马尔可夫模型基于离散数学,计算机学者比较喜欢。这种模型隐含层状态由状态转移矩阵进行切换,每一次隐含层对应一个输出,如图4所示。
HMMs 的局限性
HMMs 的 记忆容量太小,如果有
N
个隐含状态,HMMs 只能记住
递归神经网络(Recurrent Neural Networks)
RNN的优点在与结合了两者的优点:
- 利用了类似线性动态系统的分布式隐含层结构,从而有效能够存储关于过去的大量信息。(能够同时记忆多件不同的事情)
- 利用了类似隐马尔可夫的非线性动态结构,从而能够以更加复杂的方式更新隐含状态。
生成模型是否需要随机?
- 线性动态模型与隐马尔可夫模型都是随机模型,因为这些动态和观测值都是存在噪音的。
- RNN是确定性模型。
使用反向传播训练RNN
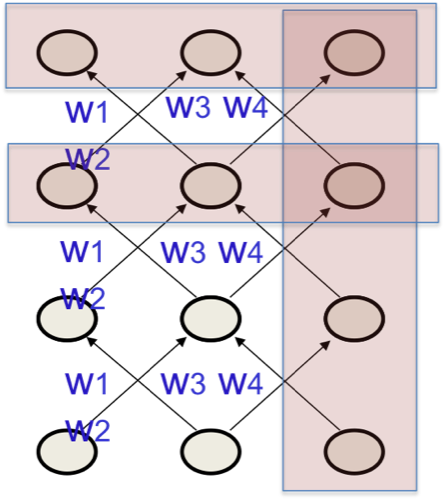
RNN网络可以展开成反复利用共享权重的深度网络,如图5所示。
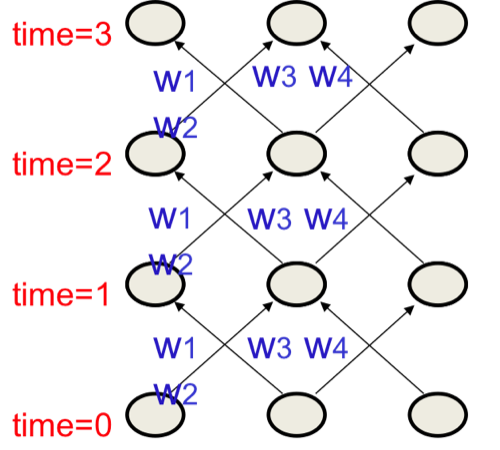
因此其共享权重也应该联合修正:
将RNN展开是一种理解方式,还可以就在时域理解,即每次把对权重不同时刻的导数相加,进行联合修正。
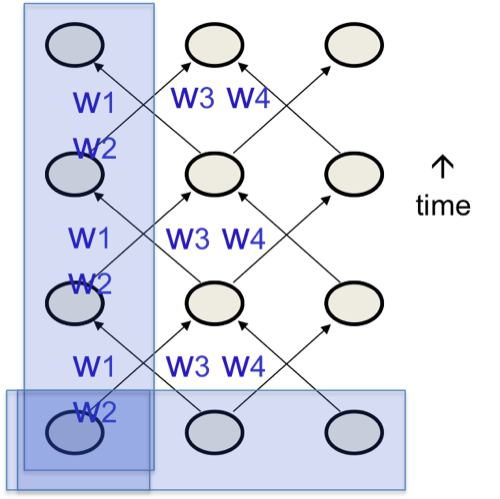
给RNN提供输入
有多种方式来给RNN提供输入(如图6),其中最常用的是下列中的第三种:
- 指定所有节点的初始状态。
- 指定部分节点的初始状态。
- 指定部分节点的全部时刻状态。
给RNN提供监督信号
同样有多种方式给RNN提供监督信号(如图7),最常用的也是下列第三种:
- 指定所有节点的最终状态。
- 指定所有节点的最后几个阶段状态。
- 指定部分节点的所有阶段的状态。
训练RNN的简单实例
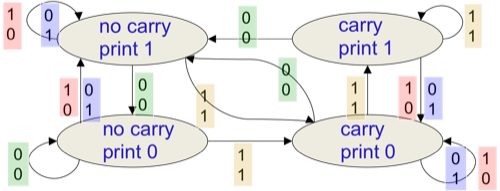
完成两个二进制序列的求和,需要完成相应的进位操作。其完整的算法逻辑可由如图8所示含有4个隐含状态的流程图表示:
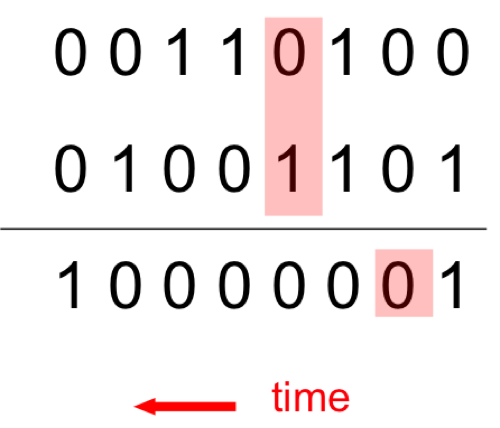
该RNN针对二进制序列求和会有2个时间步延时刻(如图9所示):
- 一个用以更新隐藏节点的状态。
- 一个通过隐藏节点计算输出。
RNN可以模拟一个有限状态自动机,但却更加强大:N个隐含节点对应2^N个可能的激活向量,却只需要N^2个权重。
为什么训练RNN非常困难?
因为训练的前向过程和反向过程具有巨大区别:
- 前向过程为了防止激活向量爆炸,我们使用了压缩函数,如Sigmoid。
- 反向过程却是一个完全线性的过程(回想残差的传递公式)。
前向过程决定了反向传递过程的斜率,如图10所示。

梯度爆炸与消失
对于RNN这种非常深的NN,梯度残差非常容易出现爆炸活着消失。
就算使用了良好初始化的权值,依然难以探测出当前输出依赖于若干时间步之前的输入。
训练RNN的4种有效手段
- LSTM (Long Short Term Memory)
使RNN获得长期记忆能力。 - Hessian Free 优化方法
通过检测梯度小但是曲率更小的权值方向来解决梯度消失问题。 - 回声状态网络(Echo State Networks)
小心初始化从输入到隐含层的权值;小心初始化隐含层到输出的权值;其核心是一个随机生成、且保持不变的储备池(Reservoir),唯一要训练的部分使其输出权值,使用简单的线性回归即可完成训练。 - 良好的初始化与动量的使用
LSTM 相关内容会整理一篇单独博文。















 5903
5903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









