






1.2 insertNamePrefixes
DialerDatabaseHelper的insertNamePrefixes方法调用流程图如下,
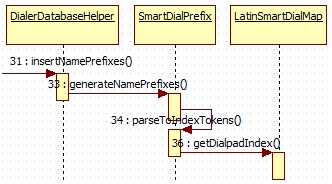
insertNamePrefixes方法主要逻辑如下,
1,从smartdial_table表单中获取联系人的姓名和id,
final int columnIndexName = nameCursor.getColumnIndex(
SmartDialDbColumns.DISPLAY_NAME_PRIMARY);
final int columnIndexContactId =
nameCursor.getColumnIndex(SmartDialDbColumns.CONTACT_ID);
2,构造prefix_table表单插入语句
final String sqlInsert = "INSERT INTO " + Tables.PREFIX_TABLE + " (" +
•••
final SQLiteStatement insert = db.compileStatement(sqlInsert);
3,逐条插入,首先调用SmartDialPrefix的generateNamePrefixes方法将姓名转化为对应的数字,
然后将数字和id利用插入语句插入prefix_table表单
while (nameCursor.moveToNext()) {
/** Computes a list of prefixes of a given contact name. */
final ArrayList<String> namePrefixes =
SmartDialPrefix.generateNamePrefixes(nameCursor.getString(columnIndexName));
for (String namePrefix : namePrefixes) {
insert.bindLong(1, nameCursor.getLong(columnIndexContactId));
insert.bindString(2, namePrefix);
insert.executeInsert();
insert.clearBindings();
}
}
SmartDialPrefix的generateNamePrefixes方法主要逻辑如下,
1,调用parseToIndexTokens方法将姓名转化为数字字符组,
final ArrayList<String> indexTokens = parseToIndexTokens(index);如果姓名都是由字母和数字组成,则indexTokens 只有一个字符串;否则一般由其他字符(空格)返回的是多个字符串。例如 zhangmanxue 返回的是 一个字符 94264626983, zhang man xue 中间有2个空格,返回三个字符,分别是94264,626,983.
2,将返回的数字字符组
final StringBuilder fullNameToken = new StringBuilder();
for (int i = indexTokens.size() - 1; i >= 0; i--) {
fullNameToken.insert(0, indexTokens.get(i));
result.add(fullNameToken.toString());
}
还是上面的例子,如果是zhangmanxue,则result中的数字字符组依次为983, 626983, 94264626983.
ArrayList<String> fullNames = Lists.newArrayList();
//获取indexTokens中最后一个数字串字符 为983
fullNames.add(indexTokens.get(indexTokens.size() - 1));
final int recursiveNameStart = result.size();// 3
int recursiveNameEnd = result.size();// 3
下面接着按照示例来,
for (int i = indexTokens.size() - 2; i >= 0; i--) {
if ((i >= indexTokens.size() - LAST_TOKENS_FOR_INITIALS) ||
(i < FIRST_TOKENS_FOR_INITIALS)) {
LAST_TOKENS_FOR_INITIALS和 FIRST_TOKENS_FOR_INITIALS的值都为2,
因此,这个if判断最多正确3次,倒数第一个元素和顺数第一个和第二个元素。
按照示例,正确2次,第一次如下,
initial = indexTokens.get(i).substring(0, 1); //626 中的6
/** Recursively adds initial combinations to the list.*/
for (int j = 0; j < fullNames.size(); ++j) {
result.add(initial + fullNames.get(j));//添加6983
}
for (int j = recursiveNameStart; j < recursiveNameEnd; ++j) {
result.add(initial + result.get(j));//不执行 recursiveNameStart和recursiveNameEnd 都是3
}
recursiveNameEnd = result.size();// 4
final String currentFullName = fullNames.get(fullNames.size() - 1);// 为983
fullNames.add(indexTokens.get(i) + currentFullName);//添加626983
此时result 中有4个值,依次是983, 626983, 94264626983, 6983
当i为0时,第二次循环如下,
initial = indexTokens.get(i).substring(0, 1); //94264中的9
/** Recursively adds initial combinations to the list.*/
// 循环2次,依次添加 9983,9626983
for (int j = 0; j < fullNames.size(); ++j) {
result.add(initial + fullNames.get(j));
}
for (int j = recursiveNameStart; j < recursiveNameEnd; ++j) {
result.add(initial + result.get(j));//执行一次,添加96983
}
recursiveNameEnd = result.size();
final String currentFullName = fullNames.get(fullNames.size() - 1);
fullNames.add(indexTokens.get(i) + currentFullName);
因此,最后result中一共有7个值,分别是983, 626983, 94264626983, 6983, 9983,9626983, 96983.prefix_table表单对应如下,
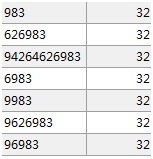
对于其他姓名,也可以对照分析。
parseToIndexTokens方法主要逻辑如下,
对每个姓名字符串进行操作,
for (int i = 0; i < length; i++) {for循环里面的逻辑如下,
此时的mMap对象是LatinSmartDialMap对象.
如果是a到z的字母或者0到9的字符,则调用LatinSmartDialMap的getDialpadIndex方法进行转化,
if (mMap.isValidDialpadCharacter(c)) {
/** Converts a character into the number on dialpad that represents the character.*/
currentIndexToken.append(mMap.getDialpadIndex(c));
}
否则就添加到result中,在此从头开始进行检测,
if (currentIndexToken.length() != 0) {
result.add(currentIndexToken.toString());
}
currentIndexToken.delete(0, currentIndexToken.length());
也就是说,如果联系人姓名中有不是a到z的字母或者0到9的字符,就会进行拆分, 例如,ngmanxue 返回的是 一个字符 94264626983, zhang man xue 中间有2个空格,返回三个字符,分别是94264,626,983.
LatinSmartDialMap的getDialpadIndex方法逻辑如下,
1,如果是0到9的字符,就转化为0到9的数字;
2,如果是a到z的字母,则按照LATIN_LETTERS_TO_DIGITS的映射关系转化为0到9的字符,然后就转化为0到9的数字;
if (ch >= '0' && ch <= '9') {
return (byte) (ch - '0');
} else if (ch >= 'a' && ch <= 'z') {
return (byte) (LATIN_LETTERS_TO_DIGITS[ch - 'a'] - '0');
} else {
return -1;
}
LATIN_LETTERS_TO_DIGITS变量如下,
private static final char[] LATIN_LETTERS_TO_DIGITS = {
'2', '2', '2', // A,B,C -> 2
'3', '3', '3', // D,E,F -> 3
'4', '4', '4', // G,H,I -> 4
'5', '5', '5', // J,K,L -> 5
'6', '6', '6', // M,N,O -> 6
'7', '7', '7', '7', // P,Q,R,S -> 7
'8', '8', '8', // T,U,V -> 8
'9', '9', '9', '9' // W,X,Y,Z -> 9
};
很巧妙的使用了字符相减的方法进行对应。因此, A,B,C映射为2, D,E,F映射为3, G,H,I映射为4, J,K,L映射为5, M,N,O映射为6, P,Q,R,S映射为7, T,U,V映射为8, W,X,Y,Z映射为9.
因此, dialer.db 数据库终于更新和映射完成了,进行匹配查询的时候可以不用查询contacts2.db数据库,直接查询dialer.db 数据库就可以了。















 2198
2198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









