







 本文介绍了如何在面临大量小文件数据处理难题时,通过GNU Parallel工具实现单机上的并行处理,有效提升效率。讨论了cat命令的限制,以及使用简单遍历方法的低效,并详细解释了GNU Parallel的工作原理和优化效果,提供不同操作系统下的安装指南。
本文介绍了如何在面临大量小文件数据处理难题时,通过GNU Parallel工具实现单机上的并行处理,有效提升效率。讨论了cat命令的限制,以及使用简单遍历方法的低效,并详细解释了GNU Parallel的工作原理和优化效果,提供不同操作系统下的安装指南。
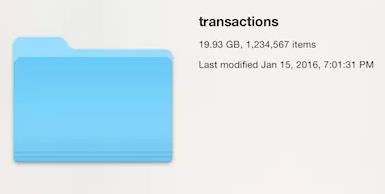
进行数据处理的时候我们经常会遇到这样的情况:一个数据集由一大堆很小的文件组成,这些小文件格式相同,可能是系统的日志文件或者产自传感器等终端。如下图:1234567个文件的总和才20GB左右。
处理这样的数据集给我们带来了如下的问题:
1) 当数据分散在这些大量的独立的小文件的时候,分析很困难。
2) 这些文件的总和超出了单机内存的容量,无法一次性全部载入,处理起来效率很低。
3) 使用分布式框架如hadoop虽然不用担心文件总大小的问题,但是单个文件又太小,HDFS中文件都是以block(64M)的形式存储,实际上HDFS主要是为了流式的访问大文件而设计的,处理大量小文件时候的效率非常低。
所以,我们能不能在单机上将这百万级数量的文件拼接成一个大文件后再处理?
使用linux操作系统的人想必对cat命令相当熟悉,cat命令可以将多个文件拼接成一个文件,这样,似乎一下子就可以解决文件数太多数据太分散的问题了。所以,我们很自然就有了如下的尝试:
$ cat * >> out.txt然而,结果却并非如我们所愿,居然报错了!
<pre name="code" class="plain">-bash: /bin/cat: Argument lis 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









