







1. 版本说明
本文档内容基于 flink-1.13.x,其他版本的整理,请查看本人博客的 flink 专栏其他文章。
2. 概述
Flink 是一种通用性框架,支持多种不同的部署方式。
本章简要介绍 Flink 集群的组成部分、用途和可用实现。如果你只是想在本地启动一个 Flink,我们建议你部署一个 Standalone 集群。
2.1. 概述和架构详解
下图展示的是每个 Flink 集群的组成部分。首先会有一个在某处一直运行的客户端,这个客户端会将 Flink 应用程序中的代码转换为 JobGraph,并将其提交给 JobManager。
JobManager 会将任务分布到 TaskManager 中,TaskManager 会一直运行真正的算子,比如:source、转换、sink。
在部署 Flink 时,会有多个组成部分参与部署,我们已经将他们放到了下图下面的表格中。

| 组件Component | 作用 | 实现方式 |
|---|---|---|
| Flink Client | 编译批或流程序为工作流执行图,之后该执行图会被提交给 JobManager。 | Command Line Interface REST Endpoint SQL Client Python REPL Scala REPL |
| JobManager | JobManager 是 Flink 工作协调组件的名称,JobManager 根据高可用、资源收集行为和支持的任务提交模式的不同,对不同的资源提供者有不同的实现。 JobManager 的任务提交模式: Application 模式:对每个程序单独运行一个集群,作业的主函数或客户端会在 JobManager 中执行。可以在一个程序中多次调用 execute/executeAsync。Per-Job 模式:对每个作业单独运行一个集群,作业的主函数或客户端只会在创建集群之前运行。 Session 模式:一个集群中运行多个作业的 TaskManager 会共享一个 JobManager。 | Standalone,这是 Flink 集群的标准模式,它只要求启动多个 JVM。通过 Docker, Docker Swarm / Compose, non-native Kubernetes 和其他模型部署这种模式也是可行的。 Kubernetes YARN Mesos |
| TaskManager | TaskManager 是真正执行 Flink 作业任务的服务。 | |
| 外部组件 (均可选) | ||
| 高可用服务提供者 | Flink 的 JobManager 可以在高可用模式下运行,该方式允许 Flink 作业在 JobManager 失败时进行恢复。为了更快的失败恢复,可以启动多个备用 JobManager。 | Zookeeper Kubernetes HA |
| 文件存储和持久化 | 对于用来恢复流作业的 checkpointing 来说,Flink 需要外部文件存储系统。 | 具体查看 FileSystems |
| 资源提供者 | Flink 可以通过不同的资源提供框架来部署,比如:Kubernetes、YARN、Mesos。 | 具体查看 JobManager 实现 |
| 指标存储 | Flink 组件会上报自己内部指标,Flink 作业也可以上报额外的作业特定的指标。 | 具体查看 指标上报 |
| 应用程序级别的数据 source 和 sink | 当应用程序级别的数据 source 和 sink 对应的组件不是 Flink 集群组件的一部分时,在计划新的 Flink 生产部署时,应该单独处理一下他们。将在 flink 作业中频繁使用的数据 source 和 sink 对应组件的依赖和 flink 放到一起可以显著提升性能。 | 比如: Apache Kafka Amazon S3 ElasticSearch Apache Cassandra 具体查看 Connectors |
2.2. 部署模式
可以通过以下三种方式中的一种执行 Flink 程序:
- Application Mode
- Per-Job Mode
- Session Mode
上面模式的不同点:
- 集群生命周期和资源隔离保证
- 应用程序的
main()方法是在客户端执行还是在集群上执行

2.2.1. Application Mode
在其他所有的模式中,应用程序的 main() 方法都是在客户端侧执行,该执行步骤包括在本地下载应用程序依赖、执行 main() 方法来提取 Flink 运行时可以理解的代表物,比如 JobGraph、以及上传依赖和 JobGraph 到集群,这会造成客户端消耗大量的资源,包括占用一定的网络宽带来下载依赖并且上传二进制包到集群,占用 CPU 周期来执行 main() 方法。该问题在多个用户共享客户端时会更加明显。
Application 模式会对每个提交的程序创建一个集群,并且在 JobManager 中执行应用的 main() 方法。对每个应用创建一个集群的行为,可以将其看做为对一个作业单独创建了一个 session 集群,并且在应用程序完成后关闭。在这个架构下,Application 模式和 Per-Job 模式有相同的资源隔离和负载均衡保证,但其粒度是整个应用程序。
Application 模式会假设用户的 jar 已经在 classpath (usrlib 目录)中,并且 Flink 所有的组件(JobManager、TaskManager)都可以访问他们。换句话说,你的程序已经和 Flink 分布式捆绑到一起了。这种方式可以加快应用程序的部署和恢复进程,但是并不需要像其他模式模式一样通过 RPC 来分布式传输用户 jar 到 Flink 组件。
Application 模式会假设用户的 jar 已经在 classpath 中了。
在集群上执行
main()方法对你的代码来说可能还有其他的含义,比如你在环境中使用registerCachedFile()注册的任何路径,都必须可以被 JobManager 访问。注:如果这个路径对应的是本地文件,但是你把你的 Flink 程序部署到容器中了,则启动的 JobManager 就无法访问这个路径了。
相比于 Per-Job 模式,Application 模式运行程序提交多个作业组合的应用程序。作业执行的顺序不受部署模式的影响,而是受作业中启动方法调用的影响。
- 使用
execute()函数会造成阻塞,这会导致下个作业只能在当前这个作业完成后才会启动。 - 使用
executeAsync()函数不会造成阻塞,在当前作业完成之前,下个作业也会启动。
Application 模式运行允许包含多个
execute()函数调用的程序,但是在这种情况下不支持高可用。Application 模式的高可用只支持包含单个execute()函数调用的程序。另外,当在 Application 模式下运行的包含多个作业的程序(比如通过调用
executeAsync()方法),其中任何一个作业被取消,则所有的作业都会被停止,并且 JobManager 也会停止。支持常规作业的完成,比如 source 关闭。
2.2.2. Per-Job模式
为了提供更好的资源隔离保证,Per-Job 模式使用资源提供者框架(比如:YARN、Kubernetges)对每个提交的作业都会启动一个集群,该集群只对这个作业可用。当作业完成时,集群会关闭,并且清除所有的缓存资源,比如文件。这可以保证更好的资源隔离,对于有问题的作业,只能关闭它自己的 TaskManager。另外,该模式会将压力分散给多个 JobManager,以为每个作业都有一个 JobManager。因此,Per-Job 资源分配模型是很多生产案例的首选。
2.2.3. Session模式
Session 模式假设已经有一个正在运行的集群了,并且使用该集群的资源来执行被提交的作业。同一个 session 集群中运行的程序会使用相同的资源进行计算。这样做的好处是,你无需为每个提交的作业启动一个完整的集群而消耗更多的资源。但是,如果某个有问题的作业造成 TaskManager 停止,则所有运行在该 TaskManager 上的作业都会被停止。除了失败的作业会造成负面影响外,还还意味着可能会出现大规模作业恢复,所有重新启动的作业都会并发地访问文件系统,使其他服务无法使用该文件系统。此外,让一个集群运行多个作业意味着 JobManager 将承受更多的负载,JobManager 需要负责集群中所有作业的监控。
2.2.4. 总结
在 Session 模式中,集群的生命周期独立于集群中运行的任何作业,并且所有的作业都可以共享资源。Per-Job 模式对每个被提交的作业都会单独的集群而造成额外的资源消耗,但是这会有更好的资源隔离保证,资源并不会在作业之间共享。这种情况下,集群的生命周期绑定与在其上运行的作业。最后,Application 模式会对每个程序创建一个 session 集群,并且在集群中执行应用程序的 main() 方法。
2.3. 供应商解决方案
很多供应商都提供了管理或全套的 Flink 解决方案,但是这些供应商都没有得到 Apache Flink PMC 的官方支持,请参考供应商的文档说明来了解如何在生产上使用他们。
2.3.1. 阿里云实时计算
支持环境: 阿里云
2.3.1.1. Amazon EMR
支持环境: AWS
2.3.1.2. Amazon Kinesis Data
支持环境: AWS
2.3.1.3. Cloudera DataFlow
支持环境: AWS Azure Google On-Premise
2.3.1.4. Eventador
支持环境: AWS
2.3.1.5. 华为云流服务
支持环境: 华为
2.3.1.6. Ververica平台
支持环境: AliCloud、 AWS、 Azure、 Google、 On-Premise
3. 资源提供者
3.1. Standalone
暂不做翻译
3.2. 原生Kubernetes
该章描述如何原生地部署 flink 到 Kubernetes 上。
3.2.1. 入门指南
该入门指南章节会指导你在 Kubernetes 上安装一个完成功能的 flink 集群。
3.2.2. 概述
Kubernetes 是一个受欢迎的容器管理系统,它可以自动完成应用程序部署,扩容和管理。flink 的原生 Kubernetes 整合允许你直接将 flink 部署到一个正在运行的 Kubernetes 集群上。另外,取决于请求的资源,flink 也可以动态分配和清理 TaskManager,因为 flink 可以直接和 Kubernetes 对话。
3.2.2.1. 准备
入门指南章节假设已经运行的 Kubernetes 就能已经满足了以下要求:
- Kubernetes >= 1.9.
- 可以通过
~/.kube/config列出、创建、删除 pod 和服务的 KubeConfig,可以通过运行kubectl auth can-i <list|create|edit|delete> pods命令来校验权限。 - 启用 Kubernetes DNS.
- 默认服务账号有创建、删除 pod 的 RBAC 权限。
如果有部署Kubernetes 集群的疑问,可以参考 如何部署 Kubernetes 集群。
3.2.2.2. 在Kubernetes上启动Flink Session
一旦你有了一个正在运行的Kubernetes 集群,并且配置了 kubectl 来指向它,你就可以通过以下方式来启动一个 Session 模式 的 flink 集群:
# (1) 启动 Kubernetes 会话
$ ./bin/kubernetes-session.sh -Dkubernetes.cluster-id=my-first-flink-cluster
# (2) 提交 flink 案例 job
$ ./bin/flink run \
--target kubernetes-session \
-Dkubernetes.cluster-id=my-first-flink-cluster \
./examples/streaming/TopSpeedWindowing.jar
# (3) 通过删除集群部署来停止 Kubernetes 会话
$ kubectl delete deployment/my-first-flink-cluster
在使用 Minikube 时,你需要调用
minikube tunnel以在Minikube 上暴露 Flink 的负载平衡服务
恭喜!你已经成功地通过在 Kubernetes 上部署 flink 来运行 flink 程序了。
3.2.3. 部署模式
对于生产案例,我们建议使用 Application 模式 来部署 flink 程序,该模式对程序提供了很好的隔离性。
3.2.3.1. Application模式
请参考 部署模式概述 来获取 application 模式更高级的相关知识。
Application 模式 要求用户代码已经和 flink 镜像捆绑到一起了,因为该模式会在集群上运行用户代码的 main() 方法,application 模式会在程序终止后确保清除所有的 flink 组件。
flink 社区提供了一个可以被用于捆绑用户代码的 基础 Docker 镜像。
FROM flink
RUN mkdir -p $FLINK_HOME/usrlib
COPY /path/of/my-flink-job.jar $FLINK_HOME/usrlib/my-flink-job.jar
在使用**自定义镜像名称 custom-image-name **创建和发布了 Docker 镜像之后,你就可以通过如下命令来启动一个 application 集群了:
$ ./bin/flink run-application \
--target kubernetes-application \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.container.image=custom-image-name \
local:///opt/flink/usrlib/my-flink-job.jar
注:local 只支持 Application 模式 schema。
kubernetes.cluster-id 选项用来指定集群名称,并且是必选项。如果没有指定该选项,则 Flink 会生成一个随机名称。
kubernetes.container.image 选项指定启动 pod 的镜像。
application 集群一旦部署完毕,你就可以与它互动了:
# 列出集群上运行的 job
$ ./bin/flink list --target kubernetes-application -Dkubernetes.cluster-id=my-first-application-cluster
# 取消运行的 job
$ ./bin/flink cancel --target kubernetes-application -Dkubernetes.cluster-id=my-first-application-cluster <jobId>
你可以通过在 bin/flink 后设置 -Dkey=value 格式的 key-value 对来覆盖 conf/flink-conf.yaml 中的配置。
3.2.3.2. Per-Job模式
请参考 部署模式概述 来获取 per-job 模式更高级的相关知识。
Flink on Kubernetes 不支持 Per-Job 集群模式。
3.2.3.3. Session模式
请参考 部署模式概述 来获取 application 模式更高级的相关知识。
已经在上面的入门指南章节中描述了如何部署一个 Session 集群了。
Session 模式可以通过两种模式执行:
- detached mode (分离模式,默认):
kubernetes-session.sh脚本会在 Kubernetes 上部署 flink 集群,然后终止本地客户端。 - attached mode (附加模式,
-Dexecution.attached=true):kubernetes-session.sh本地客户端会保持运行,并且允许使用命令来控制运行的 flink 集群。比如通过stop命令来停止正在运行的 Session 集群,通过help命令来列出所有支持的命令。
可以通过如下命令来重新附加正在运行的 Session 集群到 my-first-flink-cluster 集群 id 上:
$ ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dexecution.attached=true
你可以通过在运行 bin/kubernetes-session.sh 脚本时添加 -Dkey=value 格式的 key-value 对来覆盖 conf/flink-conf.yaml 文件中的配置。
3.2.3.3.1. 停止运行的Session集群
你可以通过删除 Flink 部署 或使用如下命令来停止 cluster id 为 my-first-flink-cluster 的 Session 集群:
$ echo 'stop' | ./bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=my-first-flink-cluster \
-Dexecution.attached=true
3.2.4. Flink on Kubernetes指南
3.2.4.1. 在Kubernetes上配置Flink
可以在配置页面 找到 Kubernetes 相关配置选项。
flink 通过 Fabric8 Kubernetes client 和 Kubernetes APIServer进行交互,以 创建/删除 Kubernetes 资源,比如:部署、Pod、ConfigMap、Service 等,同时也包括查看 Pod 和 ConfigMap。除了上面提到的 flink 配置选项,也可以通过系统属性或环境变量配置的专家选项来配置 Fabric8 Kubernetes 客户端。
比如,用户可以通过下面的 Flink 配置选项来设置最大的并发请求数,该配置允许 Kubernetes HA 服务在 session 集群上运行更多的 job。请注意,每个 Flink job 将会消耗 3 个并发请求。
containerized.master.env.KUBERNETES_MAX_CONCURRENT_REQUESTS: 200
env.java.opts.jobmanager: "-Dkubernetes.max.concurrent.requests=200"
3.2.4.2. 访问Flink Web UI
可以通过 kubernetes.rest-service.exposed.type 配置选项来暴露 Flink 的 Web UI 和 REST 终端服务。
- ClusterIP:暴露服务的集群内部 IP,该服务只能在集群内部访问。如果想要访问 JobManager UI 或提交 job 到已存在会话,你需要启动一个本地代理。之后,你就可以通过访问
localhost:8081来提交一个 flink job 到会话或查看 dashboard了。
$ kubectl port-forward service/<ServiceName> 8081
- NodePort:使用指定的端口号(
NodePort)来暴露每个节点 IP 上的服务。可以通过<NodeIP>:<NodePort>来连接 JobManager 服务,也可以通过 Kubernetes ApiServer 地址来代替NodeIP。可以在 kube 配置文件中找到这个地址。 - LoadBalancer:负载均衡,使用云提供商的负载均衡器对外公开服务。因为云提供商和 Kubernetes 需要一些时间来准备负载均衡,因此你可以通过客户端日志来获取 JobManager Web 接口的
NodePort。你可以使用命令kubectl get services/<cluster-id>-rest来获取 EXTERNAL-IP,然后手动构造负载均衡的 JobManager Web 接口:http://<EXTERNAL-IP>:8081
请参考官网文档在 Kubernetes 上发布服务来获取更多信息。
取决于你的实际环境,通过
LoadBalancerREST 服务启动 flink 集群,可能会让集群公开访问,这通常会让集群可以执行任意代码。
3.2.4.3. 日志
Kubernetes 会整合 conf/log4j-console.properties 和 conf/logback-console.xml 为一个 ConfigMap,然后暴露给 pod。对这些文件的改变对新启动的集群是可见的。
3.2.4.4. 访问日志
默认情况下,JobManager 和 TaskManager 会将日志输出到控制台,同时写入到每个 pod 的 /opt/flink/log 目录下。STDOUT 和 STDERR 只会直接输出到控制台,可以通过下面的命令访问他们:
$ kubectl logs <pod-name>
如果 pod 正在运行,你也可以使用 kubectl exec -it <pod-name> bash 来查看日志或对运行进行 debug 调试。
3.2.4.4.1. 访问TaskManagers日志
为了不浪费资源,flink 会自动清除空闲的 TaskManager,该行为会导致访问每个 pod 的日志更加困难。你可以通过配置 resourcemanager.taskmanager-timeout 来增加 TaskManager 的空闲时间,以让自己有更多的时间来查看日志文件。
3.2.4.4.2. 动态改变日志级别
如果你已经配置你的日志记录器可以自动获取配置更改,则你可以通过更改单独的 ConfigMap 来动态调整日志级别,假设 Cluster id 为 my-first-flink-cluster,则可以使用如下命令进行更改:
$ kubectl edit cm flink-config-my-first-flink-cluster
3.2.4.5. 使用插件
为了使用插件,你必须将他们拷贝到 Flink JobManager/TaskManager pod 中的正确位置。你可以使用无需挂载卷的内置插件,或构建一个自定义 Docker 镜像。比如,使用如下命令对你的 Flink session 集群启用 S3 插件:
$ ./bin/kubernetes-session.sh
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.13.6.jar \
-Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.13.6.jar
3.2.4.6. 自定义Docker镜像
如果你想使用自定义 Docker 镜像,则可以通过配置选项 kubernetes.container.image 来指定它,Flink 社区提供了一个非常好用的 Flink Docker 镜像 。通过如何自定义 Flink’s Docker 镜像查看如何启用插件,增加依赖,以及其他选项。
3.2.4.7. 使用隐私
Kubernetes Secrets 是一个包括一些隐私数据的对象,比如密码,token,或 key。这些信息可能会放在一个 pod 或镜像中。Flink on Kubernetes 可以通过两种方式使用这些隐私:
- 通过 pod 文件使用隐私
- 通过环境变量使用隐私
3.2.4.7.1. 在Pod中使用隐私文件
下面的命令会将名为 mysecret 的隐私挂载到标准 pod 下的 /path/to/secret 目录:
$ ./bin/kubernetes-session.sh -Dkubernetes.secrets=mysecret:/path/to/secret
名为 mysecret 的隐私中的用户名和密码可以在 /path/to/secret/username 和 /path/to/secret/password 文件中找到。查看 Kubernetes 官网文档 获取更多细节。
3.2.4.7.2. 将隐私作为环境变量
下面的命令可以将标准 pod 中名为 mysecret 的隐私暴露为环境变量:
$ ./bin/kubernetes-session.sh -Dkubernetes.env.secretKeyRef=\
env:SECRET_USERNAME,secret:mysecret,key:username;\
env:SECRET_PASSWORD,secret:mysecret,key:password
环境变量 SECRET_USERNAME 包含用户名,SECRET_PASSWORD 包含密码。查看 Kubernetes 官网文档 获取更多细节。
3.2.4.8. on Kubernetes高可用
对于 on Kubernetes 高可用,可以查看高可用服务。
给 kubernetes.jobmanager.replicas 配置一个大于 1 的值来启动备用 JobManager,以此来达到更快的恢复。注意,在启动备用 JobManager 时,需要启用高可用。
3.2.4.9. 手动清理资源
Flink 使用 Kubernetes OwnerReference’s 来清理所有的集群组件。所有 Flink 创建的资源,包括 ConfigMap、Service 和 Pod,都有被设置到 deployment/<cluster-id> 中的 OwnerReference。当部署被删除时,所有相关联的资源都会被自动删除。
$ kubectl delete deployment/<cluster-id>
3.2.4.10. 支持的Kubernetes版本
目前,所有 >= 1.9 版本的 Kubernetes 都支持。
3.2.4.11. 命名空间
Kubernetes 命名空间通过资源配额在多个用户之间集群资源。Flink on Kubernetes 可以使用命名空间来启用 Flink 集群。可以通过 kubernetes.namespace 配置命名空间。
3.2.4.12. RBAC
Role-based access control (RBAC) 是企业中基于角色的单个用户访问计算和网络资源的常规方法吗,用户可以配置用于 JobManager 访问 kubernetes 集群内的 Kubernetes API 服务的 RBAC 角色和服务账号。
每个命名空间都有默认的服务账号,但是默认的服务账号可能没有访问和删除 Kubernetes 集群内 pod 的权限,用户可能需要更新默认服务账号的权限,或指定其他绑定了正确角色的服务账号。
$ kubectl create clusterrolebinding flink-role-binding-default --clusterrole=edit --serviceaccount=default:default
如果你不想使用默认服务账号,可以使用如下命令创建一个新的名为 flink-service-account 的服务账号,并且设置角色绑定,然后使用配置选项 -Dkubernetes.service-account=flink-service-account 让 JobManager pod 使用 flink-service-account 服务账号来创建或删除 TaskManager pod 和 leader ConfigMap,新的账号也允许 TaskManager 查看 leader ConfigMap 来检索 JobManager 和 ResourceManager 的地址。
$ kubectl create serviceaccount flink-service-account
$ kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=default:flink-service-account
请参考官网 Kubernetes 文档 RBAC Authorization 来获取更多信息。
3.2.4.13. Pod模板
Flink 允许通过模板文件来定义 JobManager 和 TaskManager pod,这种方式支持使用 Flink Kubernetes 配置选项 中没有直接支持的高级特性。使用 kubernetes.pod-template-file 来指定包含 pod 定义的本地文件,该文件将被用于初始化 JobManager 和 TaskManager。主要的容器名称应该被定义为 flink-main-container。请看考 pod 模板案例 来获取更多信息。
3.2.4.13.1. 通过Flink覆盖属性
一些 pod 模板文件中的属性会被 flink 覆盖,解析有效属性值的算法如下:
-
Defined by Flink:用户无法配置这些属性。
-
Defined by the user:用户可以自由的指定这些属性值,Flink 框架不会设置任何源于配置选项和模板的额外值和有效值。
优先顺序:首先采用指定的配置选项中的值,然后取 pod 模板中的值,如果都没有指定,则最后采用配置选项的默认值。
-
Merged with Flink:Flink 会合并用户定义的值,遵循上面的优先顺序,在遇到同名字段的情况下,Flink 值具有优先级。
参考下面表中列出的所有可以被覆盖的 pod 属性,pod 模板中定义的所有未在下表列出的属性值都不会起作用。
Pod 元数据
| 键 | 种类 | 关联的配置选项 | 描述 |
|---|---|---|---|
| name | Defined by Flink | JobManager pod 名称将会被在部署中定义的 kubernetes.cluster-id 覆盖。TaskManager pod 名称将会被 Flink ResourceManager 生成的 <clusterID>-<attempt>-<index> 覆盖。 | |
| namespace | Defined by the user | kubernetes.namespace | JobManager 部署和 TaskManager pod 都会在用户指定的命名空间中创建。 |
| ownerReferences | Defined by Flink | JobManager 和 TaskManager pod 的所有者参考经常被设置为 JobManager 部署,请参考 kubernetes.jobmanager.owner.reference 来控制何时删除部署。 | |
| annotations | Defined by the user | kubernetes.jobmanager.annotations kubernetes.taskmanager.annotations | Flink 将增加通过 Flink 配置选项指定的额外注释。 |
| labels | Merged with Flink | kubernetes.jobmanager.labels kubernetes.taskmanager.labels | Flink 会增加一些内置的标签到用户自定义的值上。 |
Pod 属性
| 键 | 种类 | 关联的配置选项 | 描述 |
|---|---|---|---|
| imagePullSecrets | Defined by the user | kubernetes.container.image.pull-secrets | Flink 会增加通过 Flink 配置选项指定的额外拉取到的隐私。 |
| nodeSelector | Defined by the user | kubernetes.jobmanager.node-selector kubernetes.taskmanager.node-selector | Flink 会增加通过 Flink 配置选项指定的额外的节点选择器。 |
| tolerations | Defined by the user | kubernetes.jobmanager.tolerations kubernetes.taskmanager.tolerations | Flink 会增加通过 Flink 配置选项指定的额外的容错。 |
| restartPolicy | Defined by Flink | 通常指定 JobManager pod ,从来不指定 TaskManager pod。JobManager pod 通常会被部署重启,TaskManager 不应该被重启。 | |
| serviceAccount | Defined by the user | kubernetes.service-account | JobManager 和 TaskManager pod 将会通过用户定义的服务账号来创建。 |
| volumes | Merged with Flink | Flink 会增加一些内置的 ConfigMap 卷,比如:flink-config-volume,hadoop-config-valute,以用来传递 Flink 配置和 hadoop 配置。 |
主容器属性
| 键 | 种类 | 关联的配置选项 | 描述 |
|---|---|---|---|
| env | Merged with Flink | containerized.master.env.{ENV_NAME} containerized.taskmanager.env.{ENV_NAME} | Flink 会增加一些内置的环境变量到用户自定义的值上。 |
| image | Defined by the user | kubernetes.container.image | 容器镜像将根据用户自定义值的优先顺序进行解析。 |
| imagePullPolicy | Defined by the user | kubernetes.container.image.pull-policy | 容器镜像拉取策略将根据用户自定义值的优先顺序进行解析。 |
| name | Defined by Flink | 容器名称将会被 Flink 的 “flink-main-container” 值覆盖。 | |
| resources | Defined by the user | Memory: jobmanager.memory.process.size taskmanager.memory.process.size CPU: kubernetes.jobmanager.cpu kubernetes.taskmanager.cpu | 内存和 cpu 资源(包括请求和限制)将会被 Flink 的配置选项覆盖,所有其他的资源(比如临时存储)将会被留下。 |
| containerPorts | Merged with Flink | Flink 会增加一些内置的容器端口号,比如:rest、jobmanager-rpc、blob、taskmanager-rpc。 | |
| volumeMounts | Merged with Flink | Flink 会增加一些内置的卷挂载,比如:flink-config-volume、hadoop-config-volume,这对于传递 flink 配置和 hadoop 配置是很有必要的。 |
3.2.4.13.2. Pod模板案例
pod-template.yaml
apiVersion: v1
kind: Pod
metadata:
name: jobmanager-pod-template
spec:
initContainers:
- name: artifacts-fetcher
image: artifacts-fetcher:latest
# 使用 wget 或其他工具从远程存储获取用户 jar
command: [ 'wget', 'https://path/of/StateMachineExample.jar', '-O', '/flink-artifact/myjob.jar' ]
volumeMounts:
- mountPath: /flink-artifact
name: flink-artifact
containers:
# 不要修改主容器名称
- name: flink-main-container
resources:
requests:
ephemeral-storage: 2048Mi
limits:
ephemeral-storage: 2048Mi
volumeMounts:
- mountPath: /opt/flink/volumes/hostpath
name: flink-volume-hostpath
- mountPath: /opt/flink/artifacts
name: flink-artifact
- mountPath: /opt/flink/log
name: flink-logs
# 使用 sidecar 容器推送日志到远程存储或做一些其他的 debug 事情
- name: sidecar-log-collector
image: sidecar-log-collector:latest
command: [ 'command-to-upload', '/remote/path/of/flink-logs/' ]
volumeMounts:
- mountPath: /flink-logs
name: flink-logs
volumes:
- name: flink-volume-hostpath
hostPath:
path: /tmp
type: Directory
- name: flink-artifact
emptyDir: { }
- name: flink-logs
emptyDir: { }
3.3. yarn
3.3.1. 入门指南
该入门指南章节会指导你在 YARN 上配置一个完整的 Flink 集群。
3.3.1.1. 概述
Apache Hadoop YARN 是很多数据处理框架爱用的资源提供者,Flink 服务可以提交到 YARN 的 ResourceManager,然后通过 YARN 的 NodeManager 来提供容器,然后 Flink 会部署他的 JobManager 和 TaakManager 示例到这些容器上。
Flink 可以基于在 JobManager 上运行的 job 所需要的 slot 来动态收集和清理 TaskManager 资源。
3.3.1.2. 准备
入门指南章节假定已经有一个可用的 YARN 环境了,并且版本号 ≥ 2.4.1。YARN 环境可以通过 Amazon EMR、Google Cloud DataProc 或 Cloudera 产品来很方便的提供。该入门指南并不要求手动部署本地 YARN 环境 或 集群部署 。
- 可以通过运行
yarn top来确定你的 YARN 集群已经准备好接收 Flink 程序了,该命令应该不展示任何错误信息。 - 从 下载页面 下载 Flink 分布式文件,并解压。
- 重要:请确保已经设置了
HADOOP_CLASSPATH环境变量,可以通过运行echo $HADOOP_CLASSPATH命令来检查。如果没有设置,请通过以下命令来设置:
export HADOOP_CLASSPATH=`hadoop classpath`
3.3.1.3. 在yarn上启动flink session
确保设置了 HADOOP_CLASSPATH 环境变量之后,就可以启动 YARN session 了,并且提交案例 job:
# 假定在 root 目录下解压了 Flink 分布式文件
# (0) export HADOOP_CLASSPATH
export HADOOP_CLASSPATH=`hadoop classpath`
# (1) 启动 YARN Session
./bin/yarn-session.sh --detached
# (2) 你可以通过命令行输出打印的最有一行中的 URL 或通过 YARN ResourceManager web UI 来访问 Flink web 页面
# (3) 提交案例 job
./bin/flink run ./examples/streaming/TopSpeedWindowing.jar
# (4) 停止 YARN session,请将下面的 application id 替换为 yarn-session.sh 命令输出的 application id
echo "stop" | ./bin/yarn-session.sh -id application_XXXXX_XXX
恭喜!你已经成功的通过部署 Flink on YARN 来运行 Flink 程序了。
3.3.2. Flink on YARN支持的部署模式
对于生产案例,我们建议使用 Per-job 或 Application 模式 来部署 Flink 程序,这些模式对程序有更好的隔离性。
3.3.2.1. Application模式
请参考 deployment 模式概述 来获取 application 模式的高级知识。
Application 模式将在 YARN 上启动一个 Flink 集群,然后运行在 YARN 中的 JobManager 执行应用程序中的 main() 方法。集群将会在程序运行完成后马上关闭,也可以使用 yarn application -kill <ApplicationId> 或通过取消 Flink job 来停止集群。
./bin/flink run-application -t yarn-application ./examples/streaming/TopSpeedWindowing.jar
一旦部署了 Application 模式的集群,你就可以与它进行交互操作,比如取消或触发 savepoint。
# 列出集群中运行的 job
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
# 取消运行的 job
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
注意,取消 Application 集群中的 job 将会停止集群。
为了发挥 application 模式的所有潜力,可以考虑使用 yarn.provided.lib.dirs 配置选项并且提前上传你的应用程序 jar 到一个可以被集群所有节点访问的位置,具体命令如下:
./bin/flink run-application -t yarn-application \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" \
hdfs://myhdfs/jars/my-application.jar
上述命令可以让 job 提交更加轻量,因为需要的 Flink jar 和应用程序 jar 可以通过指定的远程位置获取,而不是通过客户端上传到集群。
3.3.2.2. Per-Job模式
请参考 deployment 模式概述 来获取 per-job 模式的高级知识。
Per-job 集群模式会在 YARN 上启动一个 Flink 集群,然后在本地运行提供的程序 jar 包,最后将 JobGraph 提交到 YARN 中的 JobManager。如果你指定了 --detached 参数,本地客户端会在提交被接受之后马上停止。
YARN 中的 per-job 集群会在 job 停止之后马上停止。
./bin/flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindowing.jar
Per-job 集群一旦部署完毕,你就可以进行和它进行交互操作了,比如取消 job ,或触发一个 savepoint。
# 列出集群运行的 job
./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
# 取消运行的 job
./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
注意,取消 per-job 集群中的 job,将会停止 per-job 集群。
3.3.2.3. Session模式
请参考 deployment 模式概述 来获取 application 模式的高级知识。
我们已经在上面的入门指南中说明了 Session 模式的部署。
Session 模式有两种操作模式:
- attached mode(默认):
yarn-session.sh客户端提交 Flink 集群到 YARN,但是本地客户端依然会保持运行,并且追踪集群的状态。如果集群运行失败,则客户端会展示错误信息。如果客户端被终止,它也会给集群发送关闭信号。 - detached mode (
-dor--detached):yarn-session.sh客户端提交 Flink 集群到 YARN,然后客户端返回。要停止 Flink 客户端,则需要调用其他的客户端,比如 YARN tools。
session 模式会在 /tmp/.yarn-properties-<username> 中创建一个隐藏的配置文件,该配置文件会在提交 job 时被通过命令行接口集群获取。
你也可以在提交 Flink job 的命令行接口中手动指定目标 YARN 集群,示例如下:
./bin/flink run -t yarn-session \
-Dyarn.application.id=application_XXXX_YY \
./examples/streaming/TopSpeedWindowing.jar
你可以通过下面的命令重新附加到一个 YARN session 集群:
./bin/yarn-session.sh -id application_XXXX_YY
除了通过 conf/flink-conf.yaml 文件指定 配置 之外,你也可以在使用 ./bin/yarn-session.sh 提交时使用 -Dkey=value 参数来指定任何配置。
YARN session 客户端也有一些“短参数”用于设置,可以通过运行 ./bin/yarn-session.sh -h 命令来列出他们。
3.3.3. Flink on YARN参考
3.3.3.1. 在YARN上配置flink
在 配置页面 可以找到 YARN 的所有配置。
下面的配置参数通过 Flink on YARN 来管理,他们可以在框架运行时被覆盖:
jobmanager.rpc.address:被动态设置为 Flink on YARN 中运行 JobManager 容器的地址io.tmp.dirs:如果没有设置,Flink 将会设置为通过 YARN 定义的临时目录high-availability.cluster-id:在 HA 服务中会自动生成 ID 来区分多个集群
你可以通过 HADOOP_CONF_DIR 环境变量将额外的 Hadoop 配置文件传递给 Flink,该变量接收一个包含 Hadoop 配置文件的目录。默认情况下,所有需要的 Hadoop 配置文件都是通过 HADOOP_CLASSPATH 环境变量来获取并加载的。
3.3.3.2. 资源分配
如果无法使用已获取到的资源运行提交的 job,则运行在 YARN 上的 JobManager 会请求额外的 TaskManager 资源。在指定的 session 模式下运行时,如果需要,则 JobManager 会收集额外的 TaskManager 资源来运行提交的其他 Job。不再使用的 TaskManager 将会在超时之后被清理。
YARN 实现了 JobManager 和 TaskManager 的 process 内存配置,上报的 VCore 数量默认等于每个 TaskManager 配置的 slot 数量。yarn.containers.vcores 允许指定自定义值来覆盖 vcore 的数量,为了让这个参数生效,需要开启 YARN 集群的 CPU 调度。
失败的容器(包括 JobManager)将会被 YARN 换下。可以通过 yarn.application-attempts(默认为1)来配置 JobManager 容器重启的最大次数。一旦耗尽所有的尝试,则 YARN 程序将会失败。
3.3.3.3. on YARN高可用
on YARN 高可用可以通过 YARN 和 高可用服务 组合实现。
一旦配置了 HA 服务,它将会持久化 JobManager 元数据,并执行 leader 选举。
YARN 会进行失败 JobManager 的重启工作。JobManager 的重启最大次数通过两个配置参数定义:
- flink 的 yarn.application-attempts 配置,默认值为 2。
- YARN 的 yarn.resourcemanager.am.max-attempts 配置,默认值也是 2,但该配置值会限制上面的配置值。
注意,当部署为 on YARN 时,Flink 会管理 high-availability.cluster-id 配置参数,Flink 会设置该值为默认的 YARN application id。在 YARN 上部署高可用集群时不要覆盖该参数。存储到 HA 后端(比如 zookeeper)的 cluster ID 被用于区分不同的高可用集群。覆盖该配置参数会导致多个 YARN 集群影响彼此。
3.3.3.3.1. 容器关闭行为
- 2.3.0 < YARN version < 2.4.0:如果 application master 出现失败,则所有的容器都会被重启。
- 2.4.0 < YARN version < 2.6.0:在 application master 出现失败时,TaskManager 容器依然会保持运行。该行为的优点是:启动速度会更快,而且用户无需再次获取容器资源。
- YARN version >= 2.6.0:失败重试的时间间隔设置为 Flink 的 Akka 超时时间。失败重试时间间隔说的是:只有系统在一个间隔发现应用程序尝试了最大次数后,该程序才会被杀死。这可以避免长时间的 job 耗尽他的尝试次数。
Hadoop YARN 2.4.0 有个大 bug(已经在 2.5.0 中修复):YARN 会阻止从一个已经启动的 Application Master/JobManager 容器上重启容器。查看 FLINK-4142 来获取更多细节。我们建议至少使用 Hadoop 2.5.0 来部署 YARN 高可用。
3.3.3.4. 支持的Hadoop版本
Flink on YARN 从 Hadoop 2.4.1 开始支持,支持所有 >= 2.4.1 版本的 Hadoop,包括 Hadoop 3.x。
为了提供 Flink 需要的 Hadoop 依赖,我们建议设置在入门指南章节提到的 HADOOP_CLASSPATH 环境变量。
如果无法进行上述设置,也可以将依赖放到 Flink 的 lib/ 目录下。
Flink 也提供了预打包的 Hadoop fat jar,可以将他们放到 lib/ 目录下,可以在 Downloads / Additional Components 页面找到他们。这些预打包的 fat jar 通过 shade 打包方式,避免了公共库的依赖冲突。Flink 社区没有测试这些预打包 jar 和 YARN 的整合。
3.3.3.5. 在YARN上运行flink并且开启防火墙
一些 YARN 集群会使用防火墙来控制集群和外网的通信,在这种配置下,Flink job 只能通过集群内网提交到 YARN session。如果在生产上不可行,Flink 允许对 REST 端点配置一个端口号范围,用于客户端与集群之间通信。通过配置端口号范围,用户就可以通过防火墙来提交 job 到 Flink 上了。
通过 rest.bind-port 配置参数来指定 REST 端点的端口号,该配置选项接受单个端口号(比如:50010)、范围(比如 50000-50025)、或同时使用两者。
3.3.3.6. 用户jar和Classpath
默认情况下,Flink 在运行单个 job 时会将用户的 jar 放到系统 classpath 中,该行为可以通过 yarn.per-job-cluster.include-user-jar 参数控制。
当设置该参数为 DISABLED 时,Flink 会将 jar 放到用户的 classpath 中。
用户 jar 在 classpath 中的位置可以通过设置 yarn.per-job-cluster.include-user-jar 参数为下面的某个值来控制:
ORDER:默认值,将 jar 按照字段序放到系统 classpath。FIRST:将 jar 放到系统 classpath 开头。LAST:将 jar 放到系统 classpath 最后。
4. 配置
该章节为 Flink 可以用到的所有配置,使用时直接去官网查看即可。
5. 内存管理
5.1. 设置Flink进程内存
Apache Flink 基于 JVM 的高效处理能力,依赖于其对各组件内存用量的细致掌控。考虑到用户在 Flink 上运行应用的多样性,尽管社区已经努力为所有配置项提供合理的默认值,但仍无法满足所有情况下的需求。为了给用户生产提供最大化的价值, Flink 允许用户在整体上以及细粒度上对集群的内存分配进行调整。
本文接下来介绍的内存配置方法适用于 1.10 及以上版本的 TaskManager 进程和 1.11 及以上版本的 JobManager 进程。 Flink 在 1.10 和 1.11 版本中对内存配置部分进行了较大幅度的改动,从早期版本升级的用户请参考升级指南。
5.1.1. 配置总内存
Flink JVM 进程的*进程总内存(Total Process Memory)*包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。 Flink 总内存(Total Flink Memory)包括 JVM 堆内存(Heap Memory)和堆外内存(Off-Heap Memory)。 其中堆外内存包括直接内存(Direct Memory)和本地内存(Native Memory)。
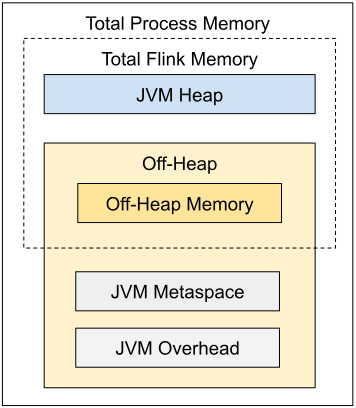
配置 Flink 进程内存最简单的方法是指定以下两个配置项中的任意一个:
| 配置项 | TaskManager 配置参数 | JobManager 配置参数 |
|---|---|---|
| Flink 总内存 | taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| 进程总内存 | taskmanager.memory.process.size | jobmanager.memory.process.size |
提示 关于本地执行,请分别参考 TaskManager 和 JobManager 的相关文档。
Flink 会根据默认值或其他配置参数自动调整剩余内存部分的大小。 关于各内存部分的更多细节,请分别参考 TaskManager 和 JobManager 的相关文档。
对于独立部署模式(Standalone Deployment),如果你希望指定由 Flink 应用本身使用的内存大小,最好选择配置 Flink 总内存。 Flink 总内存会进一步划分为 JVM 堆内存和堆外内存。 更多详情请参考如何为独立部署模式配置内存。
通过配置进程总内存可以指定由 Flink JVM 进程使用的总内存大小。 对于容器化部署模式(Containerized Deployment),这相当于申请的容器(Container)大小,详情请参考如何配置容器内存(Kubernetes、Yarn 或 Mesos)。
此外,还可以通过设置 Flink 总内存的特定内部组成部分的方式来进行内存配置。不同进程需要设置的内存组成部分是不一样的。 详情请分别参考 TaskManager 和 JobManager 的相关文档。
提示 以上三种方式中,用户需要至少选择其中一种进行配置(本地运行除外),否则 Flink 将无法启动。 这意味着,用户需要从以下无默认值的配置参数(或参数组合)中选择一个给出明确的配置:
提示 不建议同时设置进程总内存和 Flink 总内存。 这可能会造成内存配置冲突,从而导致部署失败。 额外配置其他内存部分时,同样需要注意可能产生的配置冲突。
5.1.2. JVM 参数
Flink 进程启动时,会根据配置的和自动推导出的各内存部分大小,显式地设置以下 JVM 参数:
| JVM 参数 | TaskManager 取值 | JobManager 取值 |
|---|---|---|
| -Xmx 和 -Xms | 框架堆内存 + 任务堆内存 | JVM 堆内存 |
| -XX:MaxDirectMemorySize (TaskManager 始终设置,JobManager 见注释) | 框架堆外内存 + 任务堆外内存 + 网络内存 | 堆外内存 |
| -XX:MaxMetaspaceSize | JVM Metaspace | JVM Metaspace |
请记住,根据所使用的 GC 算法,你可能无法使用到全部堆内存。一些 GC 算法会为它们自身分配一定量的堆内存。这会导致堆的指标返回一个不同的最大值。
请注意,堆外内存也包括了用户代码使用的本地内存(非直接内存)。
只有在 jobmanager.memory.enable-jvm-direct-memory-limit 设置为 true 时,JobManager 才会设置 JVM 直接内存限制。
相关内存部分的配置方法,请同时参考 TaskManager 和 JobManager 的详细内存模型。
5.1.3. 受限的等比内存部分
本节介绍下列内存部分的配置方法,它们都可以通过指定在总内存中所占比例的方式进行配置,同时受限于相应的的最大/最小值范围。
- JVM 开销:可以配置占用进程总内存的固定比例
- 网络内存:可以配置占用 Flink 总内存的固定比例(仅针对 TaskManager)
相关内存部分的配置方法,请同时参考 TaskManager 和 JobManager 的详细内存模型。
这些内存部分的大小必须在相应的最大值、最小值范围内,否则 Flink 将无法启动。 最大值、最小值具有默认值,也可以通过相应的配置参数进行设置。 例如,如果仅配置下列参数:
- 进程总内存 = 1000Mb
- JVM 开销最小值 = 64Mb
- JVM 开销最大值 = 128Mb
- JVM 开销占比 = 0.1
那么 JVM 开销的实际大小将会是 1000Mb x 0.1 = 100Mb,在 64-128Mb 的范围内。
如果将最大值、最小值设置成相同大小,那相当于明确指定了该内存部分的大小。
如果没有明确指定内存部分的大小,Flink 会根据总内存和占比计算出该内存部分的大小。 计算得到的内存大小将受限于相应的最大值、最小值范围。 例如,如果仅配置下列参数:
- 进程总内存 = 1000Mb
- JVM 开销最小值 = 128Mb
- JVM 开销最大值 = 256Mb
- JVM 开销占比 = 0.1
那么 JVM 开销的实际大小将会是 128Mb,因为根据总内存和占比计算得到的内存大小 100Mb 小于最小值。
如果配置了总内存和其他内存部分的大小,那么 Flink 也有可能会忽略给定的占比。 这种情况下,受限的等比内存部分的实际大小是总内存减去其他所有内存部分后剩余的部分。 这样推导得出的内存大小必须符合最大值、最小值范围,否则 Flink 将无法启动。 例如,如果仅配置下列参数:
- 进程总内存 = 1000Mb
- 任务堆内存 = 100Mb(或 JobManager 的 JVM 堆内存)
- JVM 开销最小值 = 64Mb
- JVM 开销最大值 = 256Mb
- JVM 开销占比 = 0.1
进程总内存中所有其他内存部分均有默认大小,包括 TaskManager 的托管内存默认占比或 JobManager 的默认堆外内存。 因此,JVM 开销的实际大小不是根据占比算出的大小(1000Mb x 0.1 = 100Mb),而是进程总内存中剩余的部分。 这个剩余部分的大小必须在 64-256Mb 的范围内,否则将会启动失败。
5.2. 配置 TaskManager 内存
Flink 的 TaskManager 负责执行用户代码。 根据实际需求为 TaskManager 配置内存将有助于减少 Flink 的资源占用,增强作业运行的稳定性。
本文接下来介绍的内存配置方法适用于 1.10 及以上版本。 Flink 在 1.10 版本中对内存配置部分进行了较大幅度的改动,从早期版本升级的用户请参考升级指南。
提示 本篇内存配置文档仅针对 TaskManager! 与 JobManager 相比,TaskManager 具有相似但更加复杂的内存模型。
5.2.1. 配置总内存
Flink JVM 进程的*进程总内存(Total Process Memory)*包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。 其中,*Flink 总内存(Total Flink Memory)*包括 JVM 堆内存(Heap Memory)、*托管内存(Managed Memory)*以及其他直接内存(Direct Memory)或本地内存(Native Memory)。
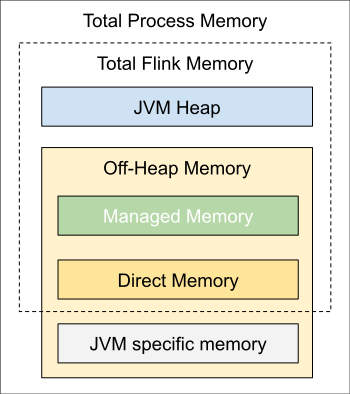
如果你是在本地运行 Flink(例如在 IDE 中)而非创建一个集群,那么本文介绍的配置并非所有都是适用的,详情请参考本地执行。
其他情况下,配置 Flink 内存最简单的方法就是配置总内存。 此外,Flink 也支持更细粒度的内存配置方式。
Flink 会根据默认值或其他配置参数自动调整剩余内存部分的大小。 接下来的章节将介绍关于各内存部分的更多细节。
5.2.2. 配置堆内存和托管内存
如配置总内存中所述,另一种配置 Flink 内存的方式是同时设置任务堆内存和托管内存。通过这种方式,用户可以更好地掌控用于 Flink 任务的 JVM 堆内存及 Flink 的托管内存大小。
Flink 会根据默认值或其他配置参数自动调整剩余内存部分的大小。关于各内存部分的更多细节,请参考相关文档。
提示 如果已经明确设置了任务堆内存和托管内存,建议不要再设置进程总内存或 Flink 总内存,否则可能会造成内存配置冲突。
5.2.2.1. 任务(算子)堆内存
如果希望确保指定大小的 JVM 堆内存给用户代码使用,可以明确指定任务堆内存(taskmanager.memory.task.heap.size)。 指定的内存将被包含在总的 JVM 堆空间中,专门用于 Flink 算子及用户代码的执行。
5.2.2.2. 托管内存
托管内存是由 Flink 负责分配和管理的本地(堆外)内存。 以下场景需要使用托管内存:
- 流处理作业中用于 RocksDB State Backend。
- 流处理和批处理作业中用于排序、哈希表及缓存中间结果。
- 流处理和批处理作业中用于在 Python 进程中执行用户自定义函数。
可以通过以下两种方式指定托管内存的大小:
- 通过
taskmanager.memory.managed.size明确指定其大小。 - 通过
taskmanager.memory.managed.fraction指定在Flink 总内存中的占比。
当同时指定二者时,会优先采用指定的大小(Size)。若二者均未指定,会根据默认占比进行计算。
请同时参考如何配置 State Backend 内存以及如何配置批处理作业内存。
5.2.2.2.1. 消费者权重
对于包含不同种类的托管内存消费者的作业,可以进一步控制托管内存如何在消费者之间分配。 通过 taskmanager.memory.managed.consumer-weights 可以为每一种类型的消费者指定一个权重,Flink 会按照权重的比例进行内存分配。 目前支持的消费者类型包括:
OPERATOR: 用于内置算法。STATE_BACKEND: 用于流处理中的 RocksDB State Backend。PYTHON:用户 Python 进程。
例如,一个流处理作业同时使用到了 RocksDB State Backend 和 Python UDF,消费者权重设置为 STATE_BACKEND:70,PYTHON:30,那么 Flink 会将 70% 的托管内存用于 RocksDB State Backend,30% 留给 Python 进程。
提示 只有作业中包含某种类型的消费者时,Flink 才会为该类型分配托管内存。 例如,一个流处理作业使用 Heap State Backend 和 Python UDF,消费者权重设置为 STATE_BACKEND:70,PYTHON:30,那么 Flink 会将全部托管内存用于 Python 进程,因为 Heap State Backend 不使用托管内存。
提示 对于未出现在消费者权重中的类型,Flink 将不会为其分配托管内存。如果缺失的类型是作业运行所必须的,则会引发内存分配失败。 默认情况下,消费者权重中包含了所有可能的消费者类型。上述问题仅可能出现在用户显式地配置了消费者权重的情况下。
5.2.3. 配置堆外内存
堆外内存指直接内存或本地内存。
用户代码中分配的堆外内存被归为任务堆外内存(Task Off-heap Memory),可以通过 taskmanager.memory.task.off-heap.size 指定。
提示 你也可以调整框架堆外内存(Framework Off-heap Memory)。 这是一个进阶配置,建议仅在确定 Flink 框架需要更多的内存时调整该配置。
Flink 将框架堆外内存和任务堆外内存都计算在 JVM 的直接内存限制中,请参考 JVM 参数。
提示 本地内存(非直接内存)也可以被归在框架堆外内存或任务堆外内存中,在这种情况下 JVM 的直接内存限制可能会高于实际需求。
提示 网络内存(Network Memory)同样被计算在 JVM 直接内存中。 Flink 会负责管理网络内存,保证其实际用量不会超过配置大小。 因此,调整网络内存的大小不会对其他堆外内存有实质上的影响。
请参考内存模型详解。
5.2.4. 内存模型详解
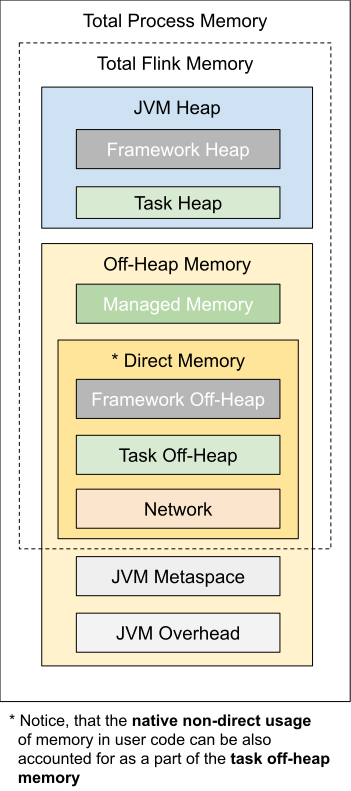
如上图所示,下表中列出了 Flink TaskManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| 框架堆内存(Framework Heap Memory) | taskmanager.memory.framework.heap.size | 用于 Flink 框架的 JVM 堆内存(进阶配置)。 |
| 任务堆内存(Task Heap Memory) | taskmanager.memory.task.heap.size | 用于 Flink 应用的算子及用户代码的 JVM 堆内存。 |
| 托管内存(Managed memory) | taskmanager.memory.managed.size taskmanager.memory.managed.fraction | 由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存。 |
| 框架堆外内存(Framework Off-heap Memory) | taskmanager.memory.framework.off-heap.size | 用于 Flink 框架的堆外内存(直接内存或本地内存)(进阶配置)。 |
| 任务堆外内存(Task Off-heap Memory) | taskmanager.memory.task.off-heap.size | 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存)。 |
| 网络内存(Network Memory) | taskmanager.memory.network.min taskmanager.memory.network.max taskmanager.memory.network.fraction | 用于任务之间数据传输的直接内存(例如网络传输缓冲)。该内存部分为基于 Flink 总内存的受限的等比内存部分。 |
| JVM Metaspace | taskmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM 开销 | taskmanager.memory.jvm-overhead.min taskmanager.memory.jvm-overhead.max taskmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
我们可以看到,有些内存部分的大小可以直接通过一个配置参数进行设置,有些则需要根据多个参数进行调整。
5.2.5. 框架内存
通常情况下,不建议对框架堆内存和框架堆外内存进行调整。 除非你非常肯定 Flink 的内部数据结构及操作需要更多的内存。这可能与具体的部署环境及作业结构有关,例如非常高的并行度。此外,Flink 的部分依赖(例如 Hadoop)在某些特定的情况下也可能会需要更多的直接内存或本地内存。
提示 不管是堆内存还是堆外内存,Flink 中的框架内存和任务内存之间目前是没有隔离的。对框架和任务内存的区分,主要是为了在后续版本中做进一步优化。
5.2.6. 本地执行
如果你是将 Flink 作为一个单独的 Java 程序运行在你的电脑本地而非创建一个集群(例如在 IDE 中),那么只有下列配置会生效,其他配置参数则不会起到任何效果:
| 组成部分 | 配置参数 | 本地执行时的默认值 |
|---|---|---|
| 任务堆内存 | taskmanager.memory.task.heap.size | 无穷大 |
| 任务堆外内存 | taskmanager.memory.task.off-heap.size | 无穷大 |
| 托管内存 | taskmanager.memory.managed.size | 128Mb |
| 网络内存 | taskmanager.memory.network.min taskmanager.memory.network.max | 64Mb |
本地执行模式下,上面列出的所有内存部分均可以但不是必须进行配置的。如果未配置,则会采用默认值。其中,任务堆内存和任务堆外内存的默认值无穷大(Long.MAX_VALUE 字节),以及托管内存的默认值 128Mb 均只针对本地执行模式。
提示 这种情况下,任务堆内存的大小与实际的堆空间大小无关。该配置参数可能与后续版本中的进一步优化相关。本地执行模式下,JVM 堆空间的实际大小不受 Flink 掌控,而是取决于本地执行进程是如何启动的。如果希望控制 JVM 的堆空间大小,可以在启动进程时明确地指定相关的 JVM 参数,即 -Xmx 和 -Xms。
5.3. 配置 JobManager 内存
JobManager 是 Flink 集群的控制单元。它由三种不同的组件组成:ResourceManager、Dispatcher 和每个正在运行作业的 JobMaster。本篇文档将介绍 JobManager 内存在整体上以及细粒度上的配置方法。
本文接下来介绍的内存配置方法适用于 1.11 及以上版本。 Flink 在 1.11 版本中对内存配置部分进行了较大幅度的改动,从早期版本升级的用户请参考升级指南。
提示 本篇内存配置文档仅针对 JobManager! 与 TaskManager 相比,JobManager 具有相似但更加简单的内存模型。
5.3.1. 配置总内存
配置 JobManager 内存最简单的方法就是进程的配置总内存。 本地执行模式下不需要为 JobManager 进行内存配置,配置参数将不会生效。
5.3.2. 详细配置
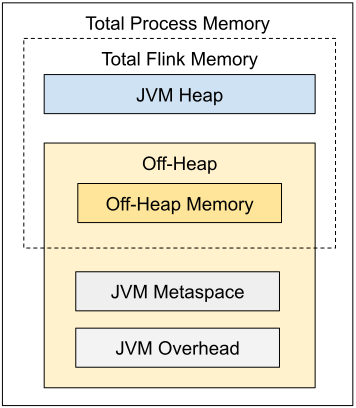
如上图所示,下表中列出了 Flink JobManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| JVM 堆内存 | jobmanager.memory.heap.size | JobManager 的 JVM 堆内存。 |
| 堆外内存 | jobmanager.memory.off-heap.size | JobManager 的堆外内存(直接内存或本地内存)。 |
| JVM Metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM 开销 | jobmanager.memory.jvm-overhead.min jobmanager.memory.jvm-overhead.max jobmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
5.3.2.1. 配置 JVM 堆内存
如配置总内存中所述,另一种配置 JobManager 内存的方式是明确指定 JVM 堆内存的大小(jobmanager.memory.heap.size)。通过这种方式,用户可以更好地掌控用于以下用途的 JVM 堆内存大小。
- Flink 框架
- 在作业提交时(例如一些特殊的批处理 Source)及 Checkpoint 完成的回调函数中执行的用户代码
Flink 需要多少 JVM 堆内存,很大程度上取决于运行的作业数量、作业的结构及上述用户代码的需求。
提示 如果已经明确设置了 JVM 堆内存,建议不要再设置进程总内存或 Flink 总内存,否则可能会造成内存配置冲突。
在启动 JobManager 进程时,Flink 启动脚本及客户端通过设置 JVM 参数 -Xms 和 -Xmx 来管理 JVM 堆空间的大小。请参考 JVM 参数。
5.3.2.2. 配置堆外内存
堆外内存包括 JVM 直接内存 和 本地内存。 可以通过配置参数 jobmanager.memory.enable-jvm-direct-memory-limit 设置是否启用 JVM 直接内存限制。 如果该配置项设置为 true,Flink 会根据配置的堆外内存大小设置 JVM 参数 -XX:MaxDirectMemorySize。请参考 JVM 参数。
可以通过配置参数 jobmanager.memory.off-heap.size 设置堆外内存的大小。如果遇到 JobManager 进程抛出 “OutOfMemoryError: Direct buffer memory” 的异常,可以尝试调大这项配置。请参考常见问题。
以下情况可能用到堆外内存:
- Flink 框架依赖(例如 Akka 的网络通信)
- 在作业提交时(例如一些特殊的批处理 Source)及 Checkpoint 完成的回调函数中执行的用户代码
提示 如果同时配置了 Flink 总内存和 JVM 堆内存,且没有配置堆外内存,那么堆外内存的大小将会是 Flink 总内存减去JVM 堆内存。 这种情况下,堆外内存的默认大小将不会生效。
5.3.3. 本地执行
如果你是在本地运行 Flink(例如在 IDE 中)而非创建一个集群,那么 JobManager 的内存配置将不会生效。
5.4. 内存调优指南
本文在基本的配置指南的基础上,介绍如何根据具体的使用场景调整内存配置,以及在不同使用场景下分别需要重点关注哪些配置参数。
5.4.1. 独立部署模式(Standalone)下的内存配置
独立部署模式下,我们通常更关注 Flink 应用本身使用的内存大小。 建议配置 Flink 总内存(taskmanager.memory.flink.size 或者 [jobmanager.memory.flink.size](//nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/deployment/config/#jobmanager-memory-flink-size" >}}))或其组成部分。此外,如果出现 Metaspace 不足的问题,可以调整 JVM Metaspace 的大小。
这种情况下通常无需配置进程总内存,因为不管是 Flink 还是部署环境都不会对 JVM 开销 进行限制,它只与机器的物理资源相关。
5.4.2. 容器(Container)的内存配置
在容器化部署模式(Containerized Deployment)下(Kubernetes、Yarn),建议配置进程总内存(taskmanager.memory.process.size 或者 jobmanager.memory.process.size)。该配置参数用于指定分配给 Flink JVM 进程的总内存,也就是需要申请的容器大小。
提示 如果配置了 Flink 总内存,Flink 会自动加上 JVM 相关的内存部分,根据推算出的进程总内存大小申请容器。
注意: 如果 Flink 或者用户代码分配超过容器大小的非托管的堆外(本地)内存,部署环境可能会杀掉超用内存的容器,造成作业执行失败。
请参考容器内存超用中的相关描述。
5.4.3. 状态后端的内存配置
本章节内容仅与 TaskManager 相关。
在部署 Flink 流处理应用时,可以根据 State Backend 的类型对集群的配置进行优化。
5.4.3.1. HashMap状态后端
执行无状态作业或者使用 HashMapStateBackend 时,建议将托管内存设置为 0。 这样能够最大化分配给 JVM 上用户代码的内存。
5.4.3.2. RocksDB状态后端
EmbeddedRocksDBStateBackend 使用本地内存。默认情况下,RocksDB 会限制其内存用量不超过用户配置的托管内存。因此,使用这种方式存储状态时,配置足够多的托管内存是十分重要的。如果你关闭了 RocksDB 的内存控制,那么在容器化部署模式下,如果 RocksDB 分配的内存超出了申请容器的大小(进程总内存),可能会造成 TaskExecutor 被部署环境杀掉。请同时参考如何调整 RocksDB 内存以及 state.backend.rocksdb.memory.managed。
5.4.4. 批处理作业的内存配置
Flink 批处理算子使用托管内存来提高处理效率。算子运行时,部分操作可以直接在原始数据上进行,而无需将数据反序列化成 Java 对象。这意味着托管内存对应用的性能具有实质上的影响。因此 Flink 会在不超过其配置限额的前提下,尽可能分配更多的托管内存。Flink 明确知道可以使用的内存大小,因此可以有效避免 OutOfMemoryError 的发生。当托管内存不足时,Flink 会优雅地将数据落盘。
5.5. 常见问题
5.5.1. IllegalConfigurationException
如果遇到从 TaskExecutorProcessUtils 或 JobManagerProcessUtils 抛出的 IllegalConfigurationException 异常,这通常说明您的配置参数中存在无效值(例如内存大小为负数、占比大于 1 等)或者配置冲突。请根据异常信息,确认出错的内存部分的相关文档及配置信息。
5.5.2. OutOfMemoryError: Java heap space
该异常说明 JVM 的堆空间过小。可以通过增大总内存、TaskManager 的任务堆内存、JobManager 的 JVM 堆内存等方法来增大 JVM 堆空间。
提示 也可以增大 TaskManager 的框架堆内存。 这是一个进阶配置,只有在确认是 Flink 框架自身需要更多内存时才应该去调整。
5.5.3. OutOfMemoryError: Direct buffer memory
该异常通常说明 JVM 的直接内存限制过小,或者存在直接内存泄漏(Direct Memory Leak)。 请确认用户代码及外部依赖中是否使用了 JVM 直接内存,以及如果使用了直接内存,是否配置了足够的内存空间。可以通过调整堆外内存来增大直接内存限制。有关堆外内存的配置方法,请参考 TaskManager、JobManager 以及 JVM 参数的相关文档。
5.5.4. OutOfMemoryError: Metaspace
该异常说明 JVM Metaspace 限制过小。 可以尝试调整 TaskManager、JobManager 的 JVM Metaspace。
5.5.5. IOException: Insufficient number of network buffers
该异常仅与 TaskManager 相关。
该异常通常说明网络内存过小。 可以通过调整以下配置参数增大网络内存:
5.5.6. 容器(Container)内存超用
如果 Flink 容器尝试分配超过其申请大小的内存(Yarn、Mesos 或 Kubernetes),这通常说明 Flink 没有预留出足够的本地内存。可以通过外部监控系统或者容器被部署环境杀掉时的错误信息判断是否存在容器内存超用。
对于 JobManager 进程,你还可以尝试启用 JVM 直接内存限制(jobmanager.memory.enable-jvm-direct-memory-limit),以排除 JVM 直接内存泄漏的可能性。
如果使用了 RocksDBStateBackend :
- 禁用了内存控制:你可以尝试增加 TaskManager 的 managed memory。
- 启用了内存控制,并且增加了全量 checkpoint 或 savepoint 期间的对外内存:内存超用可能会由于
glibc内存收集器而出现,具体请查看 glibc bug 。你可以尝试给 TaskManager 增加环境变量MALLOC_ARENA_MAX=1。
此外,还可以尝试增大 JVM 开销。
请参考如何配置容器内存。
5.6. 升级指南
在 1.10 和 1.11 版本中,Flink 分别对 TaskManager 和 JobManager 的内存配置方法做出了较大的改变。部分配置参数被移除了,或是语义上发生了变化。本篇升级指南将介绍如何将 Flink 1.9 及以前版本的 TaskManager 内存配置升级到 Flink 1.10 及以后版本, 以及如何将 Flink 1.10 及以前版本的 JobManager 内存配置升级到 Flink 1.11 及以后版本。
注意: 请仔细阅读本篇升级指南。使用原本的和新的内存配制方法可能会使内存组成部分具有截然不同的大小。未经调整直接沿用 Flink 1.10 以前版本的 TaskManager 配置文件或 Flink 1.11 以前版本的 JobManager 配置文件,可能导致应用的行为、性能发生变化,甚至造成应用执行失败。
提示 在 1.10/1.11 版本之前,Flink 不要求用户一定要配置 TaskManager/JobManager 内存相关的参数,因为这些参数都具有默认值。新的内存配置要求用户至少指定下列配置参数(或参数组合)的其中之一,否则 Flink 将无法启动。
Flink 自带的默认 flink-conf.yaml 文件指定了 taskmanager.memory.process.size(>= 1.10)和 jobmanager.memory.process.size (>= 1.11),以便与此前的行为保持一致。
可以使用这张电子表格来估算和比较原本的和新的内存配置下的计算结果。
5.6.1. 升级 TaskManager 内存配置
5.6.1.1. 配置参数变化
本节简要列出了 Flink 1.10 引入的配置参数变化,并援引其他章节中关于如何升级到新配置参数的相关描述。
下列配置参数已被彻底移除,配置它们将不会产生任何效果。
| 移除的配置参数 | 备注 |
|---|---|
| taskmanager.memory.fraction | 请参考新配置参数 taskmanager-memory-managed-fraction 的相关描述。新的配置参数与被移除的配置参数在语义上有所差别,因此其配置值通常也需要做出适当调整。 请参考如何升级托管内存。 |
| taskmanager.memory.off-heap | Flink 不再支持堆上的(On-Heap)托管内存。请参考如何升级托管内存。 |
| taskmanager.memory.preallocate | Flink 不再支持内存预分配,今后托管内存将都是惰性分配的。请参考如何升级托管内存。 |
下列配置参数将被弃用,出于向后兼容性考虑,配置它们将被解读成对应的新配置参数。
| 弃用的配置参数 | 对应的新配置参数 |
|---|---|
| taskmanager.heap.size | 独立部署模式(Standalone Deployment)下:taskmanager-memory-flink-size 容器化部署模式(Containerized Deployement)下:taskmanager.memory.process.size 请参考如何升级总内存。 |
| taskmanager.memory.size | taskmanager-memory-managed-size。请参考如何升级托管内存。 |
| taskmanager.network.memory.min | taskmanager-memory-network-min |
| taskmanager.network.memory.max | taskmanager-memory-network-max |
| taskmanager.network.memory.fraction | taskmanager-memory-network-fraction |
尽管网络内存的配置参数没有发生太多变化,我们仍建议您检查其配置结果。网络内存的大小可能会受到其他内存部分大小变化的影响,例如总内存变化时,根据占比计算出的网络内存也可能发生变化。请参考内存模型详解。
容器切除(Cut-Off)内存相关的配置参数(containerized.heap-cutoff-ratio 和 containerized.heap-cutoff-min)将不再对 TaskManager 进程生效。请参考如何升级容器切除内存。
5.6.1.2. 总内存(原堆内存)
在原本的内存配置方法中,用于指定用于 Flink 的总内存的配置参数是 taskmanager.heap.size 或 taskmanager.heap.mb。尽管这两个参数以“堆(Heap)”命名,实际上它们指定的内存既包含了 JVM 堆内存,也包含了其他堆外内存部分。这两个配置参数目前已被弃用。
Flink 在 Mesos 上还有另一个具有同样语义的配置参数 mesos.resourcemanager.tasks.mem,目前也已经被弃用。
如果配置了上述弃用的参数,同时又没有配置与之对应的新配置参数,那它们将按如下规则对应到新的配置参数。
- 独立部署模式(Standalone Deployment)下:Flink 总内存(
taskmanager.memory.flink.size) - 容器化部署模式(Containerized Deployement)下(Yarn、Mesos):进程总内存(
taskmanager.memory.process.size)
建议您尽早使用新的配置参数取代启用的配置参数,它们在今后的版本中可能会被彻底移除。
请参考如何配置总内存.
5.6.1.3. JVM 堆内存
此前,JVM 堆空间由托管内存(仅在配置为堆上时)及 Flink 用到的所有其他堆内存组成。这里的其他堆内存是由总内存减去所有其他非堆内存得到的。请参考如何升级托管内存。
现在,如果仅配置了Flink总内存或进程总内存,JVM 的堆空间依然是根据总内存减去所有其他非堆内存得到的。请参考如何配置总内存。
此外,你现在可以更直接地控制用于任务和算子的 JVM 的堆内存(taskmanager.memory.task.heap.size),详见任务堆内存。如果流处理作业选择使用 Heap State Backend(MemoryStateBackend 或 FsStateBackend),那么它同样需要使用 JVM 堆内存。
Flink 现在总是会预留一部分 JVM 堆内存供框架使用(taskmanager.memory.framework.heap.size)。请参考框架内存。
5.6.1.4. 托管内存
请参考如何配置托管内存。
5.6.1.4.1. 明确的大小
原本用于指定明确的托管内存大小的配置参数(taskmanager.memory.size)已被弃用,与它具有相同语义的新配置参数为 taskmanager.memory.managed.size。 建议使用新的配置参数,原本的配置参数在今后的版本中可能会被彻底移除。
5.6.1.4.2. 占比
此前,如果不指定明确的大小,也可以将托管内存配置为占用总内存减去网络内存和容器切除内存(仅在 Yarn 和 Mesos 上)之后剩余部分的固定比例(taskmanager.memory.fraction)。 该配置参数已经被彻底移除,配置它不会产生任何效果。请使用新的配置参数 taskmanager.memory.managed.fraction。在未通过 taskmanager.memory.managed.size 指定明确大小的情况下,新的配置参数将指定托管内存在 Flink 总内存中的所占比例。
5.6.1.4.3. RocksDB状态后端
流处理作业如果选择使用 RocksDBStateBackend,它使用的本地内存现在也被归为托管内存。默认情况下,RocksDB 将限制其内存用量不超过托管内存大小,以避免在 Yarn 或 Mesos 上容器被杀。你也可以通过设置 state.backend.rocksdb.memory.managed 来关闭 RocksDB 的内存控制。请参考如何升级容器切除内存。
5.6.1.4.4. 其他变化
此外,Flink 1.10 对托管内存还引入了下列变化:
- 托管内存现在总是在堆外。配置参数
taskmanager.memory.off-heap已被彻底移除,配置它不会产生任何效果。 - 托管内存现在使用本地内存而非直接内存。这意味着托管内存将不在 JVM 直接内存限制的范围内。
- 托管内存现在总是惰性分配的。配置参数
taskmanager.memory.preallocate已被彻底移除,配置它不会产生任何效果。
5.6.2. 升级 JobManager 内存配置
在原本的内存配置方法中,用于指定 JVM 堆内存 的配置参数是:
jobmanager.heap.sizejobmanager.heap.mb
尽管这两个参数以“堆(Heap)”命名,在此之前它们实际上只有在独立部署模式才完全对应于 JVM 堆内存。在容器化部署模式下(Kubernetes 和 Yarn),它们指定的内存还包含了其他堆外内存部分。JVM 堆空间的实际大小,是参数指定的大小减去容器切除(Cut-Off)内存后剩余的部分。 容器切除内存在 1.11 及以上版本中已被彻底移除。
上述两个参数此前对 Mesos 部署模式并不生效。 Flink 在 Mesos 上启动 JobManager 进程时并未设置任何 JVM 内存参数。从 1.11 版本开始,Flink 将采用与独立部署模式相同的方式设置这些参数。
这两个配置参数目前已被弃用。如果配置了上述弃用的参数,同时又没有配置与之对应的新配置参数,那它们将按如下规则对应到新的配置参数。
- 独立部署模式(Standalone Deployment)、Mesos 部署模式下:JVM 堆内存(
jobmanager.memory.heap.size) - 容器化部署模式(Containerized Deployement)下(Kubernetes、Yarn):进程总内存(
jobmanager.memory.process.size)
建议您尽早使用新的配置参数取代启用的配置参数,它们在今后的版本中可能会被彻底移除。
如果仅配置了 Flink 总内存或进程总内存,那么 JVM 堆内存将是总内存减去其他内存部分后剩余的部分。请参考如何配置总内存。 此外,也可以通过配置 jobmanager.memory.heap.size 的方式直接指定 JVM 堆内存。
5.6.3. Flink JVM 进程内存限制
从 1.10 版本开始,Flink 通过设置相应的 JVM 参数,对 TaskManager 进程使用的 JVM Metaspace 和 JVM 直接内存进行限制。从 1.11 版本开始,Flink 同样对 JobManager 进程使用的 JVM Metaspace 进行限制。此外,还可以通过设置 jobmanager.memory.enable-jvm-direct-memory-limit 对 JobManager 进程的 JVM 直接内存进行限制。请参考 JVM 参数。
Flink 通过设置上述 JVM 内存限制降低内存泄漏问题的排查难度,以避免出现容器内存溢出等问题。请参考常见问题中关于 JVM Metaspace 和 JVM 直接内存 OutOfMemoryError 异常的描述。
5.6.4. 容器切除(Cut-Off)内存
在容器化部署模式(Containerized Deployment)下,此前你可以指定切除内存。这部分内存将预留给所有未被 Flink 计算在内的内存开销。其主要来源是不受 Flink 直接管理的依赖使用的内存,例如 RocksDB、JVM 内部开销等。相应的配置参数(containerized.heap-cutoff-ratio 和 containerized.heap-cutoff-min)不再生效。新的内存配置方法引入了新的内存组成部分来具体描述这些内存用量。
5.6.4.1. TaskManager
流处理作业如果使用了 RocksDBStateBackend,RocksDB 使用的本地内存现在将被归为托管内存。默认情况下,RocksDB 将限制其内存用量不超过托管内存大小。请同时参考如何升级托管内存以及如何配置托管内存。
其他堆外(直接或本地)内存开销,现在可以通过下列配置参数进行设置:
- 任务堆外内存(
taskmanager.memory.task.off-heap.size) - 框架堆外内存(
taskmanager.memory.framework.off-heap.size) - JVM Metaspace(
taskmanager.memory.jvm-metaspace.size) - JVM 开销
5.6.4.2. JobManager
可以通过下列配置参数设置堆外(直接或本地)内存开销:
- 堆外内存 (
jobmanager.memory.off-heap.size) - JVM Metaspace (
jobmanager.memory.jvm-metaspace.size) - JVM 开销
5.6.5. flink-conf.yaml 中的默认配置
本节描述 Flink 自带的默认 flink-conf.yaml 文件中的变化。
原本的 TaskManager 总内存(taskmanager.heap.size)被新的配置项 taskmanager.memory.process.size 所取代。默认值从 1024Mb 增加到了 1728Mb。
原本的 JobManager 总内存(jobmanager.heap.size)被新的配置项 jobmanager.memory.process.size 所取代。默认值从 1024Mb 增加到了 1600Mb。
请参考如何配置总内存。
**注意:**使用新的默认 flink-conf.yaml 可能会造成各内存部分的大小发生变化,从而产生性能变化。
6. 命令行接口
Flink 提供了一个命令行接口(CLI)来运行打包为 JAR 文件的程序,并且控制他们的执行。CLI 是 Flink 部署的一部分,在本地单节点部署和分布式部署中均可用。他会连接在 conf/flink-config.yaml 中指定的运行的 JobManager。
6.1. 作业生命周期管理
该章节中列出的命令工作的先决条件是有一个正在运行的 Flink 部署,比如 Kubernetes、YARN 或任何其他可用的部署。可以在你自己的机器上启动 Flink 本地集群来尝试这些命令。
6.1.1. 提交一个作业
提交一个作业意味着上传作业的 JAR 和相关的依赖到 Flink 集群,并且初始化作业执行。在这个案例中,我们选择了一个长时间运行的作业,比如:examples/streaming/StateMachineExample.jar。可以选择 examples/ 目录下的其他任何 JAR 归档文件或部署自己的作业来体验。
$ ./bin/flink run \
--detached \
./examples/streaming/StateMachineExample.jar
提交作业时使用 --detached 将会使作业提交完成后命令马上返回,命令行返回的输出包括新提交作业的 ID。
Usage with built-in data generator: StateMachineExample [--error-rate <probability-of-invalid-transition>] [--sleep <sleep-per-record-in-ms>]
Usage with Kafka: StateMachineExample --kafka-topic <topic> [--brokers <brokers>]
Options for both the above setups:
[--backend <file|rocks>]
[--checkpoint-dir <filepath>]
[--async-checkpoints <true|false>]
[--incremental-checkpoints <true|false>]
[--output <filepath> OR null for stdout]
Using standalone source with error rate 0.000000 and sleep delay 1 millis
Job has been submitted with JobID cca7bc1061d61cf15238e92312c2fc20
如果需要的话,可以在作业提交命令行后面增加上面打印出的作业相关参数。处于可读性目的,我们假设返回的 JobID 被存储为命令的变量 JOB_ID :
$ export JOB_ID="cca7bc1061d61cf15238e92312c2fc20"
有一个名为 run-application 的操作可用于在 Application 模式下运行作业,本文章不单独描述该操作,因为他和 CLI 的 run 操作的工作原理相似。
run 和 run-application 支持通过 -D 配置额外的配置参数,比如通过 -Dpipeline.max-parallelism=120 来设置作业的最大并行度。该参数对于配置 per-job 或 applicatgion 模式集群非常有用,因为你可以给集群传递任何配置参数,而不修改配置文件。
当提交作业到已存在的 session 集群时,只支持执行配置参数。
6.1.2. 作业监控
你可以使用 list 操作监控任何运行的作业:
$ ./bin/flink list
Waiting for response...
------------------ Running/Restarting Jobs -------------------
30.11.2020 16:02:29 : cca7bc1061d61cf15238e92312c2fc20 : State machine job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
已经被提交但还没有开始运行的作业,将会在“Scheduled Jobs”下列出。
6.1.3. 创建Savepoint
可以创建 Savepoints 来保存作业的当前状态,命令中只需要作业的 JobID:
$ ./bin/flink savepoint \
$JOB_ID \
/tmp/flink-savepoints
Triggering savepoint for job cca7bc1061d61cf15238e92312c2fc20.
Waiting for response...
Savepoint completed. Path: file:/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab
You can resume your program from this savepoint with the run command.
savepoint 目录是可选的,如果没有设置 state.savepoints.dir,则需要指定 savepoint 目录。
savepoint 的目录可以在之后重启 Flink 作业时使用。
6.1.3.1. 清理Savepoint
savepoint 操作也可以被用于移除 savepoint。--dispose 需要指定相对应的 savepoint 路径:
$ ./bin/flink savepoint \
--dispose \
/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab \
$JOB_ID
Disposing savepoint '/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab'.
Waiting for response...
Savepoint '/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab' disposed.
如果你使用了自定义的状态实例,比如自定义状态或 RocksDB 状态,你需要指定触发 savepoint 对应程序的 JAR 路径,否则会报 ClassNotFoundException:
$ ./bin/flink savepoint \
--dispose <savepointPath> \
--jarfile <jarFile>
通过 savepoint 操作触发 savepoint 清理不仅会从存储中移除数据,并且会让 Flink 清除 savepoint 相关的元数据。
6.1.4. 终止作业
6.1.4.1. 创建Savepoint并优雅地停止作业
另一个停止作业的操作为 stop,这是一个从 source 到 sink 停止正在运行作业更优雅的方式。当用户要停止作业时,会要求所有的 source 发送最新的 checkpoint barrier,并触发 savepoint,在完成 savepoint 后,会通过调用他们的 cancel() 方法完成停止操作。
$ ./bin/flink stop \
--savepointPath /tmp-flink-savepoints \
$JOB_ID
Suspending job "cca7bc1061d61cf15238e92312c2fc20" with a savepoint.
Savepoint completed. Path: file:/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab
如果没有配置 state.savepoints.dir,则需要通过 --savepointPath 来指定 savepoint 目录。
如果指定了 --drain 配置,将会在最新 checkpoint barrier 之前发射 MAX_WATERMARK,这会导致所有被注册的事件时间定时器触发,然后清除正在等待指定水印的任何状态,比如窗口。作业会一直保持运行,直到所有的 source 完全停止,该行为会让作业处理完所有正在传输的数据。
如果你想永久的停止作业,可以使用
--drain配置。如果以后你想恢复作业,就不要 drain pipeline 了,因为这会导致作业恢复时产生错误的结果。
6.1.4.2. 不优雅的取消作业
可以通过 cancel 操作来取消作业:
$ ./bin/flink cancel $JOB_ID
Cancelling job cca7bc1061d61cf15238e92312c2fc20.
Cancelled job cca7bc1061d61cf15238e92312c2fc20.
对应的作业状态将会从 running 变成 cancelled ,所有的计算都会停止。
--withSavepoint配置允许创建一个 savepoing 为作业取消的一部分,该特性已经过时,请使用 stop 操作来代替。
6.1.5. 从Savepoint启动作业
可以通过 run 和 run-application 操作从 savepoint 启动一个作业。
$ ./bin/flink run \
--detached \
--fromSavepoint /tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab \
./examples/streaming/StateMachineExample.jar
Usage with built-in data generator: StateMachineExample [--error-rate <probability-of-invalid-transition>] [--sleep <sleep-per-record-in-ms>]
Usage with Kafka: StateMachineExample --kafka-topic <topic> [--brokers <brokers>]
Options for both the above setups:
[--backend <file|rocks>]
[--checkpoint-dir <filepath>]
[--async-checkpoints <true|false>]
[--incremental-checkpoints <true|false>]
[--output <filepath> OR null for stdout]
Using standalone source with error rate 0.000000 and sleep delay 1 millis
Job has been submitted with JobID 97b20a0a8ffd5c1d656328b0cd6436a6
该命令和初始 run 命令是一样的,但是额外指定了 --fromSavepoint 参数,该参数用来指定要从哪个之前停止的作业状态进行恢复。之后会生成一个新的 JobID 来维护新的作业。
默认情况下,我们会尝试匹配整个 savepoint 状态到提交的作业,如果你想允许新作业跳过无法从 savepoint 状态恢复的算子,可以使用 --allowNonRestoredState 配置。在你移除了程序中一个算子之后,你还想使用之前触发的 savepoint 来恢复作业时,你需要指定该配置。
$ ./bin/flink run \
--fromSavepoint <savepointPath> \
--allowNonRestoredState ...
如果你的程序删除了属于 savepoint 一部分的某个算子时,这是非常有用的。
6.2. CLI操作
下面是 Flink CLI 工具支持的操作:
| 操作 | 作用 |
|---|---|
run | 该操作用来执行作业,他要求 jar 文件包含作业,可以通过它来传递 flink 或作业相关的参数。 |
run-application | 该操作会使用 Application Mode 执行作业,除此之外,他要求和 run 操作相同的参数。 |
info | 该操作可以被用来打印作业优化之后的执行图,同样要求 jar 包含作业。 |
list | 该操作会列出所有正在运行或被调度的作业。 |
savepoint | 该操作可以被用来根据给定的作业来创建或清除 savepoint,如果没有在 conf/flink-config.yaml 文件中指定 state.savepoints.dir 参数,该操作会要求除了 JobID 外还要指定一个 savepoint 目录。 |
cancel | 该操作会基于指定的 JobID 来取消正在运行的作业。 |
stop | 该操作合并了 cancel 和 savepoint 操作来停止正在运行的作业,并且会创建一个可以被用来重新启动的 savepoint。 |
可以通过 bin/flink --help 或bin/flink <action> --help 命令来获取所有操以及他们的参数更加详细的描述。
6.3. 高级CLI
6.3.1. REST API
也可以通过 REST API 来管理 Flink 集群,前面章节中的命令描述是 Flink REST 终端的一部分,因此,可以使用类似 curl 之类的工具从 Flink 中获取更多信息。
6.3.2. Selecting Deployment Targets
Flink 兼容很多集群管理框架,比如 Kubernetes 或 YARN ,作业可以通过不同的 部署模式 提交,基于下面提到的框架和部署模式,作业的提交参数是不同的。
bin/flink 脚本提供了 --target 参数来处理不同的选项,除此之外,作业提交还必须使用 run (for Session and Per-Job 模式) or run-application (for Application 模式)。查看下面的参数组合总结:
- YARN
./bin/flink run --target yarn-session:提交作业到已经在 YARN 集群上运行的 Flink session 集群./bin/flink run --target yarn-per-job:使用 Per-job 模式提交作业到 YARN 上./bin/flink run-application --target yarn-application:使用 application 模式提交作业到 YARN 上
- Kubernetes
./bin/flink run --target kubernetes-session:提交作业到已经在 Kubernetes 集群上运行的 Flink session 集群./bin/flink run-application --target kubernetes-application:使用 application 模式提交作业到 kubernetes 上
- Mesos
./bin/flink run --target remote:提交作业到已经在 Mesos 集群上运行的 Flink 集群
- Standalone:
./bin/flink run --target local:使用 session 模式提交作业到本地 MiniCluster./bin/flink run --target remote:提交作业到一个已经在运行的 Flink 集群
--target 选项会覆盖在 config/flink-config.yaml 中指定的 execution.target 。
更多关于命令和可用选项的细节,请参考“资源提供者”章节。
6.3.3. 提交PyFlink作业
目前,用户可以通过 CLI 来提交 PyFlink 作业,和 java 作业提交不同,该方式不要求指定 JAR 文件路径或主类完全限定名。
通过
flink run提交 Python 作业时,Flink 会运行python命令,请运行下面的命令来确认当前环境中的 python 版本为 3.6+。
$ python --version
# 打印的 python 版本必须是 3.6+
下面的命令展示不同的 PyFlink 作业提交用例:
- 运行 PyFlink 作业:
$ ./bin/flink run --python examples/python/table/batch/word_count.py
- 使用额外的源头和资源文件来运行 PyFlink 作业,通过
--pyFiles指定的文件将会被添加到PYTHONPATH,之后就可以在 Python 代码中使用对应的文件了。
$ ./bin/flink run \
--python examples/python/table/batch/word_count.py \
--pyFiles file:///user.txt,hdfs:///$namenode_address/username.txt
- 运行的 PyFlink 作业将会引用 Java UDF 或其他的连接器,通过
--jarfile指定的 JAR 文件将会被上传到集群。
$ ./bin/flink run \
--python examples/python/table/batch/word_count.py \
--jarfile <jarFile>
- 使用指定 pyFiles 和通过
--pyModule指定的模块运行 PyFlink 作业:
$ ./bin/flink run \
--pyModule batch.word_count \
--pyFiles examples/python/table/batch
- 提交 PyFlink 作业到指定的
<jobmanagerHost>主机上运行的 JobManager:
$ ./bin/flink run \
--jobmanager <jobmanagerHost>:8081 \
--python examples/python/table/batch/word_count.py
- 使用 YARN cluster in Per-Job Mode 运行 PyFlink 作业:
$ ./bin/flink run \
--target yarn-per-job
--python examples/python/table/batch/word_count.py
- 使用指定的集群 ID
<ClusterId>在原生 Kubernetes 集群上运行 PyFlink 程序,要求安装 PyFlink 的 docker 镜像,请参考 在 docker 中启用 PyFlink。
$ ./bin/flink run-application \
--target kubernetes-application \
--parallelism 8 \
-Dkubernetes.cluster-id=<ClusterId> \
-Dtaskmanager.memory.process.size=4096m \
-Dkubernetes.taskmanager.cpu=2 \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dkubernetes.container.image=<PyFlinkImageName> \
--pyModule word_count \
--pyFiles /opt/flink/examples/python/table/batch/word_count.py
更多可用选项,请参考 Kubernetes 或 YARN,他们描述了更多的细节。
除了上面提到的 --pyFiles、 --pyModule 和 --python 选项之外,还有一些和 Python 相关的选项。下面 Flink CLI 工具支持的 Python 的 run 和 run-application 操作相关的选项:
| 选项 | 描述 |
|---|---|
-py,--python | 程序入口对应的 Python 脚本文件。可以使用 --pyFiles 选项配置依赖的资源。 |
-pym,--pyModule | 程序入口对应的 Python 模块。该选项必须和 --pyFiles 组合使用。 |
-pyfs,--pyFiles | 给作业附加自定义文件。支持标准的资源文件后缀,比如:.py/.egg/.zip/.whl,也支持目录。这些文件将会被添加到本地客户端和远程 python UDF 工作节点的 PYTHONPATH。以 .zip 为后缀的文件将会被提取出来并添加到 PYTHONPATH。符号“英文逗号”可以被用于多个文件之间的分隔符,比如:–pyFiles file:///tmp/myresource.zip,hdfs:///$namenode_address/myresource2.zip。 |
-pyarch,--pyArchives | 给作业添加归档文件。归档文件会被提取到 python UDF 工作节点的工作目录中。目前只支持 zip 格式。对于每个归档文件,都需要指定目标目录。如果指定了目标目录名称,归档文件将会被提取导指定的目录中。否则,归档文件将会被提取导同一个目录中。通过该选项上传的文件可以通过相对目录进行访问。‘#’ 可以用于归档文件路径和目标目录名称的分隔符号。符号“英文逗号”可以被用于多个归档文件的分隔符号。该选项可以被用于上传虚拟环境,即 Python UDF 中使用的数据文件,比如:–pyArchives file:///tmp/py37.zip,file:///tmp/data.zip#data --pyExecutable py37.zip/py37/bin/python。数据文件可以通过 Python UDF 访问,比如:f = open(‘data/data.txt’, ‘r’)。 |
-pyexec,--pyExecutable | 指定用于执行 Python UDF 工作节点的 python 解释器路径,比如:–pyExecutable /usr/local/bin/python3。python UDF 工作依赖于 Python 3.6+,Apache Beam(version == 2.27.0), Pip (version >= 7.1.0) 和 SetupTools (version >= 37.0.0)。请确保指定的环境满足上面的要求。 |
-pyreq,--pyRequirements | 指定定义第三方依赖的 requirements.txt 文件。这些依赖将会被安装并添加到 python UDF 工作节点的 PYTHONPATH。指定包含这些依赖的安装包目录是可选操作。如果可选的参数已经存在,可以使用 ‘#’ 作为分隔符号,比如:–pyRequirements file:///tmp/requirements.txt#file:///tmp/cached_dir。 |
除了提交作业的命令行选项,也支持通过配置或代码中的 python API 来指定依赖。请参考依赖管理来获取更多细节。
7. 弹性伸缩
Apache Flink 允许你弹性伸缩你的作业。你可以手动停止你的作业,然后配置不同的并行度,并且使用之前停止作业时创建的 savepoint 来重新启动你的作业。
该章节描述 Flink 自动调整并行度的相关选项配置。
7.1. 响应式模式
响应式模式是一个 MVP(minimum viable product)特性。Flink 社区会积极的查找用户通过邮箱发送的反馈。请参考该章节中的限制列表。
响应式模式会配置作业,以让作业使用集群所有可用的资源。增加一个 TaskManager 将会提升作业性能,移除资源将会降低作业性能。Flink 会管理作业的并行度,通常设置并行度为最大可能的值。
响应式模式会在遇到调整事件时使用最新完成的 checkpoint 重启作业。这意味着不需要花费创建 savepoint 的开销,savepoint 通常被用于手动调整作业。同时,调整后需要处理的数据数量取决于 checkpoint 间隔,恢复时间取决于状态大小。
响应式模式通过服务监控指标,比如消费延迟,平均 CPU 使用率,吞吐量或延迟,允许 Flink 用户实现更强大的自动伸缩机制。只要这些指标高于或低于某个确定的阈值,就可以增加额外的 TaskManager 或从 Flink 集群中移除 TaskManager。可以通过改变 Kubernetges 部署的 replica factor ,或 AWS 的 autoscaling group 来实现。外部服务只需要处理资源收集和释放。Flink 只关心保持作业运行的可用资源。
7.1.1. 入门指南
如果你只想尝试我们的响应式模式,请参考下面的说明。他们假设你在单个机器上部署 Flink。
# 这些说明假设你在 Flink 分布式部署的根目录下
# 将作业 jar 包放到 lib/ 目录下
cp ./examples/streaming/TopSpeedWindowing.jar lib/
# 使用响应模式提交作业
./bin/standalone-job.sh start -Dscheduler-mode=reactive -Dexecution.checkpointing.interval="10s" -j org.apache.flink.streaming.examples.windowing.TopSpeedWindowing
# 启动第一个 TaskManager
./bin/taskmanager.sh start
让我们快速检查一下使用的提交命令:
./bin/standalone-job.sh start:使用 Application Mode 部署 Flink。-Dscheduler-mode=reactive:启用响应式模式。-Dexecution.checkpointing.interval="10s":配置 checkpoint。- 最后的参数用来指定作业的主类名。
现在你已经通过响应式模式启动了一个 Flink 作业。 web interface 展示了作业正在一个 TaskManager 上运行。如果你想扩展作业资源,给集群简单的增加一个其他的 TaskManager 即可:
# 启动一个额外的 TaskManager
./bin/taskmanager.sh start
移除一个 TaskManager 实例:
# 移除一个 TaskManager
./bin/taskmanager.sh stop
7.1.2. 使用
7.1.2.1. 配置
为了启用响应式模式,你需要配置 scheduler-mode 为 reactive。
调度器会决定单个算子的并行度,他是不可配置的,通过单独指定单个算子或整个作业的并行度配置将会被忽略。
影响并行度的唯一方式是设置算子的最大并行度,这会被调度器认可。最大并行度上线是 2^15(32768)。如果没有对单个算子或整个作业设置最大并行度,将会采用默认并行度规则,可能会接受下限而不是最大的可能值。使用默认的调度模式,请参考并行度最佳实践。
注意,一个较高的最大并行度值设置,可能会影响作业的性能,因为保持 Flink 一些内部结构需要更多的资源。
当启用响应式模式时,jobmanager.adaptive-scheduler.resource-wait-timeout 配置将会被默认设置为 -1,这意味着 JobManager 将会永远运行,等待足够的资源。如果你希望 JobManager 在等待有足够的 TaskManager 来运行作业时有一个确定的超时时间以停止 JobManager,请配置 jobmanager.adaptive-scheduler.resource-wait-timeout.
启用响应式模式后,jobmanager.adaptive-scheduler.resource-stabilization-timeout 配置将会被默认设置为 0:一旦有足够的可用资源,Flink 将会开始运行作业。如果所有的 TaskManager 没有同时连接,而是一个接着一个缓慢的连接,每次连接上一个 TaskManager,都会导致作业重启。如果你想在调度作业之前等待资源稳定,则可以增加该配置值。
另外,还有配置 jobmanager.adaptive-scheduler.min-parallelism-increase:该配置选项指定在触发资源扩展之前的聚合算子并行度增加的最小值。比如,你的作业配置为:source 并行度为 2,sink 并行度为 2,聚合算子并行度为 4,默认情况下,该配置值为 1,因此增加聚合算子并行度将会触发重启。
7.1.2.2. 建议
-
给有状态作业配置周期性 checkpoint:响应式模式会在遇到调整事件后从最新完成的 checkpoint 重启作业。如果没有启用周期性的 checkpoint,程序将会丢失他的状态。checkpoint 也需要配置重启策略。响应式模式将会尊重配置的重启策略:如果没有配置重启策略,响应式模式会使作业失败,而不是调整它。
-
响应式模式下的缩小资源可能会导致很长的暂停时间,因为 Flink 会等待 JobManager 和停止的 TaskManager 之间的心跳超时。你将会看到你的 Flink 作业使用一个较小的并行度重新部署之前卡主大概 50 秒。
默认超时时间配置为 50 秒,可以通过
heartbeat.timeout配置将其设置为一个更低的值。设置心跳超时为一个更低的值,可能会导致 TaskManager 在恢复心跳时失败,比如由于网络波动或长时间的 GC 暂停。注意:
heartbeat.interval通常需要低于超时时间heartbeat.timeout。
7.1.3. 限制
因为响应式模式是一个新的实验性的特性,所以默认的调度器支持所有的特性在响应式模式中并不都是可用的。Flink 社区正在努力解决这些限制。
-
只支持 standalone application 部署。资源提供者,比如原生 Kubernetes、YARN 或 Mesos,都不支持。standalone session 集群也不支持。application 部署仅限于单个作业程序。
只支持 Standalone in Application Mode 、Docker in Application Mode 和 Standalone Kubernetes Application Cluster 部署,
自适应调度器的局限性也适用于响应式模式。
7.2. 自适应调度器
直接使用自适应调度器,只可用于高级用户,因为没有定义在一个 session 集群上运行多个作业的 slot 收集。
自使用调度器可以根据可用 slot 数量来调整作业的并行度。如果没有足够可用的 slot 满足原始配置的并行度来运行作业,他将会自动减小作业的并行度,比如提交作业时没有足够的资源可用,或在作业运行期间 TaskManager 停止运行。如果新的 slot 可用,则作业将会再次被调整,以达到配置的并行度。在响应式模式中,配置的并行度将会被忽略,并且认为它为无限大,这会导致作业尽可能的使用更多的资源。你也可以在响应式模式中使用自适应调度器,但有一些限制:
- 如果你在 session 集群中使用自适应调度器,则对于同一 session 集群中多个正在运行的作业之间的 slot 分布,没有任何保证。
自适应调度器相比于默认调度器的一个好处是它可以优雅的处理 TaskManager 丢失,因为它可以在 TaskManager 丢失时进行资源降级。
7.2.1. 使用
需要设置下面的配置参数:
jobmanager.scheduler: adaptive:将默认调度器改为自适应调度器。cluster.declarative-resource-management.enabled:启用声明式资源管理,默认启用。
通过 adaptive-scheduler 包含的所有配置选项中的名称来配置自适应调度器的行为。
7.2.2. 限制
- 只支持流式作业:自适应调度器第一个版本只支持运行流式作业。当提交一个批作业时,我们将会自动切换会默认调度器。
- 不支持本地恢复:本地恢复可以让调度在机器上的任务重新使用机器上保存的状态进行恢复。缺乏这个特性意味着自适应调度器通常需要从 checkpoint 存储上下载整个状态。
- 不支持局部容错:局部容错意味着调度器可以重启失败作业的部分任务,而不是整个作业,在 Flink 内部叫 “regions”。该限制会影响多并行度作业的恢复时间:Flink 的默认调度器可以重启失败的部分,但是自适应调度器会重启整个作业。
- Flink Web Ui 整合限制:自适应调度器允许作业在它的生命周期内更改并行度。web UI 只会展示作业当前的并行度。
- 作业指标限制:除了重启次数,所有作业范围内可用的可用性和 checkpoint 指标都无法正常工作。
- 未被使用的 slot:如果 slot 共享组和最大并行度不相等,则提供给自适应调度器的 slot 不会被使用。
- 调整事件会触发作业和任务的重启,这会增加任务的尝试次数。
8. 文件系统
8.1. 概述
Apache Flink 使用文件系统来消费和持久化存储数据,以处理应用结果以及容错与恢复。以下是一些最常用的文件系统:本地存储,hadoop-compatible(HDFS),Amazon S3,MapR FS,阿里云 OSS 和 Azure Blob Storage。
文件使用的文件系统通过其 URI Scheme 指定。例如 file:///home/user/text.txt 表示一个在本地文件系统中的文件,hdfs://namenode:50010/data/user/text.txt 表示一个在指定 HDFS 集群中的文件。
文件系统在每个进程中实例化一次,然后进行缓存/池化,从而避免每次创建流时的配置开销,并强制执行特定的约束,如连接/流的限制。
8.1.1. 本地文件系统
Flink 原生支持本地机器上的文件系统,包括任何挂载到本地文件系统的 NFS 或 SAN 驱动器,默认开箱即用,无需额外配置。本地文件可通过 file:// URI Scheme 引用。
8.1.2. 可插拔的文件系统
Apache Flink 支持下列文件系统:
- Amazon S3 对象存储由
flink-s3-fs-presto和flink-s3-fs-hadoop两种替代实现提供支持。这两种实现都是独立的,没有依赖项。 - MapR FS 文件系统适配器已在 Flink 的主发行版中通过 maprfs:// URI Scheme 支持。MapR 库需要在 classpath 中指定(例如在
lib目录中)。 - **阿里云对象存储**由
flink-oss-fs-hadoop支持,并通过 oss:// URI scheme 使用。该实现基于 Hadoop Project,但其是独立的,没有依赖项。 - Azure Blob Storage 由
flink-azure-fs-hadoop支持,并通过 wasb(s)😕/ URI scheme 使用。该实现基于 Hadoop Project,但其是独立的,没有依赖项。 - Google Cloud Storage 由
gcs-connector支持,并通过 gs:// URI scheme 使用。该实现基于 Hadoop Project,但其是独立的,没有依赖项。
除 MapR FS 之外,上述文件系统可以作为插件使用。
使用外部文件系统时,在启动 Flink 之前需将对应的 JAR 文件从 opt 目录复制到 Flink 发行版 plugin 目录下的某一文件夹中,例如:
mkdir ./plugins/s3-fs-hadoop
cp ./opt/flink-s3-fs-hadoop-1.13.6.jar ./plugins/s3-fs-hadoop/
注意 文件系统的插件机制在 Flink 版本 1.9 中引入,以支持每个插件专有的 Java 类加载器,并避免类隐藏机制。您仍然可以通过旧机制使用文件系统,即将对应的 JAR 文件复制到 lib 目录中,或使用您自己的实现方式,但是从版本 1.10 开始,S3 插件必须通过插件机制加载,因为这些插件不再被隐藏(版本 1.10 之后类不再被重定位),旧机制不再可用。
尽可能通过基于插件的加载机制使用支持的文件系统。未来的 Flink 版本将不再支持通过 lib 目录加载文件系统组件。
8.1.3. 添加新的外部文件系统实现
文件系统由类 org.apache.flink.core.fs.FileSystem 表示,该类定义了访问与修改文件系统中文件与对象的方法。
要添加一个新的文件系统:
- 添加文件系统实现,它应是
org.apache.flink.core.fs.FileSystem的子类。 - 添加 Factory 类,以实例化该文件系统并声明文件系统所注册的 scheme, 它应是
org.apache.flink.core.fs.FileSystemFactory的子类。 - 添加 Service Entry。创建文件
META-INF/services/org.apache.flink.core.fs.FileSystemFactory,文件中包含文件系统 Factory 类的类名。(更多细节请查看 Java Service Loader docs)
在插件检索时,文件系统 Factory 类会由一个专用的 Java 类加载器加载,从而避免与其他类或 Flink 组件冲突。在文件系统实例化和文件系统调用时,应使用该类加载器。
警告 实际上这表示您的实现应避免使用 Thread.currentThread().getContextClassLoader() 类加载器。
8.1.4. Hadoop 文件系统 (HDFS) 以及其他实现
所有 Flink 无法找到直接支持的文件系统均将回退为 Hadoop。 当 flink-runtime 和 Hadoop 类包含在 classpath 中时,所有的 Hadoop 文件系统将自动可用。
因此,Flink 无缝支持所有实现 org.apache.hadoop.fs.FileSystem 接口的 Hadoop 文件系统和所有兼容 Hadoop 的文件系统 (Hadoop-compatible file system, HDFS):
- HDFS (已测试)
- Google Cloud Storage Connector for Hadoop(已测试)
- Alluxio(已测试,参见下文的配置详细信息)
- XtreemFS(已测试)
- FTP via Hftp(未测试)
- HAR(未测试)
- …
Hadoop 配置须在 core-site.xml 文件中包含所需文件系统的实现。可查看 Alluxio 的示例。
除非有其他的需要,建议使用 Flink 内置的文件系统。在某些情况下,如通过配置 Hadoop core-site.xml 中的 fs.defaultFS 属性将文件系统作为 YARN 的资源存储时,可能需要直接使用 Hadoop 文件系统。
8.1.4.1. Alluxio
在 core-site.xml 文件中添加以下条目以支持 Alluxio:
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>
8.2. 通用配置
Apache Flink 提供了一些对所有文件系统均适用的基本配置。
8.2.1. 默认文件系统
如果文件路径未明确指定文件系统的 scheme(和 authority),将会使用默认的 scheme(和 authority):
fs.default-scheme: <default-fs>
例如默认的文件系统配置为 fs.default-scheme: hdfs://localhost:9000/,则文件路径 /user/hugo/in.txt 将被处理为 hdfs://localhost:9000/user/hugo/in.txt。
8.2.2. 连接限制
如果文件系统不能处理大量并发读/写操作或连接,可以为文件系统同时打开的总连接数设置上限。
例如在一个大型 Flink 任务建立 checkpoint 时,具有少量 RPC handler 的小型 HDFS 集群可能会由于建立了过多的连接而过载。
要限制文件系统的连接数,可将下列配置添加至 Flink 配置中。设置限制的文件系统由其 scheme 指定:
fs.<scheme>.limit.total: (数量,0/-1 表示无限制)
fs.<scheme>.limit.input: (数量,0/-1 表示无限制)
fs.<scheme>.limit.output: (数量,0/-1 表示无限制)
fs.<scheme>.limit.timeout: (毫秒,0 表示无穷)
fs.<scheme>.limit.stream-timeout: (毫秒,0 表示无穷)
输入和输出连接(流)的数量可以分别通过fs.<scheme>.limit.input 和 fs.<scheme>.limit.output 进行限制,也可以通过 fs.<scheme>.limit.total 限制并发流的总数。如果文件系统尝试打开更多的流,操作将被阻塞直至某些流关闭。如果打开流的时间超过 fs.<scheme>.limit.timeout,则流打开失败。
为避免不活动的流占满整个连接池(阻止新连接的建立),可以在配置中添加无活动超时时间,如果连接至少在 fs.<scheme>.limit.stream-timeout 时间内没有读/写操作,则连接会被强制关闭。
连接数是按每个 TaskManager/文件系统来进行限制的。因为文件系统的创建是按照 scheme 和 authority 进行的,所以不同的 authority 具有独立的连接池,例如 hdfs://myhdfs:50010/ 和 hdfs://anotherhdfs:4399/ 会有单独的连接池。
8.3. Amazon S3
Amazon Simple Storage Service (Amazon S3) 提供用于多种场景的云对象存储。S3 可与 Flink 一起使用以读取、写入数据,并可与 流的 State backends 相结合使用。
通过以下格式指定路径,S3 对象可类似于普通文件使用:
s3://<your-bucket>/<endpoint>
Endpoint 可以是一个文件或目录,例如:
// 读取 S3 bucket
env.readTextFile("s3://<bucket>/<endpoint>");
// 写入 S3 bucket
stream.writeAsText("s3://<bucket>/<endpoint>");
// 使用 S3 作为 FsStatebackend
env.setStateBackend(new FsStateBackend("s3://<your-bucket>/<endpoint>"));
注意这些例子并不详尽,S3 同样可以用在其他场景,包括 JobManager 高可用配置 或 EmbeddedRocksDBStateBackend,以及所有 Flink 需要使用文件系统 URI 的位置。
在大部分使用场景下,可使用 flink-s3-fs-hadoop 或 flink-s3-fs-presto 两个独立且易于设置的 S3 文件系统插件。然而在某些情况下,例如使用 S3 作为 YARN 的资源存储目录时,可能需要配置 Hadoop S3 文件系统。
8.3.1. Hadoop/Presto S3 文件系统插件
注意: 如果您在使用 Flink on EMR,您无需手动对此进行配置。
Flink 提供了两种文件系统用来与 S3 交互:flink-s3-fs-presto 和 flink-s3-fs-hadoop。两种实现都是独立的且没有依赖项,因此使用时无需将 Hadoop 添加至 classpath。
-
flink-s3-fs-presto,通过 s3:// 和 s3p:// 两种 scheme 使用,基于 Presto project。 可以使用和 Presto 文件系统相同的配置项进行配置,方式为将配置添加到flink-conf.yaml文件中。如果要在 S3 中使用 checkpoint,推荐使用 Presto S3 文件系统。 -
flink-s3-fs-hadoop,通过 s3:// 和 s3a:// 两种 scheme 使用, 基于 Hadoop Project。 本文件系统可以使用类似 Hadoop S3A 的配置项进行配置,方式为将配置添加到flink-conf.yaml文件中。例如,Hadoop 有
fs.s3a.connection.maximum的配置选项。 如果你想在 Flink 程序中改变该配置的值,你需要将配置s3.connection.maximum: xyz添加到flink-conf.yaml文件中。Flink 会在内部将其转换成fs.s3a.connection.maximum,而无需通过 Hadoop 的 XML 配置文件来传递参数。另外,它是唯一支持 StreamingFileSink 和 FileSink 的 S3 文件系统。
flink-s3-fs-hadoop 和 flink-s3-fs-presto 都为 s3:// scheme 注册了默认的文件系统包装器,flink-s3-fs-hadoop 另外注册了 s3a://,flink-s3-fs-presto 注册了 s3p://,因此二者可以同时使用。 例如某作业使用了 StreamingFileSink,它仅支持 Hadoop,但建立 checkpoint 使用 Presto。在这种情况下,建议明确地使用 s3a:// 作为 sink (Hadoop) 的 scheme,checkpoint (Presto) 使用 s3p://。这一点对于 FileSink 同样成立。
在启动 Flink 之前,将对应的 JAR 文件从 opt 复制到 Flink 发行版的 plugins 目录下,以使用 flink-s3-fs-hadoop 或 flink-s3-fs-presto。
mkdir ./plugins/s3-fs-presto
cp ./opt/flink-s3-fs-presto-1.13.6.jar ./plugins/s3-fs-presto/
8.3.1.1. 配置访问凭据
在设置好 S3 文件系统包装器后,您需要确认 Flink 具有访问 S3 Bucket 的权限。
8.3.1.1.1. 身份和访问管理(IAM)(推荐使用)
建议通过 Identity and Access Management (IAM) 来配置 AWS 凭据。可使用 IAM 功能为 Flink 实例安全地提供访问 S3 Bucket 所需的凭据。关于配置的细节超出了本文档的范围,请参考 AWS 用户手册中的 IAM Roles 部分。
如果配置正确,则可在 AWS 中管理对 S3 的访问,而无需为 Flink 分发任何访问密钥(Access Key)。
8.3.1.1.2. 访问密钥(Access Key)(不推荐)
可以通过**访问密钥对(access and secret key)**授予 S3 访问权限。请注意,根据 Introduction of IAM roles,不推荐使用该方法。
s3.access-key 和 s3.secret-key 均需要在 Flink 的 flink-conf.yaml 中进行配置:
s3.access-key: your-access-key
s3.secret-key: your-secret-key
8.3.2. 配置非 S3 访问点
S3 文件系统还支持兼容 S3 的对象存储服务,如 IBM’s Cloud Object Storage 和 Minio。可在 flink-conf.yaml 中配置使用的访问点:
s3.endpoint: your-endpoint-hostname
8.3.3. 配置路径样式的访问
某些兼容 S3 的对象存储服务可能没有默认启用虚拟主机样式的寻址。这种情况下需要在 flink-conf.yaml 中添加配置以启用路径样式的访问:
s3.path.style.access: true
8.3.4. S3 文件系统的熵注入
内置的 S3 文件系统 (flink-s3-fs-presto and flink-s3-fs-hadoop) 支持熵注入。熵注入是通过在关键字开头附近添加随机字符,以提高 AWS S3 bucket 可扩展性的技术。
如果熵注入被启用,路径中配置好的字串将会被随机字符所替换。例如路径 s3://my-bucket/_entropy_/checkpoints/dashboard-job/ 将会被替换成类似于 s3://my-bucket/gf36ikvg/checkpoints/dashboard-job/ 的路径。 这仅在使用熵注入选项创建文件时启用! 否则将完全删除文件路径中的 entropy key。更多细节请参见 FileSystem.create(Path, WriteOption)。
注意: 目前 Flink 运行时仅对 checkpoint 数据文件使用熵注入选项。所有其他文件包括 chekcpoint 元数据与外部 URI 都不使用熵注入,以保证 checkpoint URI 的可预测性。
配置 entropy key 与 entropy length 参数以启用熵注入:
s3.entropy.key: _entropy_
s3.entropy.length: 4 (default)
s3.entropy.key 定义了路径中被随机字符替换掉的字符串。不包含 entropy key 的路径将保持不变。 如果文件系统操作没有经过 “熵注入” 写入,entropy key 字串将被直接移除。 s3.entropy.length 定义了用于熵注入的随机字母/数字字符的数量。
8.4. Google Cloud Storage
Google Cloud storage (GCS) 提供了多样化的云存储使用案例,你可以使用它进行读写数据,并且在 流任务的 状态后端 中使用 FileSystemCheckpointStorage 时作为 checkpoint 存储。
你可以在配置了下面的格式之后,像访问常规文件一样通过指定的路径使用 GCS 对象:
gs://<your-bucket>/<endpoint>
endpoint 可以是单个文件或目录,比如:
// 从 GSC bucket 读取
env.readTextFile("gs://<bucket>/<endpoint>");
// 向 GCS bucket 写入
stream.writeAsText("gs://<bucket>/<endpoint>");
// 将 GCS 作为 checkpoint 存储
env.getCheckpointConfig().setCheckpointStorage("gs://<bucket>/<endpoint>");
8.4.1. Libraries
为了让 FLink 连接 gcs,你必须在 Flink 的 lib 目录下包含下面的 jar 包:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop2-uber</artifactId>
<version>${flink.shared_hadoop_latest_version}</version>
</dependency>
<dependency>
<groupId>com.google.cloud.bigdataoss</groupId>
<artifactId>gcs-connector</artifactId>
<version>hadoop2-2.2.0</version>
</dependency>
我们已经测试了 >= 2.8.3-1.8.3 版本的 flink-shared-hadoop2-uber ,你可以通过 gcs-connector hadoop 2 获取最新版本。
8.4.2. Authentication to access GCS
很多在 GCS 上的操作要求认证,请参考Google Cloud Storage 认证文档来获取更多信息。
你可以使用下面的方法进行认证:
-
通过配置
core-site.xml文件,你需要在core-site.xml中增加以下面的配置<configuration> <property> <name>google.cloud.auth.service.account.enable</name> <value>true</value> </property> <property> <name>google.cloud.auth.service.account.json.keyfile</name> <value><PATH TO GOOGLE AUTHENTICATION JSON></value> </property> </configuration>你还需要在
flink-conf.yaml中增加下面的配置flinkConfiguration: fs.hdfs.hadoopconf: <DIRECTORY PATH WHERE core-site.xml IS SAVED> -
你可以通过环境变量
GOOGLE_APPLICATION_CREDENTIALS提供必要的 key。
8.5. 阿里云对象存储服务 (OSS)
8.5.1. OSS:对象存储服务
阿里云对象存储服务 (Aliyun OSS) 使用广泛,尤其在中国云用户中十分流行,能提供多种应用场景下的云对象存储。OSS 可与 Flink 一起使用以读取与存储数据,以及与流状态后端 结合使用。
通过以下格式指定路径,OSS 对象可类似于普通文件使用:
oss://<your-bucket>/<object-name>
以下代码展示了如何在 Flink 作业中使用 OSS:
// 读取 OSS bucket
env.readTextFile("oss://<your-bucket>/<object-name>");
// 写入 OSS bucket
stream.writeAsText("oss://<your-bucket>/<object-name>")
// 将 OSS 用作 FsStatebackend
env.setStateBackend(new FsStateBackend("oss://<your-bucket>/<object-name>"));
8.5.2. Shaded Hadoop OSS 文件系统
为使用 flink-oss-fs-hadoop,在启动 Flink 之前,将对应的 JAR 文件从 opt 目录复制到 Flink 发行版中的 plugin 目录下的一个文件夹中,例如:
mkdir ./plugins/oss-fs-hadoop
cp ./opt/flink-oss-fs-hadoop-1.13.6.jar ./plugins/oss-fs-hadoop/
flink-oss-fs-hadoop 为使用 oss:// scheme 的 URI 注册了默认的文件系统包装器。
8.5.2.1. 配置步骤
在设置好 OSS 文件系统包装器之后,需要添加一些配置以保证 Flink 有权限访问 OSS buckets。
为了简单使用,可直接在 flink-conf.yaml 中使用与 Hadoop core-site.xml 相同的配置关键字。
可在 Hadoop OSS 文档 中查看配置关键字。
一些配置必须添加至 flink-conf.yaml (在 Hadoop OSS 文档中定义的其它配置为用作性能调优的高级配置):
fs.oss.endpoint: 连接的 Aliyun OSS endpoint
fs.oss.accessKeyId: Aliyun access key ID
fs.oss.accessKeySecret: Aliyun access key secret
备选的 CredentialsProvider 也可在 flink-conf.yaml 中配置,例如:
# 从 OSS_ACCESS_KEY_ID 和 OSS_ACCESS_KEY_SECRET 读取凭据 (Credentials)
fs.oss.credentials.provider: com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider
其余的凭据提供者(credential providers)可在这里中找到。
8.6. Azure Blob 存储
Azure Blob 存储 是一项由 Microsoft 管理的服务,能提供多种应用场景下的云存储。 Azure Blob 存储可与 Flink 一起使用以读取和写入数据,以及与流状态后端 结合使用。
通过以下格式指定路径,Azure Blob 存储对象可类似于普通文件使用:
wasb://<your-container>@$<your-azure-account>.blob.core.windows.net/<object-path>
// SSL 加密访问
wasbs://<your-container>@$<your-azure-account>.blob.core.windows.net/<object-path>
参见以下代码了解如何在 Flink 作业中使用 Azure Blob 存储:
// 读取 Azure Blob 存储
env.readTextFile("wasb://<your-container>@$<your-azure-account>.blob.core.windows.net/<object-path>");
// 写入 Azure Blob 存储
stream.writeAsText("wasb://<your-container>@$<your-azure-account>.blob.core.windows.net/<object-path>")
// 将 Azure Blob 存储用作 FsStatebackend
env.setStateBackend(new FsStateBackend("wasb://<your-container>@$<your-azure-account>.blob.core.windows.net/<object-path>"));
8.6.1. Shaded Hadoop Azure Blob 存储文件系统
为使用 flink-azure-fs-hadoop,在启动 Flink 之前,将对应的 JAR 文件从 opt 目录复制到 Flink 发行版中的 plugin 目录下的一个文件夹中,例如:
mkdir ./plugins/azure-fs-hadoop
cp ./opt/flink-azure-fs-hadoop-1.13.6.jar ./plugins/azure-fs-hadoop/
flink-azure-fs-hadoop 为使用 wasb:// 和 wasbs:// (SSL 加密访问) 的 URI 注册了默认的文件系统包装器。
8.6.2. 凭据配置
Hadoop 的 Azure 文件系统支持通过 Hadoop 配置来配置凭据,如 Hadoop Azure Blob Storage 文档 所述。 为方便起见,Flink 将所有的 Flink 配置添加 fs.azure 键前缀后转发至文件系统的 Hadoop 配置中。因此,可通过以下方法在 flink-conf.yaml 中配置 Azure Blob 存储密钥:
fs.azure.account.key.<account_name>.blob.core.windows.net: <azure_storage_key>
或者通过在 flink-conf.yaml 中设置以下配置键,将文件系统配置为从环境变量 AZURE_STORAGE_KEY 读取 Azure Blob 存储密钥:
fs.azure.account.keyprovider.<account_name>.blob.core.windows.net: org.apache.flink.fs.azurefs.EnvironmentVariableKeyProvider
8.7. 插件
插件机制通过特定的类加载器为代码的严格分离提供了便利。一个插件不能访问其他插件或 Flink 里不在白名单中指定的类。该隔离机制允许插件对于相同的库包含冲突的版本,而不需要移除冲突类或将库转换为相同的版本。目前,文件系统和指标上报是插件化的,但是在将来,连接器、格式甚至是用户代码也应该是插件化的。
8.7.1. 隔离和插件结构
插件都放在他们自己的目录中,并且可以放很多个 jar 包,插件目录的名字可以是任意的。
flink-dist
├── conf
├── lib
...
└── plugins
├── s3
│ ├── aws-credential-provider.jar
│ └── flink-s3-fs-hadoop.jar
└── azure
└── flink-azure-fs-hadoop.jar
每个插件都通过他们自己的类加载器进行加载,并且和其他插件完全隔离。因此, flink-s3-fs-hadoop 和 flink-azure-fs-hadoop 可以依赖不同且冲突的库版本,且不需要移除通过 shade 创建创建的 fat jar 中的任何类。
插件可能会访问 Flink lib/ 目录下包含在白名单的 jar 包,尤其是通过系统类加载器加载的必要的服务提供接口 (SPI),因此,即使用户在他们的 fat jar 中意外绑定了它,也不能同时存在两个版本的 org.apache.flink.core.fs.FileSystem。这个单例类是必要的,如此一来,Flink 运行时才能有一个进入插件的入口点。通过 java.util.ServiceLoader 来发现服务类,因此在 shade 打包时需要确保在 META-INF/services 中定义了服务。
注意:目前,在我们具象化了 SPI 系统时,插件仍然可以访问很多 Flink 核心类。
此外,很多公共的日志框架也在白名单中,因此在 Flink 核心类、插件和用户代码中均可访问日志类。
8.7.2. 文件系统
除了 except MapR 之外的文件系统都是插件化的,这意味着他们应该被当做插件使用。为了使用插件化的文件系统,在启动 Flink 之前,需要将对应的 JAR 文件从 Flink 分布式部署中的 opt 目录拷贝到 plugins 目录下的某个目录。比如:
mkdir ./plugins/s3-fs-hadoop
cp ./opt/flink-s3-fs-hadoop-1.13.6.jar ./plugins/s3-fs-hadoop/
s3 文件系统 (
flink-s3-fs-presto和flink-s3-fs-hadoop) 只能被当做插件使用,因为我们已经移除了他们,将他们放到lib/目录下会导致系统失败。
由于严格的隔离,文件系统已经无法访问
lib/目录下的凭证提供者了。请在各自的插件目录下增增加需要的提供者。
8.7.3. 指标上报
Flink 提供的所有指标上报都可以被当做插件使用,查看指标文档来后去更多细节。
9. 高可用
9.1. 概述
JobManager 高可用(HA)用来对 Flink 集群的 JobManager 进行容错,该特性可以保证 Flink 集群一直持续的运行提交的作业。
9.1.1. JobManager高可用
JobManager 会协调每个 Flink 的部署,它会同时负责调度和资源管理。
默认情况下,每个 Flink 集群只有一个 JobManager 实例。这会导致单点失败(SPOF)问题:如果 JobManager 崩溃,就无法提交新程序了,而且正在运行的程序也会失败。
通过 JobManager 高可用,就可以在 JobManager 失败后恢复,并且解决 SPOF 问题。你可以为每个集群部署配置高可用,查看可用的高可用服务列表来获取更多信息。
9.1.1.1. 配置高可用
JobManager 高可用的通常实现方式为:任何时候都有一个 leader 角色的 JobManager,然后有多个备用的 JobManager 在 leader 失败后接管 leader 角色。这可以保证没有单点失败问题,并且程序可以在备用 JobManager 成为 leader 时继续运行。
如下图,有部署了三个 JobManager 实例:

Flink 的高可用服务封装了必要的服务,以使所有工作都能正常进行:
- leader 选举:从
n个候选者池中选举一个 leader - 服务发现:检索当前 leader 的地址
- 状态持久化:持久化用来恢复作业执行的状态,比如:JobGraph、用户代码 jar、完整的 checkpoint
9.1.2. 高可用服务
Flink 提供了两种该可用该服务实现:
- ZooKeeper:ZooKeeper HA 服务可以被用于每个 Flink 集群部署,他们要求一个正在运行的 ZooKeeper 集群。
- Kubernetes:Kubernetes HA 服务只可用于 on Kubernetes 运行的 Flink。
9.1.3. 高可用数据生命周期
为了恢复提交的作业,Flink 会持久化元数据和作业数据。HA 数据会报一直保存,直到作业要么成功,要么被取消或失败终止。这些情况一旦发生,所有的 HA 数据,包括存储到 HA 服务中的元数据,都会被删除。
9.2. ZooKeeper HA服务
Flink ZooKeeper HA 服务使用 ZooKeeper 作为高可用服务。
Flink 使用 ZooKeeper 来分布式协调所有正在运行的 JobManager 实例。ZooKeeper 服务和 Flink 单独分开的,ZooKeeper 提供了高可用分布式协调的 leader 选举,以及轻量级的一致性状态存储。通过 ZooKeeper 的入门指南 来获取更多有关 ZooKeeper 信息。Flink 内置了启动一个简单的 ZooKeeper 的安装脚本。
9.2.1. 配置
为了启动一个高可用集群,你需要配置下面的这些参数:
-
high-availability (必选):
high-availability选项必须设置为zookeeper。high-availability: zookeeper -
high-availability.storageDir (必选):JobManager 元数据会被持久化到通过
high-availability.storageDir配置的文件系统,并且只有指向该状态的指针会被存储到 ZooKeeper 中。high-availability.storageDir: hdfs:///flink/recoverystorageDir会存储为了恢复失败 JobManager 的所有元数据。 -
[high-availability.zookeeper.quorum]({%link deployment/config.md %}#high-availability-zookeeper-quorum) (必选):ZooKeeper 服务复制组的 ZooKeeper quorum,用来提供分布式协调服务。
high-availability.zookeeper.quorum: address1:2181[,...],addressX:2181每个
addressX:port都指向一个 ZooKeeper 服务,并且 Flink 可以通过它来访问 ZooKeeper。 -
high-availability.zookeeper.path.root (推荐):ZooKeeper 的根节点,所有的 flink 集群节点都会放到它下面。
high-availability.zookeeper.path.root: /flink -
high-availability.cluster-id (推荐):存放到 ZooKeeper 的 Flink 集群 ID,所有 Flink 集群的协调数据都会放到它下面。
high-availability.cluster-id: /default_ns # 重要提示:对每个集群都自定义一个名称重要:当使用 on YARN、原生 Kubernetes 或其他集群管理者运行 Flink 时不要设置该参数值。在这些情况下,会自动生成 cluster-id。如果你裸机部署了多个 Flink HA 集群,你需要对每个集群手动配置单独的 cluster-id。
9.2.1.1. 配置示例
在 conf/flink-conf.yaml 中配置高可用模式和 ZooKeeper quorum:
high-availability: zookeeper
high-availability.zookeeper.quorum: localhost:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_one # 重要提示:对每个 flink 集群单独配置 id
high-availability.storageDir: hdfs:///flink/recovery
9.2.2. ZooKeeper安全配置
如果 ZooKeeper 使用 Kerberos 在安全模式下运行,需要在 flink-conf.yaml 中覆盖下面的配置:
# 默认为 zookeeper。如果 ZooKeeper quorum 配置了不同的服务名称,可以在这儿配置对应的名称。
zookeeper.sasl.service-name: zookeeper
# 默认为 Client。配置值应该匹配 "security.kerberos.login.contexts" 中的某个值。
zookeeper.sasl.login-context-name: Client
可以通过参考 Flink 配置的安全部分来获取更多 Flink 的 Kerberos 安全配置,也可以通过 Flink 内部基于 Kerberos 的设置 获取更进一步的细节。
9.2.3. ZooKeeper版本
Flink 单独存放了 3.4 和 3.5 版本的 ZooKeeper 客户端,lib 目录下默认放置的是 3.4 版本客户端,3.5 版本的客户端放在 opt 目录下。
3.5 版本客户端允许通过 SSL 安全访问 ZooKeeper,但可能无法访问 3.4 版本 ZooKeeper。
你可以通过在 lib 目录下存放对应的 jar 包来控制使用哪个版本的 ZooKeeper 客户端。
9.2.4. 启动ZooKeeper
如果你现在没有一个正在运行的 ZooKeeper 集群,可以使用 Flink 提供的帮助脚本来运行一个简单的 Flink 集群。
conf/zoo.cfg 文件内容为 ZooKeeper 的配置模板。你可以通过 server.X 条目来配置运行 ZooKeeper 的主机,其中 X 为每个服务的唯一 ID:
server.X=addressX:peerPort:leaderPort
[...]
server.Y=addressY:peerPort:leaderPort
脚本 bin/start-zookeeper-quorum.sh 会在配置的每个主机上启动一个 ZooKeeper 服务,通过 Flink 包装器启动的 ZooKeeper 服务进程,会读取 conf/zoo.cfg 中的配置,并且为了方便,会设置一些必要的配置值。在生产环境中,建议管理自己的 ZooKeeper 集群。
9.3. Kubernetes HA服务
Flink 的 Kubernetes HA 服务使用 Kubernetes 来实现高可用。
只有在 Kubernetes 上部署 Flink 时才可使用 Kubernetes 高可用服务,因此,可以通过 standalone Flink on Kubernetes or the 原生 Kubernetes 整合 来配置他们。
9.3.1. 前置条件
为了使用 Flink 的 Kubernetes HA 服务,必须完全满足下面的要求:
- Kubernetes >= 1.9.
- 服务账号有创建、编辑、删除 ConfigMap 的权限。查看 Flink’s native Kubernetes integration 或 standalone Flink on Kubernetes 来获取更多有关如何配置服务账号的信息。
9.3.2. 配置
为了启动一个 HA 集群,你需要配置下面这些参数:
- high-availability (必选):
high-availability选项必须被设置为:KubernetesHaServicesFactory。
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
- high-availability.storageDir (必选):JobManager 元数据会持久化到
high-availability.storageDir指定的文件系统,并且只会在 Kubernetes 中保存一个指向状态的指针。
high-availability.storageDir: s3://flink/recovery
`storageDir` 会存储所有用来恢复失败 JobManager 的元数据。
- kubernetes.cluster-id (必选):为了标识 Flink 集群,必须指定
kubernetes.cluster-id。
kubernetes.cluster-id: cluster1337
9.3.2.1. 配置示例
在 conf/flink-conf.yaml 中配置高可用模式:
kubernetes.cluster-id: <cluster-id>
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: hdfs:///flink/recovery
9.3.3. 高可用数据清理
为了在重启 Flink 集群时保存高可用数据,可以通过 kubectl delete deployment <cluster-id> 来简单的删除部署。所有 Flink 集群相关资源都将会被删除,比如:JobManager 部署、TaskManager pod、服务、Flink ConfigMap 配置。与 HA 相关的 ConfigMap 将会被保留,因为他们没有设置所有者引用。当重启集群时,所有之前运行的作业将会被恢复,并且使用最新成功的 checkpoint 重启。
10. 指标上报
Flink 允许指标上报到外部系统,更多有关 Flink 的指标系统信息,请参考指标系统文档。
10.1. 上报器
可以通过在 conf/flink-conf.yaml 中配置一个或多个上报器将指标暴露给外部系统,在他们启动时,这些上报器将会被安装到每个作业和任务管理器。
metrics.reporter.<name>.<config>:名为<name>的上报器的通用配置<config>。metrics.reporter.<name>.class:名为<name>的上报器对应的类。metrics.reporter.<name>.factory.class:名为<name>的上报器对应的工厂类。metrics.reporter.<name>.interval:名为<name>的上报器上报数据的时间间隔。metrics.reporter.<name>.scope.delimiter: 名为<name>的上报器标识的分隔符号,默认使用metrics.scope.delimiter值。metrics.reporter.<name>.scope.variables.excludes:可选,使用英文分号分割的变量列表,列表中基于标签的上报器应该被忽略,比如:Prometheus, InfluxDB。metrics.reporters:可选,使用英文逗号分割的包含上报器名称的列表,默认情况下,所有配置的上报器都将会被使用。
所有上报器必须配置 class 或 factory.class 配置之一,具体使用配置哪个参数,取决于上报器的实现。查看对应上报器的配置章节获取更多信息。一些上报器需要指定上报 interval,下面列出了每个上报器的设置。
指定多个上报器的配置示例:
metrics.reporters: my_jmx_reporter,my_other_reporter
metrics.reporter.my_jmx_reporter.factory.class: org.apache.flink.metrics.jmx.JMXReporterFactory
metrics.reporter.my_jmx_reporter.port: 9020-9040
metrics.reporter.my_jmx_reporter.scope.variables.excludes:job_id;task_attempt_num
metrics.reporter.my_other_reporter.class: org.apache.flink.metrics.graphite.GraphiteReporter
metrics.reporter.my_other_reporter.host: 192.168.1.1
metrics.reporter.my_other_reporter.port: 10000
重要:包含上报器对应的 jar 包必须在 Flink 启动时可以被访问,支持 factory.class 的上报器可以通过插件形式加载,否则,jar 包必须放到 /lib 目录下。Flink 提供的上报器(该章节中提到的上报器)默认都直接可用。
可以通过实现 org.apache.flink.metrics.reporter.MetricReporter 接口来定制化自己的 Reporter 上报器,如果上报器需要定期发送指标,则还需要实现 Scheduled 接口。通过增加对 MetricReporterFactory 接口的实现,你的上报器也可以作为插件进行加载。
下面的章节列出了所有支持的上报器。
10.1.1. JMX
org.apache.flink.metrics.jmx.JMXReporter
JMX 上报器默认已经可用,因此你无需增加额外的依赖,但是并没有开启上报。
参数:
port:可选,连接 JMX 的监听端口。为了在一个主机上运行几个不同的上报器实例,将端口号配置为类似于9250-9260的范围是一个很好的选择。当配置为范围时,真正使用的端口号会在相关的作业或 TaskManager 日志中展现。如果设置了该参数,则 Flink 会为给定的 端口号/范围 启动一个额外的 JMX 连接器。默认的本地 JMX 接口的指标都是可用的。
配置示例:
metrics.reporter.jmx.factory.class: org.apache.flink.metrics.jmx.JMXReporterFactory
metrics.reporter.jmx.port: 8789
通过 JMX 暴露的指标通过一个域名和 key-properties 列表来标识,他们共同构成对象的名称。
域名通常以 org.apache.flink 为开头,后面跟着生成的指标标识。和常见的标识符不同,他不会受到作用域格式的影响,不包含任何变量,并且在多个作业之间都是一样的。比如: org.apache.flink.job.task.numBytesOut。
key-property 列表包含了所有变量的值,不管配置的作用域格式是什么,他们都会和一个给定的指标相关。这样一个列表的案例为:host=localhost,job_name=MyJob,task_name=MyTask。
域名会标识一个指标 class 类,key-property 列表会标识指标对应的一个或多个实例。
10.1.2. Graphite
org.apache.flink.metrics.graphite.GraphiteReporter
参数:
host- Graphite 服务主机名port- Graphite 服务端口号protocol- 使用的协议:TCP/UDP
配置示例:
metrics.reporter.grph.factory.class: org.apache.flink.metrics.graphite.GraphiteReporterFactory
metrics.reporter.grph.host: localhost
metrics.reporter.grph.port: 2003
metrics.reporter.grph.protocol: TCP
metrics.reporter.grph.interval: 60 SECONDS
10.1.3. Influx
org.apache.flink.metrics.influxdb.InfluxdbReporter
为了使用该上报器,你必须在你的 Flink 部署环境下拷贝 /opt/flink-metrics-influxdb-1.13.6.jar 到 plugins/influxdb 目录下。
配置:
| Key | 默认值 | 类型 | 描述 |
|---|---|---|---|
| scheme | http | 枚举可用值: [http, https] | InfluxDB schema |
| host | (none) | String | InfluxDB 服务的主机名 |
| port | 8086 | Integer | InfluxDB 服务的端口号 |
| username | (none) | String | 可选,InfluxDB 用户名 |
| password | (none) | String | 可选,InfluxDB 密码 |
| db | (none) | String | InfluxDB 存储指标的数据库名称 |
| consistency | ONE | 枚举可用值: [ALL, ANY, ONE, QUORUM] | 可选,InfluxDB的一致性级别 |
| retentionPolicy | (none) | String | 可选,InfluxDB 的数据保留策略 |
| connectTimeout | 10000 | Integer | 可选,连接 InfluxDB 的超时时间 |
| writeTimeout | 10000 | Integer | 可选,写入 InfluxDB 的超时时间 |
配置案例:
metrics.reporter.influxdb.factory.class: org.apache.flink.metrics.influxdb.InfluxdbReporterFactory
metrics.reporter.influxdb.scheme: http
metrics.reporter.influxdb.host: localhost
metrics.reporter.influxdb.port: 8086
metrics.reporter.influxdb.db: flink
metrics.reporter.influxdb.username: flink-metrics
metrics.reporter.influxdb.password: qwerty
metrics.reporter.influxdb.retentionPolicy: one_hour
metrics.reporter.influxdb.consistency: ANY
metrics.reporter.influxdb.connectTimeout: 60000
metrics.reporter.influxdb.writeTimeout: 60000
metrics.reporter.influxdb.interval: 60 SECONDS
上报器会使用 http 协议以及指定的保留策略或 InfluxDB 服务的默认策略发送指标到 InfluxDB 服务。所有的 Flink 指标变量(查看变量列表)会暴露为 InfluxDB 标签。
10.1.4. Prometheus
org.apache.flink.metrics.prometheus.PrometheusReporter
参数:
port:可选,Prometheus 上报器监听端口号,默认为 9249。为了在一个主机上运行多个上报器实例,可以将端口号配置为范围形式,比如:9250-9260。filterLabelValueCharacters:可选,是否过滤标签值字符。如果启用,则所有没有匹配 [a-zA-Z0-9:_] 的字符都会被移除,如果禁用,则不会移除任何字符。在禁用该选项之前,请确保你的标签值符合 Prometheus 要求。
配置案例:
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
下面的 Flink 指标类型匹配了 Prometheus 的指标类型:
| Flink | Prometheus | 备注 |
|---|---|---|
| Counter | Gauge | Prometheus 计数器不能降低 |
| Gauge | Gauge | 只支持数字和 boolean |
| Histogram | Summary | 分位数:.5, .75, .95, .98, .99 和 .999 |
| Meter | Gauge | 仪表会输出计量的速率 |
所有的 Flink 指标变量(变量列表)会作为标签上报给 Prometheus。
10.1.5. PrometheusPushGateway
org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
参数:
| Key | 默认值 | 类型 | 描述 |
|---|---|---|---|
| deleteOnShutdown | true | Boolean | 在停止后是否从 PushGateway 中删除指标。Flink 会尽最大努力去删除指标,但是无法保证一定可以删除掉。查看这儿获取更多细节。 |
| filterLabelValueCharacters | true | Boolean | 是否过滤标签值字符。如果启用,则所有没有匹配 [a-zA-Z0-9:_] 的字符都会被移除,如果禁用,则不会移除任何字符。在禁用该选项之前,请确保你的标签值符合 Prometheus 要求。 |
| groupingKey | (none) | String | 指定分区键,它是所有指标的分组和全局标签。通过 ‘=’ 来分隔标签名和值,通过 ‘;’ 来分隔多个标签,比如:k1=v1;k2=v2。请确保你的分组键符合 Prometheus 要求。 |
| host | (none) | String | PushGateway 服务主机名。 |
| jobName | (none) | String | 推送指标的作业名称。 |
| port | -1 | Integer | PushGateway 服务端口号。 |
| randomJobNameSuffix | true | Boolean | 是否将随机字符串追加到作业名称后面。 |
配置案例:
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: localhost
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.jobName: myJob
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
metrics.reporter.promgateway.groupingKey: k1=v1;k2=v2
metrics.reporter.promgateway.interval: 60 SECONDS
PrometheusPushGatewayReporter 会将指标推送到 Pushgateway,PushGateway 会将数据上报给 Prometheus。
查看 Prometheus 文档来获取用户案例。
10.1.6. StatsD
org.apache.flink.metrics.statsd.StatsDReporter
参数:
host- StatsD 服务主机名port- StatsD 服务端口号
配置案例:
metrics.reporter.stsd.factory.class: org.apache.flink.metrics.statsd.StatsDReporterFactory
metrics.reporter.stsd.host: localhost
metrics.reporter.stsd.port: 8125
metrics.reporter.stsd.interval: 60 SECONDS
10.1.7. Datadog
org.apache.flink.metrics.datadog.DatadogHttpReporter
Flink 指标的任何变量,比如:<host>, <job_name>, <tm_id>, <subtask_index>, <task_name>, 和 <operator_name>,将会作为标签发送到 Datadog。标签类似于: host:localhost 和 job_name:myjobname。
注:直方图会按照 Datadog 直方图的命名习惯(<metric_name>.<aggregation>)暴露一系列度量。默认会上报 min 聚合,然后 sum 聚合不可用。和 Datadog 提供的直方图不同,上报的聚合指标并不是根据指定上报间隔计算的聚合结果。
参数:
apikey- Datadog API keytags:可选,指标上报到 Datadog 时使用的全局标签,标签之间只能通过英文逗号分隔。proxyHost:可选,使用的代理主机名proxyPort:可选,使用的代理端口号,默认为 8080dataCenter:可选,连接的数据中心,默认为US,可用值有:EU/US。maxMetricsPerRequest:可选,每次请求可以包含的最大指标数量,默认为 2000
配置案例:
metrics.reporter.dghttp.factory.class: org.apache.flink.metrics.datadog.DatadogHttpReporterFactory
metrics.reporter.dghttp.apikey: xxx
metrics.reporter.dghttp.tags: myflinkapp,prod
metrics.reporter.dghttp.proxyHost: my.web.proxy.com
metrics.reporter.dghttp.proxyPort: 8080
metrics.reporter.dghttp.dataCenter: US
metrics.reporter.dghttp.maxMetricsPerRequest: 2000
metrics.reporter.dghttp.interval: 60 SECONDS
10.1.8. Slf4j
org.apache.flink.metrics.slf4j.Slf4jReporter
配置案例:
metrics.reporter.slf4j.factory.class: org.apache.flink.metrics.slf4j.Slf4jReporterFactory
metrics.reporter.slf4j.interval: 60 SECONDS
11. 安全
包含了 SSL 和 Kerberos 的相关配置使用,暂时不做翻译整理。
12. REPL
包含了 Python 和 Scala 的 REPL 相关介绍和使用方式,暂不做翻译整理。
13. 扩展
13.1. 扩展资源框架
许多计算任务需要使用除了 CPU 与内存外的资源,比如深度学习需要使用 GPU 来进行加速。为了支持这种扩展资源,Flink 提供了一个扩展资源框架。该框架支持从底层资源管理系统(如 Kubernetes)请求各种类型的资源,并向算子提供使用这些资源所需的信息。该框架以插件形式支持不同的资源类型。目前 Flink 仅内置了支持 GPU 资源的插件,你可以为你想使用的资源类型实现第三方插件。
13.1.1. 扩展资源框架做了什么
扩展资源(External Resource)框架主要做了以下两件事:
- 根据你的配置,在 Flink 从底层资源管理系统中申请资源时,设置与扩展资源相关的请求字段
- 为算子提供使用这些资源所需要的信息
当 Flink 部署在资源管理系统(Kubernetes、Yarn)上时,扩展资源框架将确保分配的 Pod、Container 包含所需的扩展资源。目前,许多资源管理系统都支持扩展资源。例如,Kubernetes 从 v1.10 开始通过 Device Plugin 机制支持 GPU、FPGA 等资源调度,Yarn 从 2.10 和 3.1 开始支持 GPU 和 FPGA 的调度。目前,扩展资源框架并不支持 Mesos 模式。在 Standalone 模式下,由用户负责确保扩展资源的可用性。
扩展资源框架向算子提供扩展资源相关信息,这些信息由你配置的扩展资源 Driver 生成,包含了使用扩展资源所需要的基本属性。
13.1.2. 启用扩展资源框架
为了启用扩展资源框架来使用扩展资源,你需要:
- 为该扩展资源准备扩展资源框架的插件
- 为该扩展资源设置相关的配置
- 在你的算子中,从
RuntimeContext来获取扩展资源的信息并使用这些资源
13.1.2.1. 准备插件
你需要为使用的扩展资源准备插件,并将其放入 Flink 发行版的 plugins/ 文件夹中, 参看 Flink Plugins。 Flink 提供了的 GPU 资源插件。你同样可以为你所使用的扩展资源实现自定义插件实现自定义插件。
13.1.2.2. 配置项
首先,你需要使用分隔符“;”将所有使用的扩展资源类型的资源名称添加到扩展资源列表(配置键“external-resources”)中,例如,“external-resources: gpu;fpga”定义了两个扩展资源“gpu”和“fpga”。 只有此处定义了扩展资源名称(<resource_name>),相应的资源才会在扩展资源框架中生效。
对于每个扩展资源,有以下配置选项。下面的所有配置选项中的 <resource_name> 对应于扩展资源列表中列出的名称:
- 数量 (
external.<resource_name>.amount):需要从外部系统请求的扩展资源的数量。 - Yarn 中的扩展资源配置键 (
external-resource.<resource_name>.yarn.config-key):可选配置。如果配置该项,扩展资源框架将把这个键添加到 Yarn 的容器请求的资源配置中,该键对应的值将被设置为external-resource.<resource_name>.amount。 - Kubernetes 中的扩展资源配置键 (
external-resource.<resource_name>.kubernetes.config-key):可选配置。 如果配置该项,扩展资源框架将添加resources.limits.<config-key>和resources.requests.<config-key>到 TaskManager 的主容器配置中,对应的值将被设置为external-resource.<resource_name>.amount。 - Driver 工厂类 (
external-resource.<resource_name>.driver-factory.class):可选配置。定义由 <resource_name> 标识的扩展资源对应的工厂类名。如果配置该项,该工厂类将被用于实例化扩展资源框架中所需要的 drivers。如果没有配置,扩展资源依然会在其他配置正确时在存在于TaskManager,只是算子在这种情况下无法从RuntimeContext中拿到该资源的信息。 - Driver 自定义参数(
external-resource.<resource_name>.param.<param>):可选配置。由 <resource_name> 标识的扩展资源的自定义配置选项的命名模式。只有遵循此模式的配置才会传递到该扩展资源的工厂类。
示例配置,该配置定义两个扩展资源:
external-resources: gpu;fpga # 定义两个扩展资源,“gpu”和“fpga”。
external-resource.gpu.driver-factory.class: org.apache.flink.externalresource.gpu.GPUDriverFactory # 定义 GPU 资源对应 Driver 的工厂类。
external-resource.gpu.amount: 2 # 定义每个 TaskManager 所需的 GPU 数量。
external-resource.gpu.param.discovery-script.args: --enable-coordination # 自定义参数 discovery-script.args,它将被传递到 GPU 对应的 Driver 中。
external-resource.fpga.driver-factory.class: org.apache.flink.externalresource.fpga.FPGADriverFactory # 定义 FPGA 资源对应 Driver 的工厂类。
external-resource.fpga.amount: 1 # 定义每个 TaskManager 所需的 FPGA 数量。
external-resource.fpga.yarn.config-key: yarn.io/fpga # 定义 FPGA 在 Yarn 中对应的配置键。
13.1.2.3. 使用扩展资源
为了使用扩展资源,算子需要从 RuntimeContext 获取 ExternalResourceInfo 集合。 ExternalResourceInfo 包含了使用扩展资源所需的信息,可以使用 getProperty 检索这些信息。 其中具体包含哪些属性以及如何使用这些属性取决于特定的扩展资源插件。
算子可以通过 getExternalResourceInfos(String resourceName) 从 RuntimeContext 或 FunctionContext 中获取特定扩展资源的 ExternalResourceInfo。 此处的 resourceName 应与在扩展资源列表中定义的名称相同。具体用法如下:
Java
public class ExternalResourceMapFunction extends RichMapFunction<String, String> {
private static final String RESOURCE_NAME = "foo";
@Override
public String map(String value) {
Set<ExternalResourceInfo> externalResourceInfos = getRuntimeContext().getExternalResourceInfos(RESOURCE_NAME);
List<String> addresses = new ArrayList<>();
externalResourceInfos.iterator().forEachRemaining(externalResourceInfo ->
addresses.add(externalResourceInfo.getProperty("address").get()));
// map function with addresses.
// ...
}
}
Scala
class ExternalResourceMapFunction extends RichMapFunction[(String, String)] {
var RESOURCE_NAME = "foo"
override def map(value: String): String = {
val externalResourceInfos = getRuntimeContext().getExternalResourceInfos(RESOURCE_NAME)
val addresses = new util.ArrayList[String]
externalResourceInfos.asScala.foreach(
externalResourceInfo => addresses.add(externalResourceInfo.getProperty("address").get()))
// map function with addresses.
// ...
}
}
ExternalResourceInfo 中包含一个或多个键-值对,其键值表示资源的不同维度。你可以通过 ExternalResourceInfo#getKeys 获取所有的键。
**提示:**目前,RuntimeContext#getExternalResourceInfos 返回的信息对所有算子都是可用的。
13.1.3. 为你所使用的扩展资源实现自定义插件
要为你所使用的扩展资源实现自定义插件,你需要:
- 添加你自定义的扩展资源 Driver ,该 Driver 需要实现
org.apache.flink.api.common.externalresource.ExternalResourceDriver接口。 - 添加用来实例化 Driver 的工厂类,该工厂类需要实现
org.apache.flink.api.common.externalresource.ExternalResourceDriverFactory接口。 - 添加服务入口。创建
META-INF/services/org.apache.flink.api.common.externalresource.ExternalResourceDriverFactory文件,其中包含了 Driver 对应工厂类的类名(更多细节请参看 Java Service Loader)。
例如,要为名为“FPGA”的扩展资源实现插件,你首先需要实现 FPGADriver 和 FPGADriverFactory:
Java
public class FPGADriver implements ExternalResourceDriver {
@Override
public Set<FPGAInfo> retrieveResourceInfo(long amount) {
// 返回 "FPGA" 的信息
}
}
public class FPGADriverFactory implements ExternalResourceDriverFactory {
@Override
public ExternalResourceDriver createExternalResourceDriver(Configuration config) {
return new FPGADriver();
}
}
// 包含 "FPGA" 资源基础配置的实现类 FPGAInfo
public class FPGAInfo implements ExternalResourceInfo {
@Override
public Optional<String> getProperty(String key) {
// 返回给定 key 的属性值
}
@Override
public Collection<String> getKeys() {
// 返回所有 key
}
}
Scala
class FPGADriver extends ExternalResourceDriver {
override def retrieveResourceInfo(amount: Long): Set[FPGAInfo] = {
// 返回 "FPGA" 的信息
}
}
class FPGADriverFactory extends ExternalResourceDriverFactory {
override def createExternalResourceDriver(config: Configuration): ExternalResourceDriver = {
new FPGADriver()
}
}
// 包含 "FPGA" 资源基础配置的实现类 FPGAInfo
class FPGAInfo extends ExternalResourceInfo {
override def getProperty(key: String): Option[String] = {
// 返回给定 key 的属性值
}
override def getKeys(): util.Collection[String] = {
// 返回所有 key
}
}
在 META-INF/services/ 中创建名为 org.apache.flink.api.common.externalresource.ExternalResourceDriverFactory 的文件,向其中写入工厂类名,如 your.domain.FPGADriverFactory。
之后,将 FPGADriver,FPGADriverFactory,META-INF/services/ 和所有外部依赖打入 jar 包。在你的 Flink 发行版的 plugins/ 文件夹中创建一个名为“fpga”的文件夹,将打好的 jar 包放入其中。更多细节请查看 Flink Plugin。
**提示:**扩展资源由运行在同一台机器上的所有算子共享。社区可能会在未来的版本中支持外部资源隔离。
13.1.4. 已支持的扩展资源插件
目前,Flink提供了 GPU 资源插件。
13.1.4.1. GPU 插件
我们为 GPU 提供了第一方插件。该插件利用一个脚本来发现 GPU 设备的索引,该索引可通过“index”从 ExternalResourceInfo 中获取。我们提供了一个默认脚本,可以用来发现 NVIDIA GPU。您还可以提供自定义脚本。
我们提供了一个示例程序,展示了如何在 Flink 中使用 GPU 资源来做矩阵-向量乘法。
**提示:**目前,对于所有算子,RuntimeContext#getExternalResourceInfos 会返回同样的资源信息。也就是说,在同一个 TaskManager 中运行的所有算子都可以访问同一组 GPU 设备。扩展资源目前没有算子级别的隔离。
13.1.4.1.1. 前置准备
要使 GPU 资源可访问,根据您的环境,需要满足以下先决条件:
- 对于 Standalone 模式,集群管理员应确保已安装 NVIDIA 驱动程序,并且集群中所有节点上的 GPU 资源都是可访问的。
- 对于 Yarn 上部署,管理员需要配置 Yarn 集群使其支持 GPU 调度。 请注意,所需的 Hadoop 版本是 2.10+ 和 3.1+。
- 对于 Kubernetes 上部署,管理员需要保证 NVIDIA GPU 的 Device Plugin 已在集群上安装。 请注意,所需的 Kubernetes 版本是 1.10+。目前,Kubernetes只支持 NVIDIA GPU 和 AMD GPU。Flink 只提供了 NVIDIA GPU 的脚本,但你可以提供支持 AMD GPU 的自定义脚本,参看 发现脚本。
13.1.4.1.2. 在计算任务中使用 GPU 资源
如启用扩展资源框架中所述,要使用 GPU 资源,还需要执行两项操作:
- 为 GPU 资源进行相关配置。
- 在算子中获取 GPU 资源的信息,其中包含键为“index”的 GPU 索引。
13.1.4.1.3. 配置项
对于 GPU 插件,你需要指定的扩展资源框架配置:
external-resources:你需要将 GPU 的扩展资源名称(例如“gpu”)加到该列表中。external-resource.<resource_name>.amount:每个 TaskManager 中的 GPU 数量。external-resource.<resource_name>.yarn.config-key:对于 Yarn,GPU 的配置键是yarn.io/gpu。请注意,Yarn 目前只支持 NVIDIA GPU。external-resource.<resource_name>.kubernetes.config-key:对于 Kubernetes,GPU 的配置键是<vendor>.com/gpu。 目前,“nvidia”和“amd”是两个支持的 GPU 品牌。请注意,如果你使用 AMD GPU,你需要提供一个自定义的发现脚本。external-resource.<resource_name>.driver-factory.class:需要设置为 org.apache.flink.externalresource.gpu.GPUDriverFactory。
此外,GPU 插件还有一些专有配置:
external-resource.<resource_name>.param.discovery-script.path:发现脚本的文件路径。 它既可以是绝对路径,也可以是相对路径,如果定义了“FLINK_HOME”,该路径将相对于“FLINK_HOME”,否则相对于当前目录。如果没有显式配置该项,GPU 插件将使用默认脚本。external-resource.<resource_name>.param.discovery-script.args:传递给发现脚本的参数。对于默认的发现脚本,请参见默认脚本以获取可用参数。
GPU 插件示例配置:
external-resources: gpu
external-resource.gpu.driver-factory.class: org.apache.flink.externalresource.gpu.GPUDriverFactory # 定义 GPU 资源的工厂类。
external-resource.gpu.amount: 2 # 定义每个 TaskManager 的 GPU 数量。
external-resource.gpu.param.discovery-script.path: plugins/external-resource-gpu/nvidia-gpu-discovery.sh
external-resource.gpu.param.discovery-script.args: --enable-coordination # 自定义参数,将被传递到 GPU 的 Driver 中。
external-resource.gpu.yarn.config-key: yarn.io/gpu # for Yarn
external-resource.gpu.kubernetes.config-key: nvidia.com/gpu # for Kubernetes
13.1.4.1.4. 发现脚本
GPUDriver 利用发现脚本来发现 GPU 资源并生成 GPU 资源信息。
13.1.4.1.4.1. 默认脚本
我们为 NVIDIA GPU 提供了一个默认脚本,位于 Flink 发行版的 plugins/external-resource-gpu/nvidia-gpu-discovery.sh。该脚本通过 nvidia-smi 工具获取当前可见 GPU 的索引。它尝试返回一个 GPU 索引列表,其大小由 external-resource.<resource_name>.amount 指定,如果 GPU 数量不足,则以非零退出。
在 Standalone 模式中,多个 TaskManager 可能位于同一台机器上,并且每个 GPU 设备对所有 TaskManager 都是可见的。 默认脚本提供 GPU 协调模式,在这种模式下,脚本利用文件来同步 GPU 的分配情况,并确保每个GPU设备只能由一个TaskManager进程使用。相关参数为:
--enable-coordination-mode:启用 GPU 协调模式。默认情况下不启用。--coordination-file filePath:用于同步 GPU 资源分配状态的文件路径。默认路径为/var/tmp/flink-gpu-coordination。
**提示:**协调模式只确保一个 GPU 设备不会被同一个 Flink 集群的多个 TaskManager 共享。不同 Flink 集群间(具有不同的协调文件)或非 Flink 应用程序仍然可以使用相同的 GPU 设备。
13.1.4.1.4.2. 自定义脚本
你可以提供一个自定义的发现脚本来满足你的特殊需求,例如使用 AMD GPU。请确保自定义脚本的的路径正确配置(external-resource.<resource_name>.param.discovery-script.path)并且 Flink 可以访问。自定义的发现脚本需要:
GPUDriver将 GPU 数量(由external-resource.<resource_name>.amount定义)作为第一个参数传递到脚本中。external-resource.<resource_name>.param.discovery-script.args中自定义的参数会被附加在后面。- 脚本需返回可用 GPU 索引的列表,用逗号分隔。空白的索引将被忽略。
- 脚本可以通过以非零退出来表示其未正确执行。在这种情况下,算子将不会得到 GPU 资源相关信息。
13.2. History Server
Flink 提供了 history server,可以在相应的 Flink 集群关闭之后查询已完成作业的统计信息。
此外,它暴露了一套 REST API,该 API 接受 HTTP 请求并返回 JSON 格式的数据。
13.2.1. 概览
HistoryServer 允许查询 JobManager 存档的已完成作业的状态和统计信息。
在配置了 HistoryServer 和 JobManager 之后,你可以使用相应的脚本来启动和停止 HistoryServer:
# 启动或者停止 HistoryServer
bin/historyserver.sh (start|start-foreground|stop)
默认情况下,此服务器绑定到 localhost 的 8082 端口。
目前,只能将 HistoryServer 作为独立的进程运行。
13.2.2. 配置参数
配置项 jobmanager.archive.fs.dir 和 historyserver.archive.fs.refresh-interval 需要根据 作业存档目录 和 刷新作业存档目录的时间间隔 进行调整。
JobManager
已完成作业的存档在 JobManager 上进行,将已存档的作业信息上传到文件系统目录中。你可以在 flink-conf.yaml 文件中通过 jobmanager.archive.fs.dir 设置一个目录存档已完成的作业。
# 上传已完成作业信息的目录
jobmanager.archive.fs.dir: hdfs:///completed-jobs
HistoryServer
可以通过 historyserver.archive.fs.dir 设置 HistoryServer 监视以逗号分隔的目录列表。定期轮询已配置的目录以查找新的存档;轮询间隔可以通过 historyserver.archive.fs.refresh-interval 来配置。
# 监视以下目录中已完成的作业
historyserver.archive.fs.dir: hdfs:///completed-jobs
# 每 10 秒刷新一次
historyserver.archive.fs.refresh-interval: 10000
所包含的存档被下载缓存在本地文件系统中。本地目录通过 historyserver.web.tmpdir 配置。
请查看配置页面以获取配置选项的完整列表。
13.2.3. 可用的请求
以下是可用且带有示例 JSON 响应的请求列表。所有请求格式样例均为 http://hostname:8082/jobs,下面我们仅列出了 URLs 的 path 部分。尖括号中的值为变量,例如作业 7684be6004e4e955c2a558a9bc463f65 的 http://hostname:port/jobs/<jobid>/exceptions 请求须写为 http://hostname:port/jobs/7684be6004e4e955c2a558a9bc463f65/exceptions。
/config/jobs/overview/jobs/<jobid>/jobs/<jobid>/vertices/jobs/<jobid>/config/jobs/<jobid>/exceptions/jobs/<jobid>/accumulators/jobs/<jobid>/vertices/<vertexid>/jobs/<jobid>/vertices/<vertexid>/subtasktimes/jobs/<jobid>/vertices/<vertexid>/taskmanagers/jobs/<jobid>/vertices/<vertexid>/accumulators/jobs/<jobid>/vertices/<vertexid>/subtasks/accumulators/jobs/<jobid>/vertices/<vertexid>/subtasks/<subtasknum>/jobs/<jobid>/vertices/<vertexid>/subtasks/<subtasknum>/attempts/<attempt>/jobs/<jobid>/vertices/<vertexid>/subtasks/<subtasknum>/attempts/<attempt>/accumulators/jobs/<jobid>/plan
13.3. 日志
所有的 Flink 进程都会创建一个进程中包含各种事件发生信息的日志文本文件,这些日志提供了对 Flink 内部工作原理的深度信息,并且可以被用来定位问题以及进行 debug。
log 文件可以通过 WebUI 界面的 Job/TaskManager 页面来访问。使用 资源框架 ,比如 YARN,可能会提供访问它们的其他方法。
Flink 的日志使用 SLF4J 日志接口,这允许你使用任何支持 SLF4J 的日志框架,而无需改变 Flink 的源码。
默认情况下,底层使用 Log4j 2 日志框架。
13.3.1. 配置 Log4j2
Log4j2 是使用配置文件指定的。
在 Flink 的使用中,该文件通常命名为 log4j.properties。我们使用 -Dlog4j.configurationFile= 参数将该文件的文件名和位置传递给 JVM。
如果启用了 Log4j 2,Flink 会自动将存放在 conf 目录的以下默认日志配置文件传递到容器中:
log4j-cli.properties:由 Flink 命令行客户端使用(例如flink run)log4j-session.properties:Flink 命令行客户端在启动 YARN 或 Kubernetes session 时使用(yarn-session.sh,kubernetes-session.sh)log4j.properties:作为 JobManager/TaskManager 日志配置使用。
Log4j 会定期浏览这些文件的更改,如果有需要,也会调整日志的行为。默认情况下,会定时 30 秒检查一次,可以通过 Log4j 配置文件中的 monitorInterval 来控制。
13.3.1.1. 与 Log4j1 的兼容性
Flink 附带了 Log4j API bridge,使得现有作业能够继续使用 log4j1 的接口。
如果你有基于 Log4j 的自定义配置文件或代码,请查看官方 Log4j 兼容性和迁移指南。
13.3.2. 配置 Log4j1
要将 Flink 与 Log4j1 一起使用,必须确保:
- Classpath 中不存在
org.apache.logging.log4j:log4j-core,org.apache.logging.log4j:log4j-slf4j-impl和org.apache.logging.log4j:log4j-1.2-api, - 且 Classpath 中存在
log4j:log4j,org.slf4j:slf4j-log4j12,org.apache.logging.log4j:log4j-to-slf4j和org.apache.logging.log4j:log4j-api。
在 IDE 中使用 log4j1,你必须在 pom 文件中使用上述 Classpath 中存在的 jars 依赖项替换 Classpath 中不存在的 jars 依赖项,并尽可能在传递依赖于 Classpath 中不存在的 jars 的依赖项上添加排除 Classpath 中不存在的 jars 配置。
对于 Flink 发行版,这意味着你必须
- 从
lib目录中移除log4j-core,log4j-slf4j-impl和log4j-1.2-apijars, - 向
lib目录中添加log4j,slf4j-log4j12和log4j-to-slf4jjars, - 用兼容的 Log4j1 版本替换
conf目录中的所有 log4j 配置文件。
13.3.3. 配置 logback
为了让 Flink 使用 logback 你必须确保:
- classpath 中没有
org.apache.logging.log4j:log4j-slf4j-impl - classpath 中有
ch.qos.logback:logback-core和ch.qos.logback:logback-classic
在 IDE 中,这意味着你必须在你的 pom 文件中替换这些依赖定义,而且有可能还需要增加一些必要的额外依赖。
对于 Flink 部署,这意味着你必须:
- 从
lib目录下移除log4j-slf4j-impljar 包 - 增加
logback-core和logback-classicjar 包到lib目录
如果启用了 logback,Flink 会自动传递 conf 目录中下面的这些 logback 配置文件:
logback-session.properties:启动 Kubernetes/Yarn session 集群时使用的命令行接口,比如:kubernetes-session.sh/yarn-session.sh。logback-console.properties:在前台运行 Job/TaskManager 时使用,比如:Kubernets。logback.xml:命令行接口和 Job/TaskManager 默认使用。
Logback 1.3.+ 要求 SLF4J 2,目前还不支持。
13.3.4. 开发人员的最佳实践
你可以通过调用 org.slf4j.LoggerFactory#LoggerFactory.getLogger ,并将你的 class 类作为参数来创建一个 SLF4J 日志对象。
我们强烈建议将该对象存储为一个 private static final 属性。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Foobar {
private static final Logger LOG = LoggerFactory.getLogger(Foobar.class);
public static void main(String[] args) {
LOG.info("Hello world!");
}
}
为了最大限度地利用 slf4j,建议使用其占位符机制。使用占位符可以避免不必要的字符串构造,以防日志级别设置得太高而不会记录消息。
占位符的语法如下:
LOG.info("This message contains {} placeholders. {}", 2, "Yippie");
占位符也可以和要记录的异常一起使用。
catch(Exception exception){
LOG.error("An {} occurred.", "error", exception);
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











