







1. 自定义拦截器实现说明
1. 实现interceptor接口,并实现其方法,接口完全限定名为:org.apache.flume.interceptor.Interceptor;
2. 自定义拦截器内部添加静态内部类,实现Builder接口,并实现其方法,接口完全限定名为:Interceptor.Builder
以下是最简单的代码示例(每个方法的作用都有注释说明):
package cn.com.bonc.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.List;
/**
* 自定义拦截器,实现Interceptor接口,并且实现其抽象方法
*/
public class CustomInterceptor implements Interceptor {
//打印日志,便于测试方法的执行顺序
private static final Logger logger = LoggerFactory.getLogger(CustomInterceptor.class);
//自定义拦截器参数,用来接收自定义拦截器flume配置参数
private static String param = "";
/**
* 拦截器构造方法,在自定义拦截器静态内部类的build方法中调用,用来创建自定义拦截器对象。
*/
public CustomInterceptor() {
logger.info("----------自定义拦截器构造方法执行");
}
/**
* 该方法用来初始化拦截器,在拦截器的构造方法执行之后执行,也就是创建完拦截器对象之后执行
*/
@Override
public void initialize() {
logger.info("----------自定义拦截器的initialize方法执行");
}
/**
* 用来处理每一个event对象,该方法不会被系统自动调用,一般在 List<Event> intercept(List<Event> events) 方法内部调用。
*
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
logger.info("----------intercept(Event event)方法执行,处理单个event");
logger.info("----------接收到的自定义拦截器参数值param值为:" + param);
/*
这里编写event的处理代码
*/
return event;
}
/**
* 用来处理一批event对象集合,集合大小与flume启动配置有关,和transactionCapacity大小保持一致。一般直接调用 Event intercept(Event event) 处理每一个event数据。
*
* @param events
* @return
*/
@Override
public List<Event> intercept(List<Event> events) {
logger.info("----------intercept(List<Event> events)方法执行");
/*
这里编写对于event对象集合的处理代码,一般都是遍历event的对象集合,对于每一个event对象,调用 Event intercept(Event event) 方法,然后根据返回值是否为null,
来将其添加到新的集合中。
*/
List<Event> results = new ArrayList<>();
Event event;
for (Event e : events) {
event = intercept(e);
if (event != null) {
results.add(event);
}
}
return results;
}
/**
* 该方法主要用来销毁拦截器对象值执行,一般是一些释放资源的处理
*/
@Override
public void close() {
logger.info("----------自定义拦截器close方法执行");
}
/**
* 通过该静态内部类来创建自定义对象供flume使用,实现Interceptor.Builder接口,并实现其抽象方法
*/
public static class Builder implements Interceptor.Builder {
/**
* 该方法主要用来返回创建的自定义类拦截器对象
*
* @return
*/
@Override
public Interceptor build() {
logger.info("----------build方法执行");
return new CustomInterceptor();
}
/**
* 用来接收flume配置自定义拦截器参数
*
* @param context 通过该对象可以获取flume配置自定义拦截器的参数
*/
@Override
public void configure(Context context) {
logger.info("----------configure方法执行");
/*
通过调用context对象的getString方法来获取flume配置自定义拦截器的参数,方法参数要和自定义拦截器配置中的参数保持一致+
*/
param = context.getString("param");
}
}
}3. 将自定义拦截器打包,上传,我使用的是CDH,自定义拦截器jar包位置为:/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/flume-ng/lib,如果使用的原生的flume,大家自行查询自定义拦截器jar包存放位置即可。
4. 编写flume配置文件,下面是示例代码:
#agent
customInterceptor.sources=r1
customInterceptor.channels=c1
customInterceptor.sinks=s1
#source
customInterceptor.sources.r1.type=spooldir
customInterceptor.sources.r1.spoolDir=/home/jumpserver/flume/data1
customInterceptor.sources.r1.consumeOrder=youngest
customInterceptor.sources.r1.recursiveDirectorySearch=false
customInterceptor.sources.r1.deletePolicy=immediate
customInterceptor.sources.r1.pollDelay=500
#source1-interceptor
customInterceptor.sources.r1.interceptors=i1
customInterceptor.sources.r1.interceptors.i1.type=cn.com.bonc.interceptor.CustomInterceptor$Builder
customInterceptor.sources.r1.interceptors.i1.param=parameter
#channe1
customInterceptor.channels.c1.type=memory
customInterceptor.channels.c1.capacity=1000
customInterceptor.channels.c1.transactionCapacity=100
#sink
customInterceptor.sinks.s1.type=logger
#package
customInterceptor.sources.r1.channels=c1
customInterceptor.sinks.s1.channel=c1注意配置自定义拦截器部分。i1.param这儿的param要和自定义拦截器代码中的context .getString(“param”)参数保持一致!
4. 启动flume
命令:flume-ng agent -c ./ -f customInterceptor.conf -n customInterceptor | grep INFO
为了查看方便,我只过滤出了INFO级别的信息。
结果:
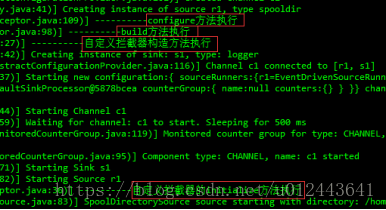
从运行结果中可以看出每个方法的执行顺序。
现在我往/home/jumpserver/flume/data1目录中拷贝文件,然后flume就会处理该文件:
data.txt内容为:
this is a test string.
cp data.txt flume/data1/
结果: 从运行结果中可以看出每个方法的执行顺序。
从运行结果中可以看出每个方法的执行顺序。
现在重新运行flume,这次打印出所有的日志,以此来查看正常结束(Ctrl+C或者是kill -2)flume时的运行结果: 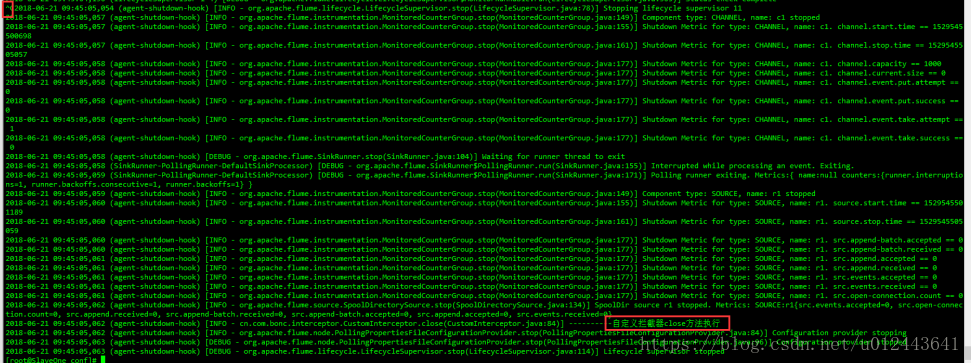
从运行结果中可以看出flume正常结束时,close方法被调用了。
2. 功能说明
这两天公司给了我个需求:监视服务器(linux系统)的一个本地目录,不断有人往里面上传新的文件,有五分钟一个文件的,两分钟一个文件的,一分钟一个文件的,30秒一个文件的,还有不定时一个文件的,而且会有同名文件上传(重点)!!!要求我对于不同的文件,按照文件名来区分,将杂乱的文件内容处理完之后,将其上传至不同的HDFS目录下,以便于Hive表管理(重点)!!!。实现的具体多个功能如下:
1. spooldir处理同名文件。
2. 自定义过滤器处理杂乱的文件内容,去除多余的行,并修改每行内容,同理,也可增加行。
3. 过滤器接收自定义参数来处理不用的文件名,HDFS sink通过匹配文件名(最好的方法为正则匹配)来将不同文件保存至不同的HDFS路径下(按天动态分区)。
3. 功能实现思路(与上面问题一一对应)
1. spooldir默认是将处理完的新文件重命名,原文件名添加后缀名.COMPLETE,但是遇到同名文件之后,除了完同名文件,在重命名时,发现已经有相同文件名的文件存在,此时flume会报错,然后停止监控线程(此线程默认500毫秒扫描一次目录,检查是否有新文件),目录中再有新的文件,也不会被处理。
处理方法为:设置spooldir文件删除策略为:data.sources.r1.deletePolicy=immediate
2. spooldir默认按行读取文件内容,因此每个event body中的内容都是一行文件内容。要实现减少或者是增加event的效果(也即是删除或者是增加文件内容行数),就要在public Event intercept(Event event)动手了。删除event的话,只需要在该方法中返回null即可;如果想要增加event,可以自定义一个处理方法,接受Event event参数,返回List<Event>,也就是:public List<Event> intercept2(Event event)。
3. 在自定义拦截器中添加静态变量,然后在静态内部类中的configure方法中通过Context context参数获取参数值,然后赋值给自定义静态变量。
4. 功能代码演示
1. 配置代码:
customInterceptor.sources.r1.type=spooldir
customInterceptor.sources.r1.spoolDir=/home/jumpserver/flume/data1
customInterceptor.sources.r1.consumeOrder=youngest
customInterceptor.sources.r1.recursiveDirectorySearch=false
customInterceptor.sources.r1.deletePolicy=immediate
customInterceptor.sources.r1.pollDelay=5002. 去除文件头,并且将文件头信息加入每行数据的代码:
被处理文件原始内容:
1111111;唐口煤矿5306工作面;KJ615|
2018-03-20 07:14:29|
13;4.66~
6;4.23~||
被处理之后的内容;
1111111,唐口煤矿5306工作面,KJ615,2018-03-20 07:14:29,13,4.66
1111111,唐口煤矿5306工作面,KJ615,2018-03-20 07:14:29,6,4.23
自定义拦截器代码:
package cn.com.bonc.interceptor;
import cn.com.bonc.interceptor.utils.CustomTime;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.List;
/**
* 应力监测数据过滤器,主要用来处理应力监测数据文件:<br>
* 1. 将文件头数据去掉,然后添加到每行数据中;<br>
* 2. 实现去掉空行数据功能;
*/
public class StressMonitorData implements Interceptor {
//用于输出日志
private Logger logger = LoggerFactory.getLogger(StressMonitorData.class);
//用于将日志输出至单独的日志文件中去
private Logger logger2 = LoggerFactory.getLogger("logger2");
//文件有两行表头,第一行三个信息,第二行一个信息
private String message11 = "";
private String message12 = "";
private String message13 = "";
private String message21 = "";
private String oldBody = "";
private String newBody = "";
private String currentFileName = "";
@Override
public void initialize() {
}
/**
* 读取event body内容,检查是否为表头<br>
* 如果为表头,则更新表头信息变量<br>
* 如果为记录数据,则对其进行拼接
*
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
String fileName = event.getHeaders().get("fileName");
//将当前处理的文件名组装为日志输出至日志文件中
if (!currentFileName.equals(fileName)) {
currentFileName = fileName;
logger2.info(CustomTime.getTime() + "------处理文件:" + currentFileName);
}
//清空body变量,将新的event body内容追加到body变量
oldBody = new String(event.getBody());
if (oldBody == "") {
//如果该行为空,则直接舍弃
return null;
}
String[] bodys = oldBody.split(";");
int length = bodys.length;
if (length == 3) {
logger.info("------接收到第一行文件头,内容为:" + oldBody);
//该event内容为文件第一行内容
message11 = bodys[0];
message12 = bodys[1];
message13 = bodys[2].split("\\|")[0];
return null;
} else if (length == 1) {
logger.info("------接收到第二行文件头,内容为:" + oldBody);
//该event内容为文件第二行内容
message21 = bodys[0].split("\\|")[0];
return null;
} else if (length == 2) {
logger.info("------接收到记录数据,内容为:" + oldBody);
//该event内容为文件记录数据,将文件头信息和实际数据进行拼接
newBody = message11 + "," + message12 + "," + message13 + "," + message21 + "," +
bodys[0] + "," + bodys[1].split("~")[0];
event.setBody(newBody.getBytes());
return event;
} else {
logger.info("------接收到脏数据,内容为:" + oldBody);
//在上述三种情况之外的,一律按照脏数据处理,直接舍弃
return null;
}
}
@Override
public List<Event> intercept(List<Event> events) {
int i = 1;
for (Event e : events) {
logger.info("------原始数据第" + (i++) + "行内容为:" + new String(e.getBody()));
}
List<Event> result = new ArrayList<Event>();
Event event;
for (Event e : events) {
event = intercept(e);
if (event != null) {
result.add(event);
}
}
i = 1;
for (Event e : result) {
logger.info("------结果数据第" + (i++) + "行内容为:" + new String(e.getBody()));
}
return result;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
private Logger logger = LoggerFactory.getLogger(Builder.class);
//使用Builder初始化自定义Interceptor
@Override
public Interceptor build() {
logger.info("------初始化StressMonitorData拦截器");
return new StressMonitorData();
}
@Override
public void configure(Context context) {
}
}
}p log4j.properties文件内容为:lo
log4j.rootLogger = INFO, out
log4j.appender.out = org.apache.log4j.ConsoleAppender
log4j.appender.out.layout = org.apache.log4j.PatternLayout
log4j.appender.out.layout.ConversionPattern = %d (%t) [%p - %l] %m%n
log4j.logger.org.apache.flume = DEBUG
log4j.logger.logger2=debug,appender2
log4j.appender.appender2=org.apache.log4j.FileAppender
log4j.appender.appender2.File=handelFile.log
log4j.appender.appender2.layout=org.apache.log4j.TTCCLayout上面的logger2可以将日志输出至指定的日志文件中,已便于将不同的日志输出至不同的文件中保存,方便后续分析。logger2初始化代码:
private Logger logger2 = LoggerFactory.getLogger("logger2");为了方便测试,我打印了很多log日志,在实际生产环境下,可以去掉不必要的日志。
3. 这个功能我直接演示正则表达式,这是最好的方法,但也是比较难得方法,毕竟正则表达式能看懂,但不一定会写。
自定义过滤器代码示例:
package cn.com.bonc.interceptor;
import cn.com.bonc.interceptor.utils.CustomTime;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* 获取拦截器正则表达式参数,用来匹配正则表达式来修改文件名:<br>
* 1. 匹配正则表达式,修改event头信息中的文件名;<br>
* 2. 去除文件数据中的空行数据;
*/
public class HeaderParamRegular implements Interceptor {
//拦截器参数,文件名要匹配的正则表达式
private static String regex;
//拦截器参数,文件名匹配之后要修改的字符串
private static String replace;
private String currentFileName = "";
private Logger logger = LoggerFactory.getLogger(HeaderParamRegular.class);
//该logger用于将日志输出至指定的文件中
private Logger logger2 = LoggerFactory.getLogger("logger2");
@Override
public void initialize() {
}
/**
* 处理文件头中的文件名信息
*
* @param event event对象
* @return 处理完之后的event对象
*/
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String fileName = headers.get("fileName");
//将当前处理的文件名组合为日志输出至单独的日志文件中去
if (!currentFileName.equals(fileName)){
currentFileName = fileName;
logger2.info(CustomTime.getTime() + "------处理文件:" + currentFileName);
if ("".equals(new String(event.getBody()))){
return null;
}
}
String[] regexs = regex.split(",");
int length = regexs.length;
String[] replaces = replace.split(",");
boolean flag = false;
if (fileName != null) {
logger.info("------读取到event header中的fileName信息为:" + fileName);
for (int i = 0; i < length; i++) {
if (fileName.matches(regexs[i])) {
headers.put("fileName", replaces[i]);
event.setHeaders(headers);
flag = true;
break;
}
}
if (!flag) {
logger.info("------fileName未匹配到合适的regex信息,event头中文件名保持不变。");
}
} else {
logger.info("------event header中没有fileName信息");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
List<Event> results = new ArrayList<>();
Event event;
for (Event e : events) {
event = intercept(e);
if (event != null) {
results.add(event);
}
}
return results;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
private Logger logger = LoggerFactory.getLogger(HeaderParamRegular.class);
//使用Builder初始化自定义Interceptor
@Override
public Interceptor build() {
logger.info("------初始化HeaderParam拦截器");
return new HeaderParamRegular();
}
//通过该方法中的context对象,可以获取到flume配置文件中配置的参数值,并且先于build方法执行!!!
@Override
public void configure(Context context) {
regex = context.getString("regex");
replace = context.getString("replace");
logger.info("------获取到拦截器参数pattern为:" + regex);
logger.info("------获取到拦截器参数replace为:" + replace);
}
}
}flume配置代码示例:
#source直接删除原始文件,解决重名问题
#agent
test.sources=r1
test.channels=c1
test.sinks=s1
#source
test.sources.r1.type=spooldir
test.sources.r1.spoolDir=/home/jumpserver/flume/data
test.sources.r1.consumeOrder=youngest
test.sources.r1.recursiveDirectorySearch=true
test.sources.r1.deletePolicy=immediate
test.sources.r1.pollDelay=500
test.sources.r1.basenameHeader=true
test.sources.r1.basenameHeaderKey=fileName
#source-interceptor
test.sources.r1.interceptors=i1
test.sources.r1.interceptors.i1.type=cn.com.bonc.interceptor.HeaderParamRegular$Builder
test.sources.r1.interceptors.i1.regex=^test1_\\w+\\.txt$,^test2_\\w+\\.txt$
test.sources.r1.interceptors.i1.replace=test1,test2
#channel
test.channels.c1.type=memory
test.channels.c1.capacity=1000
test.channels.c1.transactionCapacity=100
#sink
test.sinks.s1.type=logger
#package
test.sources.r1.channels=c1
test.sinks.s1.channel=c1该自定义拦截器对文件名进行修改,根据regex和replace参数值,一一对应。如果文件名匹配上了regex中的第一个正则表达式,则将其改为replace中的第一个字符串;以此类推。自定义拦截器代码以及flume配置文件代码自行查看。
直接运行,然后往/home/jumpserver/flume/data目录中拷贝文件,观察运行结果;

上图显示了将要拷贝的两个文件的实际内容和文件名。

上图为flume启动运行结果。

上图为往/home/jumpserver/flume/data目录中拷贝文件。 
上图为flume自定义过滤器处理结果,可以看到自定义过滤器已经将event头信息中的文件名根据正则表达式匹配将其改为我们需要的文件名。

上图为往/home/jumpserver/flume/data目录中拷贝文件,这次拷贝的文件,文件名已经发生了变化,文件内容也不同。 
上图为flume自定义过滤器处理结果,可以看到自定义过滤器已经将event头信息中的文件名根据正则表达式匹配将其改为我们需要的文件名。
PS:
该自定义拦截器的flume配置,我只是将处理结果打印出来了,并没有按照不同的文件名将其输出至不同的HDFS路径或者是其他类型sink不同的路径,大家可以参考flume官网文档说明,具体配置selector=multiplexing即可。
5. 上点干货
flume启动命令:
flume-ng agent -c ./ -f test.conf -n test -Dflume.monitoring.type=http -Dflume.monitoring.port=65000
flume关闭命令:
ps -x | grep 65000 | grep -v grep| cut -d " " -f 1 | xargs kill -2
这样开启和关闭flume,可以通过端口号来区分一台机器上启动的多个flume agent示例,十分方便。
具体都是什么意思,大家自己百度即可。


















 1895
1895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











