







一、主要思想
本文的主要思想首先采用Selective Search for Object Recognition论文的方法对每张图像分块得到多个个Region proposals,然后对每个Region proposal提取CNN特征,在采用线性svm进行分类,在VOC2012上面达到了 53.3%的mAP。
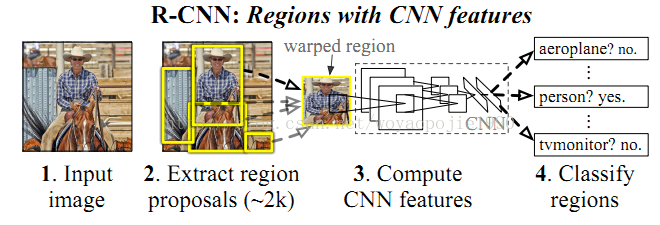
二、Object detection with R-CNN
1、模型框架
(1)获取Region proposals
采用Selective Search for Object Recognition论文的方法的快速模式获得。
(2)特征提取
采用开源代码caffe(他们是一个研究机构的)提取CNN特征,采用warp的方式把所有图像resize到227*227,因为caffe的输入图像的尺寸是固定的。

(3)分类器
采用线性SVM建立二分分类器。
2、训练
(1)监督的方式的预训练
采用caffe程序在ILSVRC 2012进行预训练,这个可以学习到大规模的数据集的基本特征,将这些参数作为调优的初始画参数,已解决深度学习中针对特征任务数据量小的问题。
(2)针对特定任务的调优
用Region proposals作为训练集,把和ground-truth box的IoU大于0.5的作为正样本,其余作为负样本;每个Region proposal,resize到227*227;caffe的构架不用变,只需要将最后一层的1000类输出改为21类(20类+1类背景),同时把第八层的相应名字修改了(随便取);以0.001的学习率开始SGD,每个min-batch由32个正样本窗口和96的背景窗口组成的128个Region proposals,这样做的目的是为了平衡正负样本的差距问题,因为Selective Search产生的负样本非常多。
(3)训练Object分类器
由于正负样本的数量极多,并且比例严重失衡,正样本少,负样本多。正对这个问题采用standard hard negative mining method训练二分类器。初始化的时候,选择ground-truth box的样本作为正样本,把与ground-truth box的IoU小于0.3的作为负样本,采用线性SVM更新模型。
三、实验结果
1、Detection average precision (%) on VOC 2010 test.

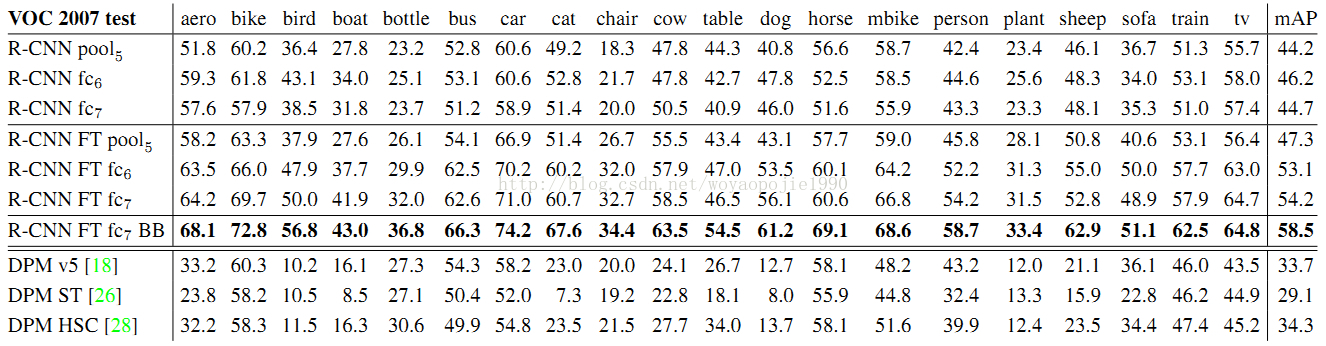
2、Detection average precision (%) on VOC 2007 test
四、总结
我这里主要是描述了Detection的工作,文章里面还有很多知识点,比如Visualization, ablation, and modes of error,Bounding box regression,Semantic segmentation等,这里不再详解,可以参考论文理解。本文的方法的主要框架思路还是很明晰,对每个小框提取CNN特征,解决多标签问题。不过这种方法需要花费大量的时间在实际应用中可能现实,不过有更快速的方法已经提出,可以参考我的博客《CNN: Single-label to Multi-label》。之所以后详解这篇论文的代码是开源的,同时我也刚把这篇论文应用到自己的项目当中花费了大量时间,结果还没有出来。而这篇《CNN: Single-label to Multi-label》的代码还没有公布,本人的能力有限还没有实现。















 2441
2441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









