






jobserver在运行用户的作业时,需要提供相关的监控信息给用户,包括作业运行进度、各个阶段的运行诊断、节点的信息等。
一 日志展示
spark执行任务时按照宽窄依赖将任务划分为不同的stage,每个stage包含多个task,在此以stage和task的完成情况展示任务执行进度。spark提供了SparkListener抽象类,通过继承该类并且实现相关的抽象方法即可获取相关的执行信息。SparkListener的定义如下:
abstract class SparkListener extends SparkListenerInterface {
override def onStageCompleted(stageCompleted: SparkListenerStageCompleted): Unit = { }
override def onStageSubmitted(stageSubmitted: SparkListenerStageSubmitted): Unit = { }
override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = { }
override def onTaskGettingResult(taskGettingResult: SparkListenerTaskGettingResult): Unit = { }
override def onTaskEnd(taskEnd: SparkListenerTaskEnd): Unit = { }
override def onJobStart(jobStart: SparkListenerJobStart): Unit = { }
override def onJobEnd(jobEnd: SparkListenerJobEnd): Unit = { }
override def onEnvironmentUpdate(environmentUpdate: SparkListenerEnvironmentUpdate): Unit = { }
override def onBlockManagerAdded(blockManagerAdded: SparkListenerBlockManagerAdded): Unit = { }
override def onBlockManagerRemoved(
blockManagerRemoved: SparkListenerBlockManagerRemoved): Unit = { }
override def onUnpersistRDD(unpersistRDD: SparkListenerUnpersistRDD): Unit = { }
override def onApplicationStart(applicationStart: SparkListenerApplicationStart): Unit = { }
override def onApplicationEnd(applicationEnd: SparkListenerApplicationEnd): Unit = { }
override def onExecutorMetricsUpdate(
executorMetricsUpdate: SparkListenerExecutorMetricsUpdate): Unit = { }
override def onExecutorAdded(executorAdded: SparkListenerExecutorAdded): Unit = { }
override def onExecutorRemoved(executorRemoved: SparkListenerExecutorRemoved): Unit = { }
override def onExecutorBlacklisted(
executorBlacklisted: SparkListenerExecutorBlacklisted): Unit = { }
override def onExecutorUnblacklisted(
executorUnblacklisted: SparkListenerExecutorUnblacklisted): Unit = { }
override def onNodeBlacklisted(
nodeBlacklisted: SparkListenerNodeBlacklisted): Unit = { }
override def onNodeUnblacklisted(
nodeUnblacklisted: SparkListenerNodeUnblacklisted): Unit = { }
override def onBlockUpdated(blockUpdated: SparkListenerBlockUpdated): Unit = { }
override def onOtherEvent(event: SparkListenerEvent): Unit = { }
}通过该类的定义可以看见,类中的很多方法都是对spark执行状态的监听,包括onStageSubmitted、onStageCompleted、
onTaskStart、onTaskEnd等,实现这些方法,可以在stage和task完成时得到通知,用户得到的日志格式如下:
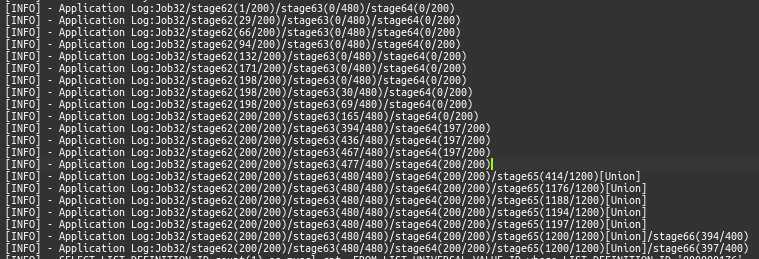
每个stage包含多个task,通过task的完成情况实时展现作业完成进度。
二 作业诊断
sparkListener提供了对stage和task的细粒度监控,应用程序可以获取到每个task的执行时间、输入数据大小、shuffle数据大小等,基于这些信息可以对stage的执行情况进行诊断,包括是否存在数据倾斜的情况、是否存在长尾task情况等。前端的UI汇总了各个stage的信息已经诊断信息等,如下图所示:

三 executor信息获取
由于executor是启在其它节点上,在driver端不能直接获取到相关信息,在此利用spark的metrics机制实现对executor所在节点的监控。spark metrics系统支持Sink和Source两种,其中Sink指定metrics信息发送到哪里,一个instance可以设置多个Sink,而Source指定信息的来源,这里采用JvmSource,它收集低级别的状态信息。
自定义的Sink信息如下:
class JobServerSink(val property: Properties, val registry: MetricRegistry,
securityMgr: SecurityManager) extends Sink{
val SERVER_KEY_PERIOD = "period"
val SERVER_KEY_UNIT = "unit"
val SERVER_KEY_URL = "url"
val SERVER_DEFAULT_PERIOD = 10
val SERVER_DEFAULT_UNIT = "SECONDS"
val SERVER_DEFAULT_URL = "http://localhost:7002"
val pollPeriod = Option(property.getProperty(SERVER_KEY_PERIOD)) match {
case Some(s) => s.toInt
case None => SERVER_DEFAULT_PERIOD
}
val pollUnit: TimeUnit = Option(property.getProperty(SERVER_KEY_UNIT)) match {
case Some(s) => TimeUnit.valueOf(s.toUpperCase(Locale.ROOT))
case None => TimeUnit.valueOf(SERVER_DEFAULT_UNIT)
}
MetricsSystem.checkMinimalPollingPeriod(pollUnit, pollPeriod)
val pollURL = Option(property.getProperty(SERVER_KEY_URL)) match {
case Some(s) => s
case None => SERVER_DEFAULT_URL
}
val reporter = JobServerReport.forRegistry(registry)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.convertRatesTo(TimeUnit.SECONDS).build(pollURL)
override def start(): Unit = reporter.start(pollPeriod, pollUnit)
override def stop(): Unit = reporter.stop()
override def report(): Unit = reporter.report()
}为了使得配置生效,新建一个metrics.properties文件,内容如下:
executor.sink.server.class=org.apache.spark.metrics.sink.JobServerSink
executor.sink.server.period=5 //采集周期
executor.sink.server.unit=seconds //采集周期单位 秒
executor.sink.server.url = http://192.168.6.52:7002 //发送的driver地址
executor.source.jvm.class=org.apache.spark.metrics.source.JvmSource提交spark-submit时,添加参数--conf spark.metrics.conf=/home/admin/metrics.properties。这里的spark.metrics.conf指定的配置文件必须在本地,也就意味着必须把该文件拷贝到每个节点上,为了避免操作的繁琐,首先将配置文件拷贝到HDFS上,通过aspect拦截MetricsConfig的initialize方法,在加载该配置时,先从HDFS上下载到本地,再加载该文件。
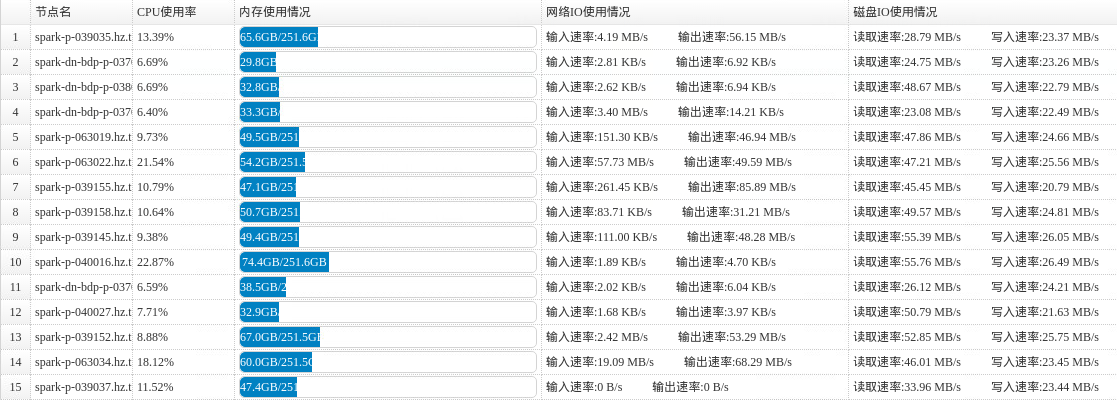
采集到的节点信息展示在前端,如图所示:















 5830
5830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









