依然使用上一篇文章的表tb_department.
这是tb_department表中各个部门的上下级关系:
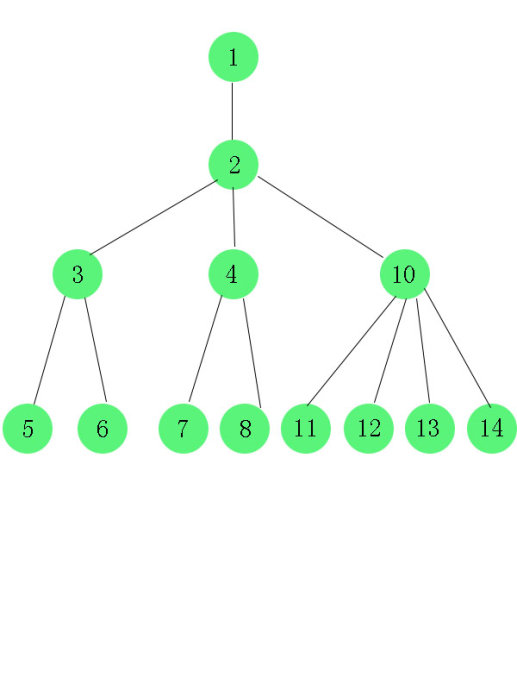
现在需要实现的效果是:给定一个部门id,查询该部门下最底级部门的id。
如给定部门id为3,那么输出5,6,给定部门id为1,输出5,6,7,8,11,12,13,14
首先定义递归查询的存储过程:findGridsByDepartmentId
CREATE DEFINER = 'root'@'localhost'
PROCEDURE findGridsByDepartmentId(IN departmentId BIGINT)
BEGIN
DECLARE done INTEGER DEFAULT 0;
DECLARE v_depId INTEGER DEFAULT -1;
DECLARE C_Dep CURSOR FOR SELECT d.id
FROM
tb_department d
WHERE
d.parent_seq_no = departmentId;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1;
SET @@max_sp_recursion_depth = 10;
OPEN C_Dep;
WHILE done = 0
DO
FETCH C_Dep INTO v_depId;
IF (v_depId = -1) THEN
INSERT INTO tmp_dep (depId) VALUES (departmentId);
ELSE
SET departmentId = v_depId;
CALL findGridsByDepartmentId(departmentId);
END IF;
END WHILE;
CLOSE C_Dep;
END
再定义执行递归操作的存储过程:findLastGridsByDepartmentId
CREATE DEFINER = 'root'@'localhost'
PROCEDURE findLastGridsByDepartmentId(IN departmentId BIGINT)
BEGIN
DROP TEMPORARY TABLE IF EXISTS tmp_dep;
CREATE TEMPORARY TABLE tmp_dep(
depId INTEGER
);
DELETE
FROM
tmp_dep;
CALL findGridsByDepartmentId(departmentId);
SELECT distinct depId
FROM
tmp_dep order by depId;
END
现在在mysql中创建好这两个存储过程,并且执行 call findLastGridsByDepartmentId(1)就会输出5,6,7,8,11,12,13,14。























 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









