







1.简述
TCP全称为Transmission Control Protocol,每一个IT人士对TCP都有一定了解。TCP协议属于底层协议,对于大部分研发人员来说,这是透明的,无需关心TCP的实现与细节。不过如果想做深入的性能优化,TCP是绕不过去的一环。
2.proc参数
BDP(Bandwidth-delay product,带宽延迟积)数据链路的容量与其端到端延迟的乘积。这个结果就是任意时刻处于在途未确认状态的最大数据量。发送端或接收端无论谁被迫频繁地停止等待之前分组的ACK,都会造成数据缺口,从而必然限制连接的最大吞吐量。无论实际或通告的带宽是多大,窗口过小都会限制连接的吞吐量。
所有的TCP/IP调优参数都位于/proc/sys/net/目录:
| 目录 | 默认值 | 含义 |
|---|---|---|
| /proc/sys/net/core/rmem_default | “110592” | 定义默认的接收窗口大小;对于更大的 BDP 来说,这个大小也应该更大。 |
| /proc/sys/net/core/rmem_max | “110592” | 定义接收窗口的最大大小;对于更大的 BDP 来说,这个大小也应该更大。 |
| /proc/sys/net/core/wmem_default | “110592” | 定义默认的发送窗口大小;对于更大的 BDP 来说,这个大小也应该更大。 |
| /proc/sys/net/core/wmem_max | “110592” | 定义发送窗口的最大大小;对于更大的 BDP 来说,这个大小也应该更大。 |
| /proc/sys/net/ipv4/tcp_window_scaling | “1” | 启用 RFC 1323 定义的 window scaling;要支持超过 64KB 的窗口,必须启用该值。 |
| /proc/sys/net/ipv4/tcp_sack | “1” | 启用有选择的应答(Selective Acknowledgment),这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段);(对于广域网通信来说)这个选项应该启用,但是这会增加对 CPU 的占用。 |
| /proc/sys/net/ipv4/tcp_fack | “1” | 启用转发应答(Forward Acknowledgment),这可以进行有选择应答(SACK)从而减少拥塞情况的发生;这个选项也应该启用。 |
| /proc/sys/net/ipv4/tcp_timestamps | “1” | 以一种比重发超时更精确的方法(请参阅 RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项。 |
| /proc/sys/net/ipv4/tcp_mem | “24576 32768 49152” | 确定 TCP 栈应该如何反映内存使用;每个值的单位都是内存页(通常是 4KB)。第一个值是内存使用的下限。第二个值是内存压力模式开始对缓冲区使用应用压力的上限。第三个值是内存上限。在这个层次上可以将报文丢弃,从而减少对内存的使用。对于较大的 BDP 可以增大这些值(但是要记住,其单位是内存页,而不是字节)。 |
| /proc/sys/net/ipv4/tcp_wmem | “4096 16384 131072” | 为自动调优定义每个 socket 使用的内存。第一个值是为 socket 的发送缓冲区分配的最少字节数。第二个值是默认值(该值会被 wmem_default 覆盖),缓冲区在系统负载不重的情况下可以增长到这个值。第三个值是发送缓冲区空间的最大字节数(该值会被 wmem_max 覆盖)。 |
| /proc/sys/net/ipv4/tcp_rmem | “4096 87380 174760” | 与 tcp_wmem 类似,不过它表示的是为自动调优所使用的接收缓冲区的值。 |
| /proc/sys/net/ipv4/tcp_low_latency | “0” | 允许 TCP/IP 栈适应在高吞吐量情况下低延时的情况;这个选项应该禁用。 |
| /proc/sys/net/ipv4/tcp_westwood | “0” | 启用发送者端的拥塞控制算法,它可以维护对吞吐量的评估,并试图对带宽的整体利用情况进行优化;对于 WAN 通信来说应该启用这个选项。 |
| /proc/sys/net/ipv4/tcp_bic | “1” | 为快速长距离网络启用 Binary Increase Congestion;这样可以更好地利用以 GB 速度进行操作的链接;对于 WAN 通信应该启用这个选项。 |
| /proc/sys/net/core/netdev_max_backlog | 1000 | 接收队列 |
3.MTU调优
如果TCP连接的两端的网卡和网络接口层都支持大的 MTU,那么我们就可以配置网络,使用更大的mtu大小,也不会导致被 切割重新组装发送。
#配置命令:
ifconfig eth0 mtu 9000
其实 除了 MTU ,还有一个 MSS(max segement size). MTU是网络接口层的限制,而MSS是传输层的概念。其实这就是 TCP分段 和 IP分片 。MSS值是TCP协议实现的时候根据MTU换算而得(减掉Header)。当一个连接建立时, 连接的双方都要通告各自的MSS值。
TCP分段发生在传输层,分段的依据是MSS, TCP分段是在传输层完成,并在传输层进行重组IP分片发生在网络层,分片的依据是MTU, IP分片由网络层完成,也在网络层进行重组。其实还有一个 window size, 但是它是完全不同的东西:
winsize is used for flow control. Each time the source can send out a number of segments without ACKs. You should check “sliding- window” to understand this. The value of win is dynamic since it’s related to the remaining buffer size.
(参见:http://www.newsmth.net/nForum/#!article/CompNetResearch/4555)
4.慢启动与拥塞避免
接收窗口对性能很重要,但拥塞窗口比接收窗口更重要。客户端与服务器之间最大可以传输(未经ACK确认的)数据量取rwnd和cwnd变量中的最小值,而一开始的cwnd很小,通过慢启动算法不断增大。
慢启动和拥塞避免的算法有很多,这里使用Tahoe版本的TCP版本进行展示,这个也是带有拥塞控制功能的第一个TCP版本,使用的拥塞避免算法为AIMD(Multiplicative Decrease and Additive Increase,倍减加增)。
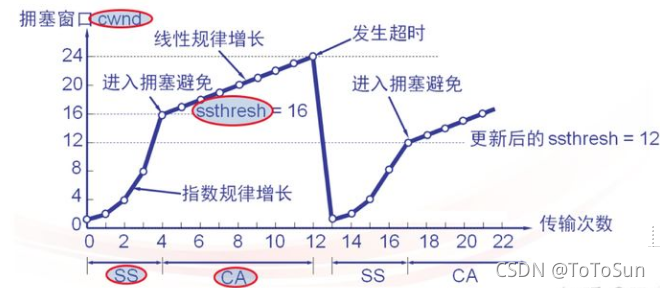
为了防止cwnd增加过快而导致网络拥塞,所以需要设置一个慢开始门限ssthresh状态变量(我也不知道这个到底是什么,就认为他是一个拥塞控制的标识),它的用法:
1. 当cwnd < ssthresh,使用慢启动算法,
2. 当cwnd > ssthresh,使用拥塞控制算法,停用慢启动算法。
3. 当cwnd = ssthresh,这两个算法都可以。
5.实验
/**************************************************************************/
/** TCP 优化方法总结(40Gb协商速率) ******/
/** 上位机:win10 网络小助手 ******/
/** 下位机:Ubuntu 麒麟系统 ******/
/** 原始下载速度:160MB ******/
/** 优化下载速度:380MB ******/
/**************************************************************************/
1. echo 4096 87380 16777216 >/proc/sys/net/ipv4/tcp_wmem
cat /proc/sys/net/ipv4/tcp_wmem
2. echo 4096 87380 16777216 >/proc/sys/net/ipv4/tcp_mem
cat /proc/sys/net/ipv4/tcp_mem
//3.增大MTU值至理论上限,大包传输,效率极大提高,需双边网卡都支持
sudo ifconfig enp45s0f0 9000
//4.窗口扩大因子(TCP Window Scaling)使能
echo 1 >/proc/sys/net/ipv4/tcp_window_scaling
//5.开启内核转发功能
echo 1 >/proc/sys/net/ipv4/ip_forward
//增大接收队列
6. echo 3000 >/proc/sys/net/core/netdev_max_backlog
//增大发送队列长度
ifconfig ens33 txqueuelen 4000
7. echo 16777216 >/proc/sys/net/core/wmem_max
echo 16777216 >/proc/sys/net/core/rmem_max
8. echo 16777216 >/proc/sys/net/core/wmem_default
//9.SYN队列长度
echo 8192 >/proc/sys/net/ipv4/tcp_max_syn_backlog
//10.禁止nagle算法,有需要发送的就立即发送
setsockopt(fd, IPPROTO_TCP, TCP_NODELAY, (char *)&no_delay, len);
//11.最少次调用send,write函数
//12.取消延迟确认
setsockopt(fd, IPPROTO_TCP, TCP_QUICKACK, (int[]){1}, sizeof(int));
13.最大网络吞吐(TCP窗口大小)=网络带宽 x RTT延迟,TCP每秒吞吐量(bits)=TCP窗口大小(bits)/延迟(秒)【RTT】
windows系统一般的窗口大小为64K,网络延迟为150ms。则每秒吞吐量=(1024*64)/0.15/1024/1024=0.41MB/s
iperf:
linux
sudo ./iperf3 -s -p 5202
window
>iperf3.exe -c 192.168.4.56 -p 5202 -P 4 -w 256KB
6.基于 OS 内核的数据传输有什么弊端?
-
1、中断处理:当网络中大量数据包到来时,会产生频繁的硬件中断请求,这些硬件中断可以打断之前较低优先级的软中断或者系统调用的执行过程,如果这种打断频繁的话,将会产生较高的性能开销。
-
2、内存拷贝:正常情况下,一个网络数据包从网卡到应用程序需要经过如下的过程:数据从网卡通过 DMA 等方式传到内核开辟的缓冲区,然后从内核空间拷贝到用户态空间,在 Linux 内核协议栈中,这个耗时操作甚至占到了数据包整个处理流程的 57.1%。
-
3、上下文切换:频繁到达的硬件中断和软中断都可能随时抢占系统调用的运行,这会产生大量的上下文切换开销。另外,在基于多线程的服务器设计框架中,线程间的调度也会产生频繁的上下文切换开销,同样,锁竞争的耗能也是一个非常严重的问题。
-
4、局部性失效:如今主流的处理器都是多个核心的,这意味着一个数据包的处理可能跨多个 CPU 核心,比如一个数据包可能中断在 cpu0,内核态处理在 cpu1,用户态处理在 cpu2,这样跨多个核心,容易造成 CPU 缓存失效,造成局部性失效。如果是 NUMA 架构,更会造成跨 NUMA 访问内存,性能受到很大影响。
-
5、内存管理:传统服务器内存页为 4K,为了提高内存的访问速度,避免 cache miss,可以增加 cache 中映射表的条目,但这又会影响 CPU 的检索效率。
综合以上问题,可以看出内核本身就是一个非常大的瓶颈所在。那很明显解决方案就是想办法绕过内核。
7.解决方案探讨
- 1、控制层和数据层分离:将数据包处理、内存管理、处理器调度等任务转移到用户空间去完成,而内核仅仅负责部分控制指令的处理。这样就不存在上述所说的系统中断、上下文切换、系统调用、系统调度等等问题。
- 2、多核技术:使用多核编程技术代替多线程技术,并设置 CPU 的亲和性,将线程和 CPU 核进行一比一绑定,减少彼此之间调度切换。
- 3、NUMA 亲和性:针对 NUMA 系统,尽量使 CPU 核使用所在 NUMA 节点的内存,避免跨内存访问。
- 4、大页内存:使用大页内存代替普通的内存,减少 cache-miss。
- 5、无锁技术:采用无锁技术解决资源竞争问题。
经研究,目前业内已经出现了很多优秀的集成了上述技术方案的高性能网络数据处理框架,如 6wind、Windriver、Netmap、DPDK 等,其中,Intel 的 DPDK 在众多方案脱颖而出,一骑绝尘。

8.加入讨论

7.参考
- https://www.cnblogs.com/digdeep/p/4869010.html
- https://zhuanlan.zhihu.com/p/170582219?utm_oi=1271842848443461632
- https://blog.csdn.net/dog250/article/details/51439747
- https://blog.csdn.net/weixin_39712016/article/details/111108566














 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









