









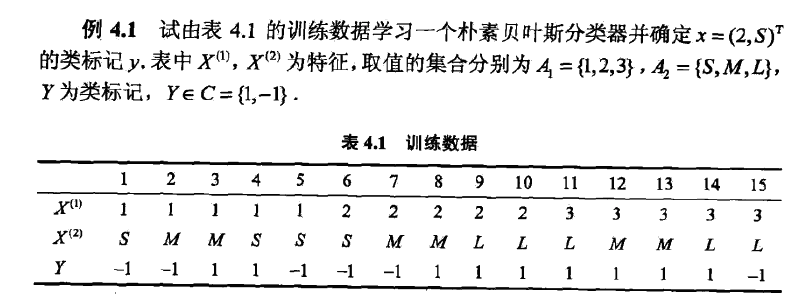
通过Python实现李航的朴素贝叶斯一章的例题。
from numpy import *
def loadDataSet():
postingList = [[1, 'S'],
[1, 'M'],
[1, 'M'],
[1, 'S'],
[1, 'S'],
[2, 'S'],
[2, 'M'],
[2, 'M'],
[2, 'L'],
[2, 'L'],
[3, 'L'],
[3, 'M'],
[3, 'M'],
[3, 'L'],
[3, 'L']]
classVec = [-1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, -1]
return postingList, classVec
def calProb(featVec, dataSet):
x1Labels = [temp[0] for temp in dataSet]
x2Labels = [temp[1] for temp in dataSet]
x1Counts = {}; x2Counts = {}
for label in x1Labels:
if label not in x1Counts.keys():
x1Counts[label] = 0
x1Counts[label] += 1
for label in x2Labels:
if label not in x2Counts.keys():
x2Counts[label] = 0
x2Counts[label] += 1
pX1 = x1Counts[featVec[0]]/float(len(dataSet))
pX2 = x2Counts[featVec[1]]/float(len(dataSet))
return pX1*pX2
def naiveBayes(featVec):
trainingSet, labels = loadDataSet()
cateCounts = {}
for category in labels:
if category not in cateCounts.keys():
cateCounts[category] = 0
cateCounts[category] += 1
pPositive = cateCounts[1] / float(len(labels))
pNegative = 1 - pPositive
positiveMat = []; negativeMat = []
for i in range(len(trainingSet)):
if labels[i] == 1:
positiveMat.append(trainingSet[i])
else:
negativeMat.append(trainingSet[i])
posProb = calProb(featVec, positiveMat) * pPositive
print(posProb)
negProb = calProb(featVec, negativeMat) * pNegative
print(negProb)
if posProb >= negProb:
print('the category is 1')
else:
print('the category is -1')
naiveBayes([2, 'S'])上面的代码采用极大似然估计是信了朴素贝叶斯方法,但是如果出现要估计的概率值为0的情况,结果就会受到影响,因此需要加入拉普拉斯平滑。

加入拉普拉斯平滑后的代码修改如下:
calProb()函数中pX1和pX2的计算修改为
pX1 = (x1Counts[featVec[0]]+1)/float(len(dataSet)+len(set(x1Labels)))
pX2 = (x2Counts[featVec[1]]+1)/float(len(dataSet)+len(set(x2Labels)))naiveBayes(featVec)函数中pPositive的计算修改为:
pPositive = (cateCounts[1]+1)/ float(len(labels)+len(set(labels)))同时,需要注意的是,如果在其他的贝叶斯计算中,因为条件独立性的假设存在,所以会出现多个概率值相乘的情况,导致最后的结果无限趋近于0,误差变大或者出现截断为0的情况。这时候可以考虑把概率值相乘改为使用log值相加,比如calProb()函数中添加一句p += log(px), px为每一个特征取值对应的条件概率,类似于源代码中的pX1和pX2。而在主函数中,posProb也应修改为posProb = calProb(featVec, positiveMat) + log(pPositive)。最后的判定条件不需要改变,仍为后验概率大的结果所属类别为正确类别。















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









