







Stable Diffusion条件控制生成
1. IP-Adapter
论文地址
解决问题:
如何将图片作为prompt输入网络,并无需更改开源模型参数
解决思路:
新增一个cross-attention layers,结果与text prompt的cross-attention layers结果相加后输入网络,只需要训练Wk, Wv两个参数
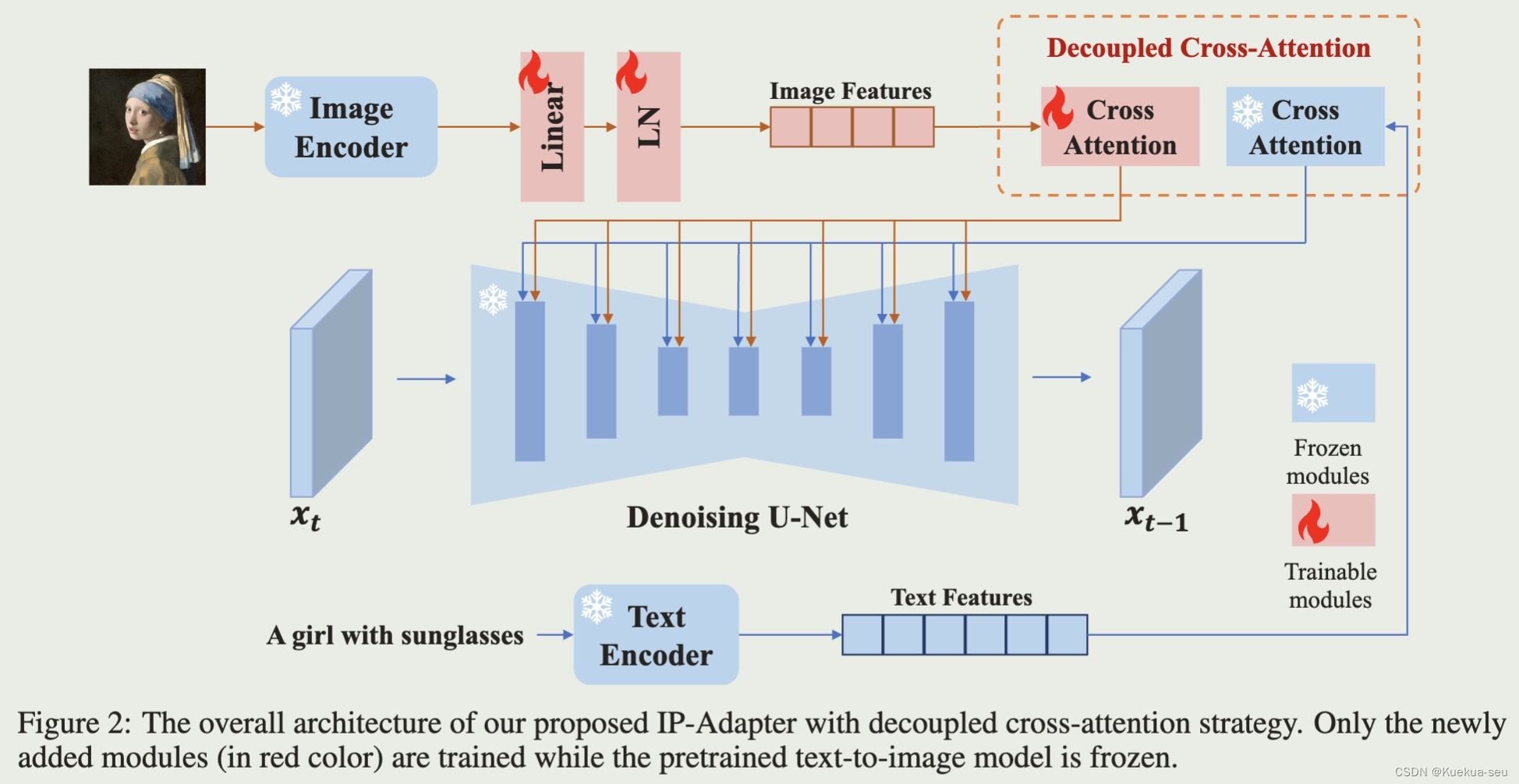
2. ControlNet
论文地址
解决问题:
如何快速高效的利用开源模型接受特定条件输入,适配特殊任务
解决思路:
新增网络:复制原UNet网络的encode和middle部分共13个网络blocks,将特定条件通过一个4层卷积构成的encode输入到那13网络中,13网络与原UNet通过zero-conv进行feature融合,训练时仅更新新增网络,原模型参数冻结,具体如下图所示:
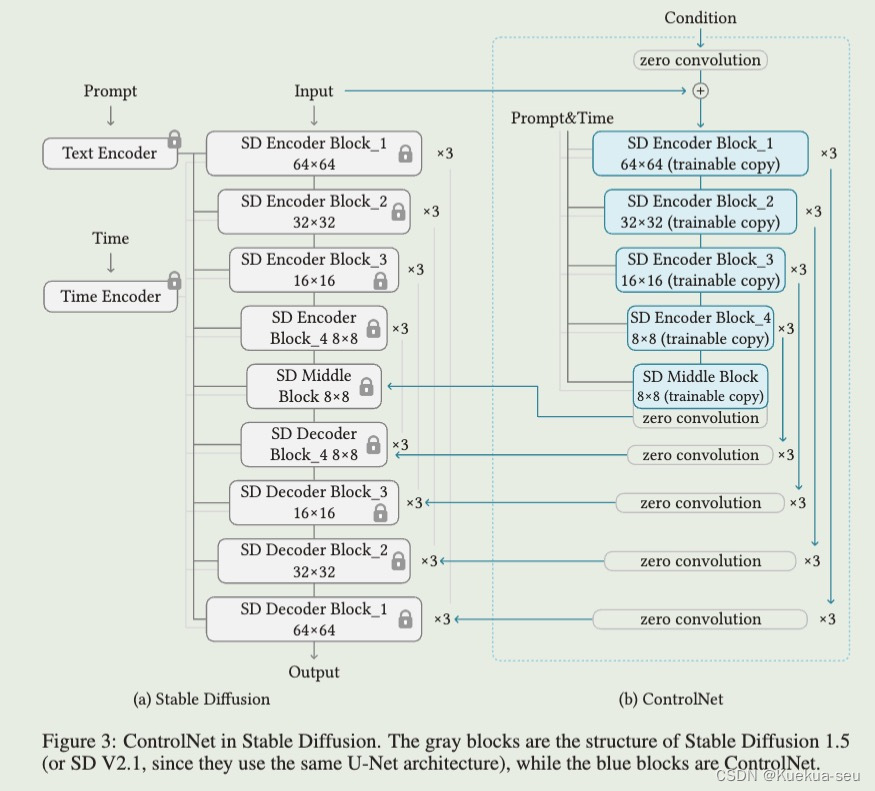
Tips:
1. 训练时随机去掉text,换成空字符输入,以增强网络多特殊条件的理解,并在应用时支持输出text为空的情形。

2. 当训练机器资源有限时,可以去掉网络decode的zero-conv连接,只保留中间层连接,可加速模型收敛,提高训练速度。最后再将去掉的zero-conv连接接上进行finetune即可

3. InstantID
论文地址
解决问题:
如何解决换脸过程中人脸ID得保持性,并与背景较好的融合
解决思路:
融合IP-A和controlNet,并使用insightface的antelopev2提取人脸特征,具体如下图所示:

Tips:
- clip提取image特征不能很好的保留细节和语义特征,不利于后续人脸ID的保持性,所以才用人脸识别模型提取人脸特征
- IdentityNet仅采用人脸五个点特征作为输入,既引入了空间信息,又避免过多原人脸信息的泄漏
- IdentityNet用ID embedding替代text prompts是为了让IdentityNet专注于人脸特征的表示,而不受非人脸的背景影响,因此在训练时也没有采用随机去掉text or image conditions的策略
- ID embedding可用多张参考图人脸特征平均计算得到,并且参考人脸数据较多时效果会更好
4. T2I-Adapter
论文地址
解决问题:
解决如何更好的挖掘文生图模型的生成能力,解决文字描述能力限制。
解决思路:
设计一个condition的encode网络,将condition信息依次加入UNet的encode网络的四层block中,与controlNet不同的是:1. condition的encode网络是独立设计的,controlNet是复制Unet的encode和mid部分 2. condition信息是加入encode环节,controlNet是加入middle和decode环节 3. condition信息是直接和UNet参数相加,controlNet是通过zero-conv连接:
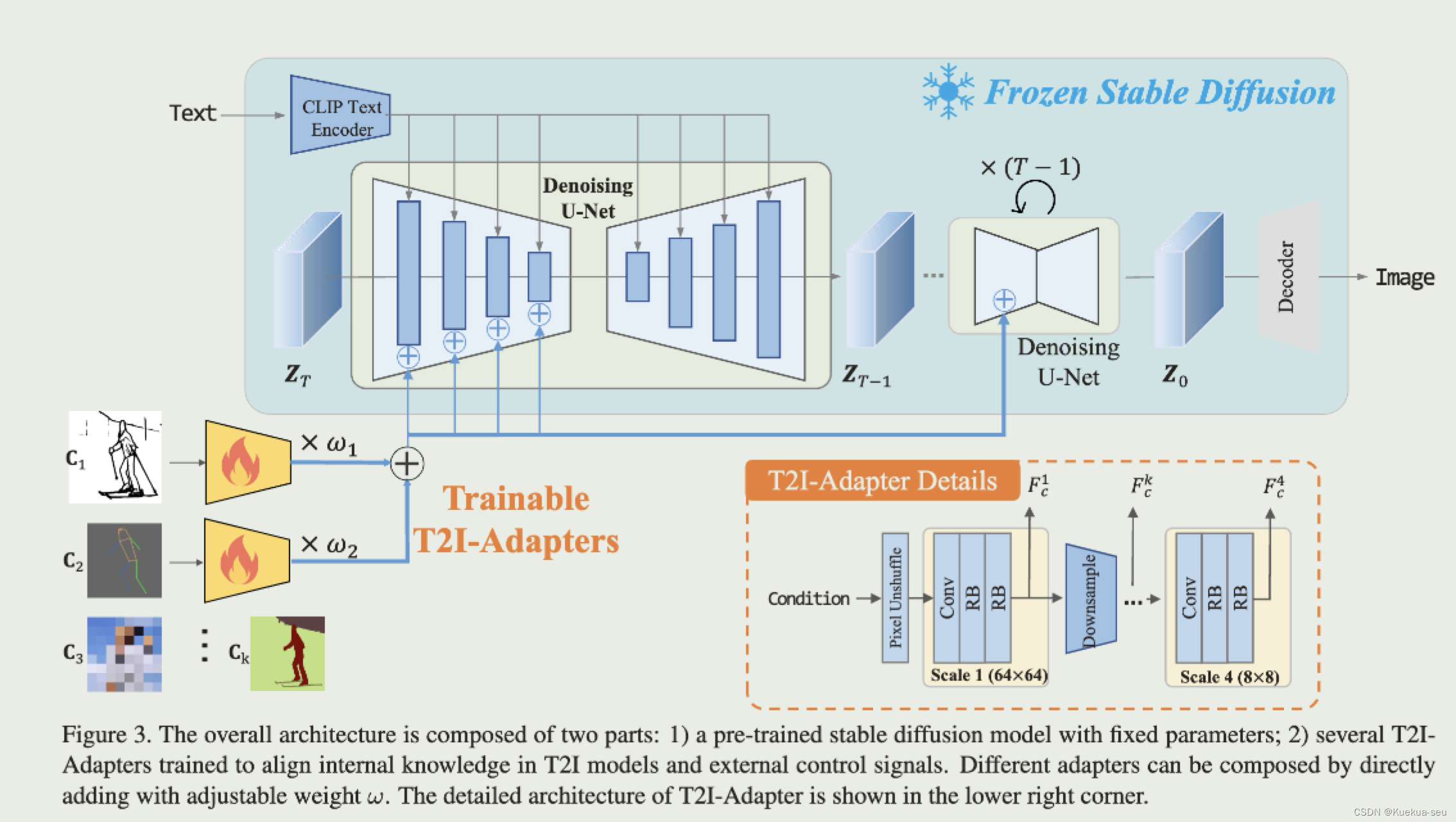
Tips:
- 颜色信息作为condtion时会做特殊前处理,先下采样再上采样,以去除图片中的语义及结构信息,最终生成类似马赛克图片(如上图c3)
- 多条件融合输入采用权重相加的方式,权重需要自行调节大小
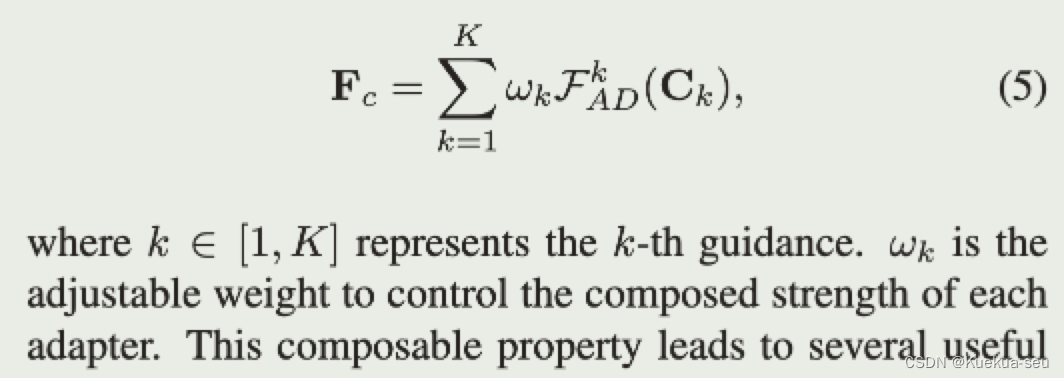
- 时间信息也需要加入条件adapter中,不同controlNet能直接加入网络中,T2I-adapter是自行设计的卷积网络,作者并未实际加入网络当中。作者通过实验发现,条件信息在去噪过程的早期加入远比晚期控制效果好很多,因此作者在训练过程中更改时间采样函数,不用平均采样而用cubic函数实现在训练过程中更偏向于选较小的时间(即前期):

- 作者实验发现,条件控制加在encode阶段远比decode阶段效果好,可能是加入encode阶段时能享受到后续decode的参数,同时,为了不过多影响文字prompt的效果,所以条件控制只加在encode阶段

- 作者实验发现,减少adapter的大小同样也能达到不错的控制效果,因此,针对颜色条件这种比较粗的控制条件,采用较小的adapter网络
5. Uni-ControlNet
论文地址
解决问题:
解决如何将更多条件更好的融入模型,同时针对不同条件不需要训练不同adapter
解决思路:
作者将条件分成局部和全局两类,进而训练两个adapter。局部adapter参照controlNet,采用复制unet的encode和middle网络进行条件特征提取,插入特征的方式也是zero-conv,不同的是条件特征插入原UNet的encode和middle层,并且插入的层数多达13层,可能也借鉴了T2I-Adapter的想法,同时局部adapter的输入依然是noise,局部条件特征会通过FDN模块注入到adapter网络的encode的四个模块中。全局adapter只针对参考rgb图,用clip提取图像特征,而后concat在text token后面,图像特征设置了权重,测试时可按需设定:
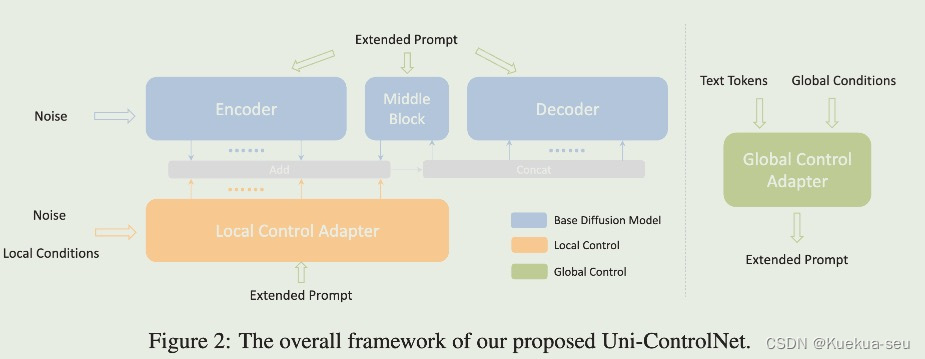
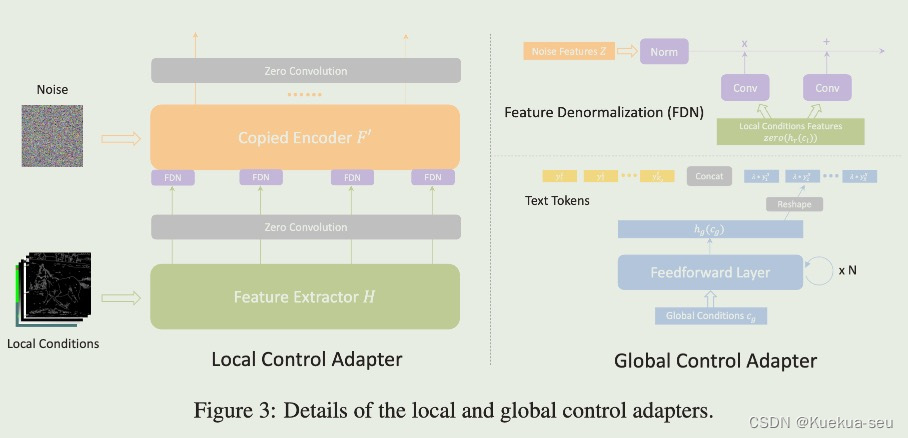
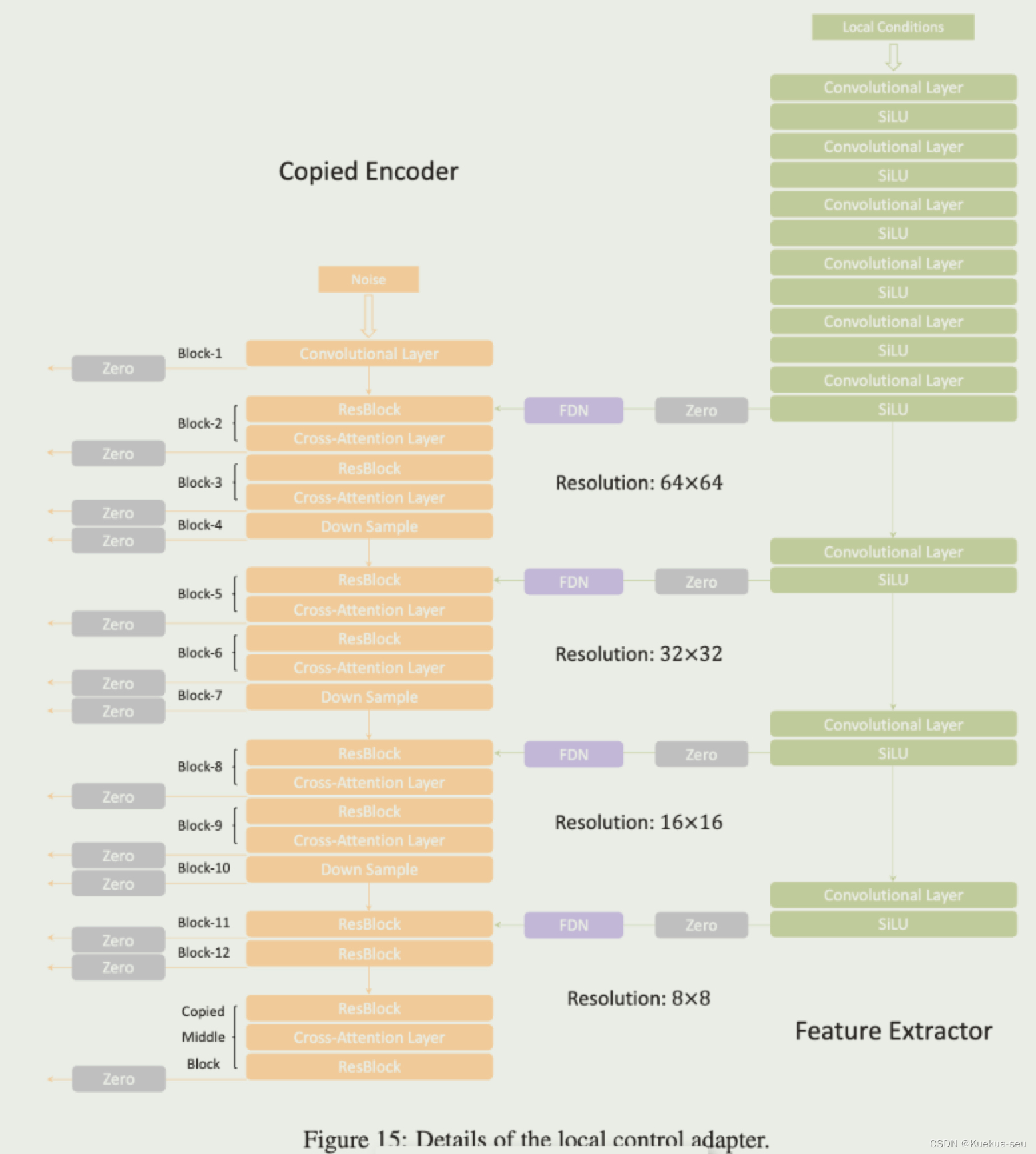
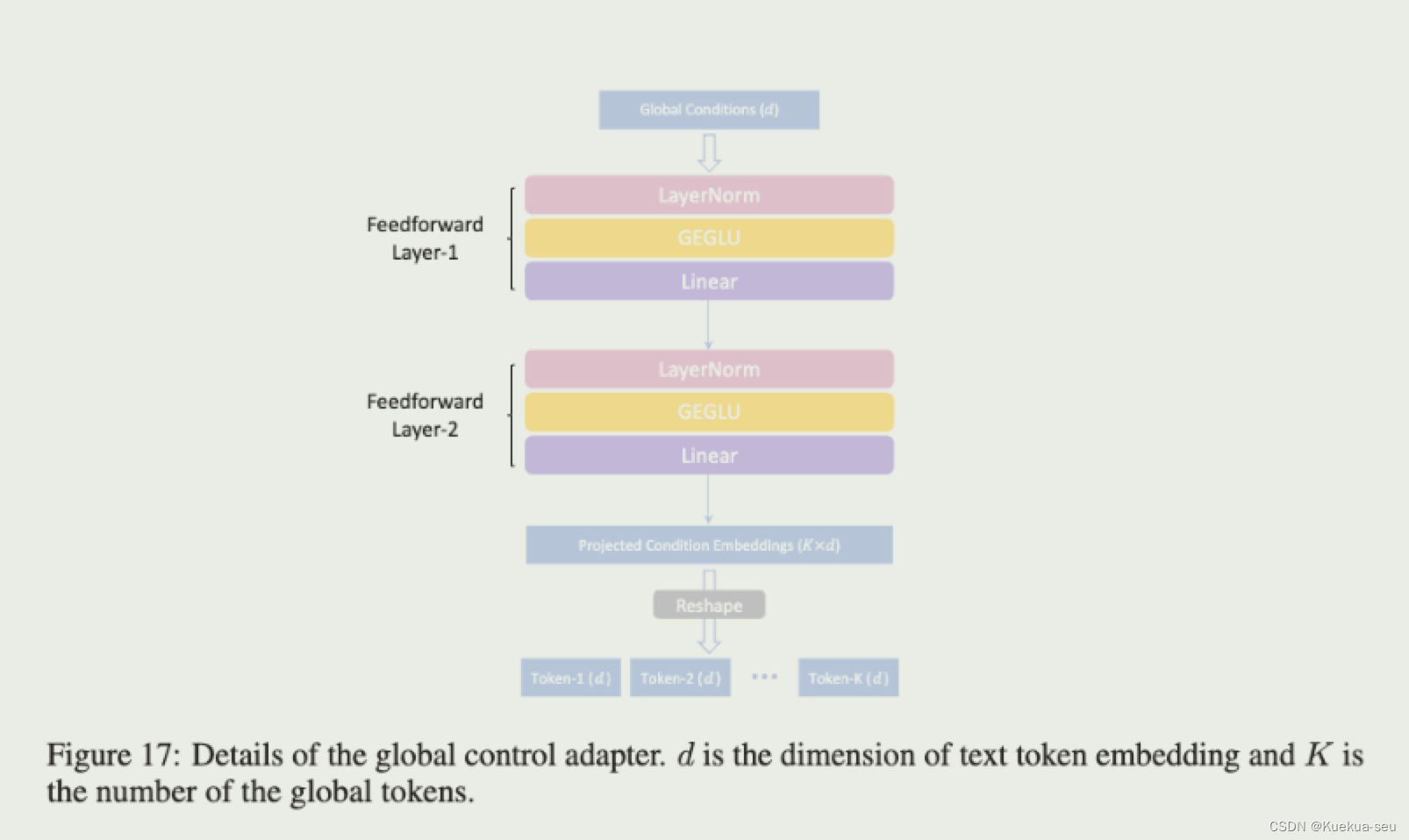
Tips:
- 全局和局部adapter需要分开训练,一起训练的话局部adapter的特征过强,会减弱全局adapter的效果,分开训练完成后也可以再次合并一起训练,不过效果改善不明显。测试时可一起使用
- 和其他方法类似,adapter训练时也会随机drop掉一些条件,以适应不同条件的组合
- 作者在测试多条件融合时发现,canny edge对结果影响最大,其次是sketch, depth, MLSD, and segmentation map,Openpose对结果影响最小
6. Composer
论文地址
解决问题:
解决如何将更多条件更好的融入模型
解决思路:
作者认为可以将原图拆分成若干组件,在图像生成阶段加入其他图像的组件(即条件控制)即可达到定向改变图像的目的。图像的组件(条件)可分成全局条件(text,rgb图和颜色直方图)和局部条件(分割图,深度图,灰度图,素描图,局部遮挡图等)。全局条件不仅通过cross-attention插入网络中,而且同时加入到timestep中。局部条件通过卷积编码和nosie 图concat一起。
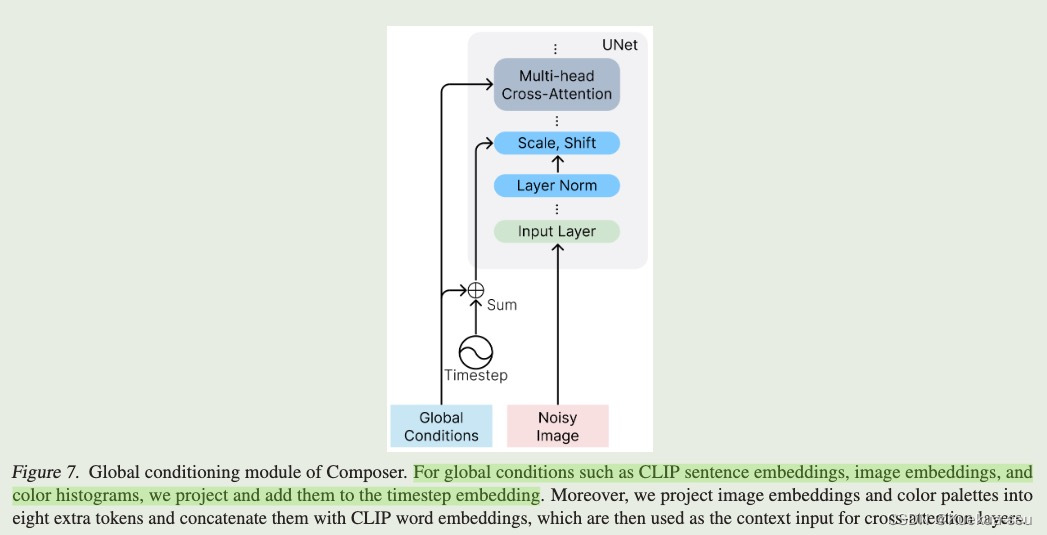

Tips:
- composer多条件输入训练参考classifier-free策略:

- 利用diffusion model的加噪减噪过程实现多域转换。用原图进行加噪得到噪声图后,再对噪声图进行降噪并添加相应转换条件:















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









