









【扩展阅读】2013-2024年AI图像生成技术经典论文
稳定扩散生成模型(Stable Diffusion)是一种潜在的文本到图像扩散模型,能够在给定任何文本输入的情况下生成照片般逼真的图像
Stable Diffusion 是基于latent-diffusion 并与 Stability AI and Runway合作实现的
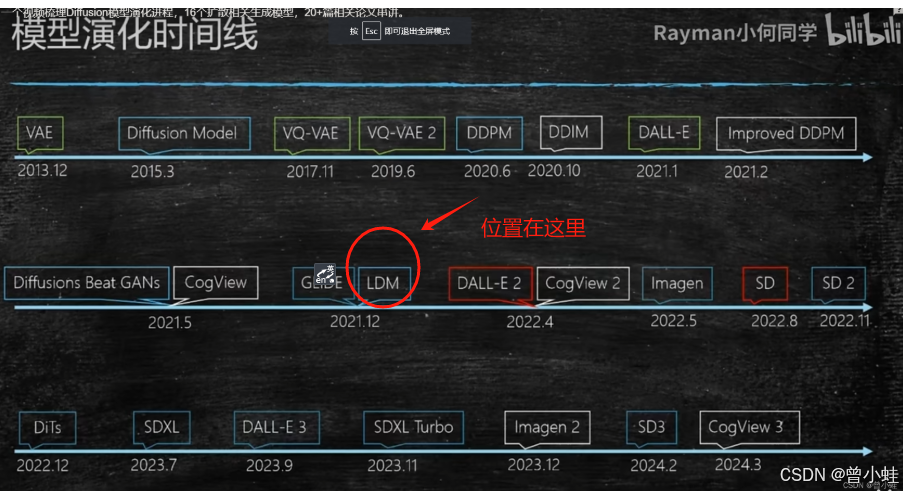
【扩散生成模型串讲】一个视频梳理Diffusion模型演化进程,16个扩散相关生成模型,20+篇相关论文串讲。】https://www.bilibili.com/video/BV13J4m1K73z/
-
paper: High-Resolution Image Synthesis with Latent Diffusion Models
-
sd模型下载与社区:https://huggingface.co/CompVis/stable-diffusion | 在线试用demo
-
AI绘画
UI界面源码:https://github.com/AUTOMATIC1111/stable-diffusion-webui -
AI绘画UI部署、
一键安装包:https://www.bilibili.com/video/BV1iM4y1y7oA/ -
秋叶从工程角度
解析stable-diffusion:https://www.bilibili.com/video/BV1x8411m76H/ -
独立研究员-星空:论文摘要引言+
简化代码解读 https://space.bilibili.com/250989068/channel/collectiondetail?sid=674068 -
唐宇迪2小时diffusion背后数学公式推导:https://www.bilibili.com/video/BV1tY4y1N7jg
-
知乎大神 小小将
公式+pytorch代码讲解 扩散模型之DDPM: https://zhuanlan.zhihu.com/p/563661713
图5 基于提出的LDM模型的文本到图像合成示例。

模型是在LAION 数据集上训练的。使用200个DDIM迭代和η = 1.0生成的样本。我们使用无条件指导[32]与s = 10.0。
需要先了解的概念
扩散模型如何应用在图像中(Diffusion Models)
扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),
其中前向过程又称为扩散过程(diffusion process)。
扩散过程是指的对数据逐渐增加高斯噪音直至数据变成随机噪音的过程。
什么是 latent-diffusion模型?
diffusion 与 latent diffusion的区别,可以理解为 diffusion直接在原图进行图片的去噪处理,而 latend diffusion 是图像经过VAE编码器压缩的图像,进行diffusion处理,然后再通过解码器,对压缩后的latent 编码还原为图像。
理论来源于论文DDPM
- [30] 2006.Denoising diffusion probabilistic models 去噪扩散概率模型 (被引 623)
DDPM基于扩散概率模型(diffusion probabilistic models)提出了高质量的图像合成结果,这是一类潜在变量模型(a class of latent variable models) 的灵感来自于非平衡热力学的方法(1503.Deep unsupervised learning using nonequilibrium thermodynamics)
核心公式

李宏毅老师讲解Diffusion Models课件: | 视频
核心在于训练unet结构noise预测器
主体结构都是在Unet模型作 骨干网络 (backbone), 下图为实际DDPM的结构

举例说明

Denoise模组:noise predicter

训练过程
最原始的过程

论文中训练方法描述:


论文概述
原图3:网络结构。
通过连接和更一般的交叉注意力机制,来调节条件 LDMs

结构解析12-知乎小小将:
基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势。文生图模型往往参数量比较大,基于pixel的方法往往限于算力只生成64x64大小的图像,比如OpenAI的DALL-E2和谷歌的Imagen,然后再通过超分辨模型将图像分辨率提升至256x256和1024x1024;而基于latent的SD是在latent空间操作的,它可以直接生成256x256和512x512甚至更高分辨率的图像。
SD主体结构如下图所示,主要包括三个模型:autoencoder (variantional auto-encoder):encoder将图像压缩到latent空间,而decoder将latent解码为图像;CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition;UNet:扩散模型的主体,用来实现文本引导下的latent生成

秋叶解析SD结构
从工程角度解析stable-diffusion:https://www.bilibili.com/video/BV1x8411m76H/

SD中的实际推理流程

独立研究员-星空解析
AI绘画 Stable Diffusion 文生图脚本 逐行代码解读 注释+图解

SD的条件推理链路
文本输入 > BERT Tokenization 分词 > CLIP Text Encoder (文本编码器) > embediing (表示输入数据的特征空间中连续且稠密的高维向量)

图生图的框图流程

摘要
通过将图像形成过程(image formation process)分解为( by decomposing )去噪自编码器的连续应用(a sequential application of denoising autoencoders),扩散模型(DMs),实现了对图像数据的最先进的合成结果。
此外,他们的公式(formulation)允许一个指导机制(a guiding mechanism)来控制图像生成过程,而无需再训练.
然而,由于这些模型通常直接在像素空间中(pixel space)运行,强大的DMs模型的优化通常需要数百天的GPU运算,而且由于顺序评估(sequential evaluations),推理是昂贵的。
为了了使DM能够在有限的计算资源上进行训练,同时保持(retaining)其质量和灵活性,我们将其应用于强大的预训练自动编码器(autoencoders)的潜在空间中(latent space)。
与之前的工作相比,在这种表示上(representation)训练扩散模型首次允许在降低复杂度和保持细节复杂度之间达到一个接近最优的点(near-optimal),大大提高了视觉保真度.。。。
. 通过在模型架构中引入交叉注意层(cross-attention layer),我们将扩散模型转化为强大而灵活的生成器,用于一般条件输入,如文本或边界框,以卷积方式和高分辨率的合成成为可能。
我们的潜在扩散模型(LDMs)在图像内绘制和类条件图像合成方面获得,并且在各种任务上具有高度竞争力的性能,包括文本到图像合成、无条件图像生成和超分辨率,同时与基于像素的DMs(pixed-based DMS)相比,显著降低了计算需。
论文贡献
- 与纯粹的基于transformer的方法相比,我们的方法更适合于(more graceful to )高维数据,因此可以在压缩级别上工作,这提供了比以前的工作更可靠和详细的重建,应用于
百万像素图像(megapixel)的高分辨率合成。 - 我们在
多个任务(无条件图像合成、图像修复(inpainting)、随机超分辨率((stochastic super-resolution)))和数据集上实现了具有竞争力的性能,同时显著降低了计算成本(significantly lowering
computational costs)。与基于像素的扩散方法相比,我们也显著降低了推理成本。 - 与之前工作相比,不需要同时对重建和生成能力进行精细的加权(requiring delicate weighting),这确保了非常准确的重建(faithful reconstructions),并且对潜在空间的正则化要求非常低(requiring very little regularization)
- 我们设计了一种基于
交叉注意( cross-attention)的通用条件输入机制( a general-purpose conditioning
mechanism),实现了多模态训练。我们使用它来训练类条件的模型、文本到图像的模型和布局到图像(n class-conditional, text-to-image, layout-to-image)的模型。
论文原图1 生成图的效果与Dalle-e 、VQGAN比较

图4 特定类数据集训练合成结构

图8 基于coco目标检测框引导合成

图10 超分结果

图11 图像修复结果

DDIM采样
来自论文 [84] 2010.Denoising diffusion implicit models ( 去噪扩散隐式模型 )
- 去噪扩散概率模型(
DDPMs: Denoising diffusion probabilistic model)在没有对抗性训练(without adversarial training)的情况下实现了高质量的图像生成,但它们需要多次模拟马尔可夫链(Markov chain)才能生成样本。 - 为了加速采样,本文提出了
去噪扩散隐式模型(DDIMs),这是一种更有效的迭代隐式概率模型( denoising diffusion implicit models),具有与DDPMs相同的训练过程。一类更有效的迭代隐式概率模型(iterative implicit probabilistic models ),具有与DDPM相同的训练过程。 - DDPMs中,生成过程(generative process)被定义为一个特定的马尔可夫扩散过程的反向过程(as the reverse of a particular Markovian diffusion process)。
- 我们通过一类非马尔可夫扩散过程来推广DDPMs,从而得到相同的训练目标。这些非马尔可夫过程可以
对应于确定性的生成过程,从而产生能够快速产生高质量样本的隐式模型。 - 我们的经验(empirically)证明,与DDPMs相比,DDIMs可以快速产生10×到50×的高质量样本,允许我们在样本质量上权衡计算,直接在潜在空间中执行有语义意义的图像插值,并以非常低的误差重建观测(reconstruct observations)
三、具体内容
1引言
图像合成需要巨大的计算资源。特别是复杂的、自然的场景的高分辨率图像合成,
目前主要是通过扩大基于可能性的(likelihood-based)模型,可能包含自回归(AR)transformers 的数十亿个参数,相关论文为:
- 2102.DALL-E Zero-Shot Text-to-Image Generation (被引:800)
- 1906.VQ-VAE-2 Generating diverse high-fidelity images with VQ-VAE-2
GANs
相比之下,GANs的有希望的结果已被揭示大多局限于可变性相对有限的数据 (limited variability),因为它们的对抗性学习过程不容易扩展(not easyily scale to)到建模复杂的、多模态分布(multi-modal distributions),相关研究
- 1809.BigGAN:Large scale GAN training for high fidelity natural image synthesis . (DeepMind)(
被引 3448) - 1406.Generative adversarial networks (GAN的开山之作) (
被引51091) - StyleGAN1:A style-based generator architecture for generative adversarial networks. (被引 5146)
Diffusion
最近,扩散模型[82],基于自动编码器去噪层次,已经显示了令人印象深刻的成就
结果在图像合成[30,85]和超过并定义了[7,45,48,57],
- [30] 2006.Denoising diffusion probabilistic models 去噪扩散概率模型 (被引 623)
- [85] 2011.Score based generative modeling through stochastic differential equations. (通过使用随机微分方程进行的基于分数的生成建模。) ( 被引356)
- [7] 2109.Wavegrad: Estimating gradients for waveform generation. (估计波形产生的梯度).(没有图像生成)(被引193)
- [45] 2107.Variational diffusion models. 变分扩散模型。(被引107)
- [48] A versatile diffusion model for audio synthesis 一种用于音频合成的通用扩散模型 (被引200)
- [57] Symbolic music generation with diffusion models.具有扩散模型的符号性音乐生成。
最先进的类条件图像合成[15,31]和超分辨率[72]。
- [15] 2105.Diffusion models beat gans on image synthesis 扩散模型在图像合成上超过了GANS (openAI) (被引354 )
- [72] 2104.Image super-resolution via iterative refinement 通过迭代细化得到的图像超分辨率 (被引115)
此外,即使是无条件的 DMs,也可以很容易地应用于诸如图像修复和上色等任务[85]
基于冲程的(strike-base)合成[53]
持续更新中。。。
关注下面公众号,发送文字 sd1论文,获得相关资源



















 2711
2711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











