







 本文对比分析了Kettle、Sqoop、DataX和StreamSets四种ETL工具的特点和适用场景。Kettle是一款纯Java编写的开源ETL工具,支持多种操作系统,具有丰富的组件和图形界面设计能力。Sqoop专注于Hadoop与传统数据库之间的数据传输,支持全量和增量数据导入。DataX由阿里巴巴开发,用于各种数据源间的高效数据同步,特别适合ELT模式。StreamSets则是一款轻量级实时数据流处理工具。
本文对比分析了Kettle、Sqoop、DataX和StreamSets四种ETL工具的特点和适用场景。Kettle是一款纯Java编写的开源ETL工具,支持多种操作系统,具有丰富的组件和图形界面设计能力。Sqoop专注于Hadoop与传统数据库之间的数据传输,支持全量和增量数据导入。DataX由阿里巴巴开发,用于各种数据源间的高效数据同步,特别适合ELT模式。StreamSets则是一款轻量级实时数据流处理工具。
前言
对于数据集成类应用,通常会采用ETL工具辅助完成。ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程。当前的很多应用也存在大量的ELT应用模式。常见的ETL工具或类ETL的数据集成同步工具很多,以下对开源的 Kettle、Sqoop、Datax、Streamset进行简单梳理比较。
一、Kettle
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,数据抽取高效稳定。Kettle的Spoon有丰富的Steps可以组装开发出满足多种复杂应用场景的数据集成作业,方便实现全量、增量数据同步。缺点是通过定时运行,实时性相对较差。
- 免费开源:基于java的免费开源的软件,对商业用户也没有限制
- 易配置:可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定
- 不同数据库:ETL工具集,它允许你管理来自不同数据库的数据
- 两种脚本文件:transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制
- 图形界面设计:通过图形界面设计实现做什么业务,无需写代码去实现
- 定时功能:在Job下的start模块,有一个定时功能,可以每日,每周等方式进行定时
- Kettle家族目前包括4个产品:Spoon、Pan、CHEF、Kitchen。
- SPOON:允许你通过图形界面来设计ETL转换过程(Transformation)
- PAN:允许你批量运行由Spoon设计的ETL转换 (例如使用一个时间调度器)。Pan是一个后台执行的程序,没有图形界面
- CHEF:允许你创建任务(Job)。 任务通过允许每个转换,任务,脚本等等,更有利于自动化更新数据仓库的复杂工作。任务通过允许每个转换,任务,脚本等等。任务将会被检查,看看是否正确地运行了
- KITCHEN:允许你批量使用由Chef设计的任务 (例如使用一个时间调度器)。KITCHEN也是一个后台运行的程序
二、Sqoop
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。通过导入导出命令加配套参数控制操作。
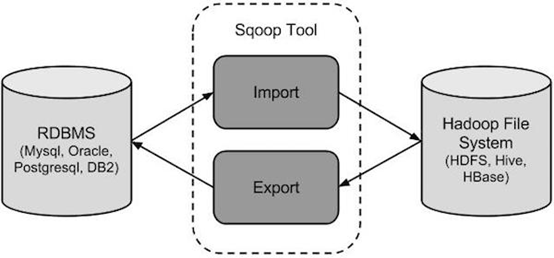
- Sqoop导入:导入工具从RDBMS到HDFS导入单个表。表中的每一行被视为HDFS的记录。所有记录被存储在文本文件的文本数据或者在Avro和序列文件的二进制数据。
- Sqoop导出:导出工具从HDFS导出一组文件到一个RDBMS。作为输入到Sqoop文件包含记录,这被称为在表中的行。那些被读取并解析成一组记录和分隔使用用户指定的分隔符。
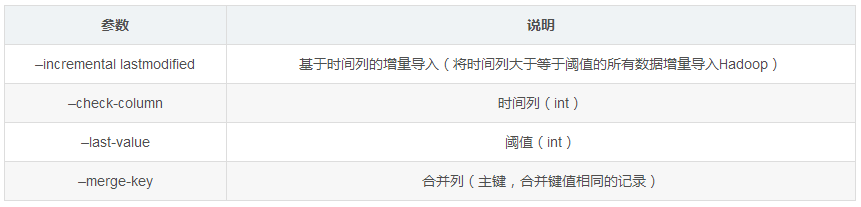
Sqoop支持全量数据导入和增量数据导入(增量数据导入分两种,一是基于递增列的增量数据导入(Append方式)。二是基于时间列的增量数据导入(LastModified方式)),同时可以指定数据是否以并发形式导入。
(1)、Append方式

(2)、LastModified方式
三、DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。DataX采用了框架 + 插件 的模式,目前已开源,代码托管在github。从应用的模式,DataX更适合ELT模式。步骤:操作简单通常只需要两步;创建作业的配置文件(json格式配置reader,writer);启动执行配置作业。
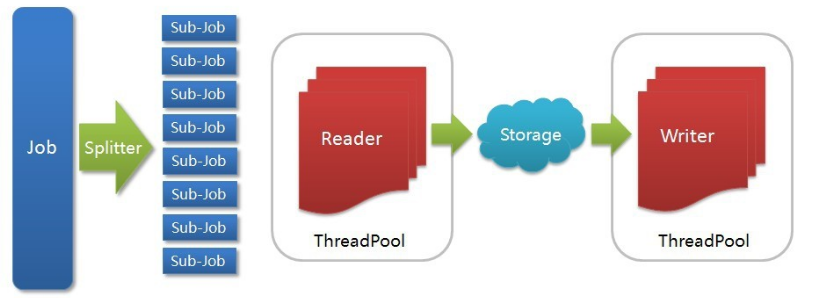
- Job:一道数据同步作业
- Splitter:作业切分模块,将一个大任务与分解成多个可以并发的小任务.
- Sub-job:数据同步作业切分后的小任务
- Reader(Loader):数据读入模块,负责运行切分后的小任务,将数据从源头装载入
- DataXStorage:Reader和Writer通过Storage交换数据
- Writer(Dumper):数据写出模块,负责将数据从DataX导入至目的数据地
DataX框架内部通过双缓冲队列、线程池封装等技术,集中处理了高速数据交换遇到的问题,提供简单的接口与插件交互,插件分为Reader和Writer两类,基于框架提供的插件接口,可以十分便捷的开发出需要的插件。缺乏对增量更新的内置支持,因为DataX的灵活架构,可以通过shell脚本等方式方便实现增量同步。
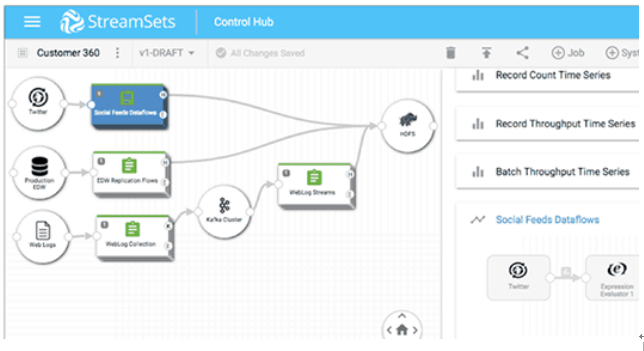
四、StreamSets
StreamSets 数据收集器是一个轻量级,强大的引擎,实时流数据。使用Data Collector在数据流中路由和处理数据。
要为Data Collector定义数据流,请配置管道。一个流水线由代表流水线起点和终点的阶段以及您想要执行的任何附加处理组成。配置管道后,单击“开始”,“ 数据收集器”开始工作。Data Collector在数据到达原点时处理数据,在不需要时静静地等待。您可以查看有关数据的实时统计信息,在数据通过管道时检查数据,或仔细查看数据快照。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











