






1、安装
参考1:docs/install_guide.md · R1-CLM/MindSpeed-RL - Gitee.com
参考2:VLLM x Ascend框架_vllm-ascend-CSDN博客
2、SFT微调
整体参考docs/supervised_finetune.md
自定义数据格式同:AUTO-DL 910B + mindspeed-llm 4层DeepSeek V3微调-CSDN博客
第4节,领域语料。
(1)在configs/datasets目录下,新增search_instruction_non_pack.yaml文件(参考alpaca_instruction_non_pack.yaml),注意这里pack和nopack的区别,pack一般用于多轮,含有history等字段,非pack模式下,有instruction,input,output字段即可。
(2)执行sh examples/data/preprocess_data.sh search_instruction_non_pack,这里preprocess_data脚本有点问题,修改如下:
SCRIPT_DIR=$(cd "$(dirname "$0")" && pwd)
export PYTHONPATH=$SCRIPT_DIR/../..:$PYTHONPATH
PROJECT_PATH=$SCRIPT_DIR/../..
# 默认值
default_config="alpaca_pairwise"
config=$1
python "$PROJECT_PATH"/cli/preprocess_data.py $config(3)转换文件格式hf为mcore格式
修改模型目录,设置pp为1,执行:sh examples/ckpt/ckpt_convert_qwen25_hf2mcore.sh
export CUDA_DEVICE_MAX_CONNECTIONS=1
# 修改 ascend-toolkit 路径
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 设置需要的权重转换参数
python cli/convert_ckpt.py \
--use-mcore-models \
--model-type GPT \
--load-model-type hf \
--save-model-type mg \
--target-tensor-parallel-size 1 \
--target-pipeline-parallel-size 1 \
--add-qkv-bias \
--load-dir /root/autodl-tmp/qwen2.5-0.5b \
--save-dir /root/autodl-tmp/qwen2.5-0.5b-mcore \
--tokenizer-model /root/autodl-tmp/qwen2.5-0.5b/tokenizer.json \
--model-type-hf llama2 \
--params-dtype bf16
(4)拷贝一份sft_qwen25_0.5b.sh,修改如下:
注意:这里去掉了SOCKET_IFNAME相关设置,改为HCCL_CONNECT_TIMEOUT
#!/bin/bash
export CUDA_DEVICE_MAX_CONNECTIONS=1
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export HCCL_CONNECT_TIMEOUT=3600
export HYDRA_FULL_ERROR=1
GPUS_PER_NODE=1
MASTER_ADDR=localhost
MASTER_PORT=6005
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DISTRIBUTED_ARGS="
--nproc_per_node $GPUS_PER_NODE \
--nnodes $NNODES \
--node_rank $NODE_RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT
"
torchrun $DISTRIBUTED_ARGS cli/train_sft.py \
--config-name sft_qwen25_0.5b \
| tee logs/sft_qwen25_0.5b_rank${NODE_RANK}.log
拷贝一份sft_qwen25_0.5b.yaml修改如下:
defaults:
- model:
- qwen25_0.5b
sft:
# tune_args:
finetune: true
stage: sft
is_instruction_dataset: true
variable_seq_lengths: true
tokenizer_not_use_fast: true
prompt_type: qwen
# gpt_args:
norm_epsilon: 1e-6
micro_batch_size: 4
global_batch_size: 128
tokenizer_type: PretrainedFromHF
tokenizer_name_or_path: /root/autodl-tmp/qwen2.5-0.5b/
train_iters: 5000
lr: 5e-5
lr_decay_style: cosine
min_lr: 1.25e-7
lr_warmup_fraction: 0.01
weight_decay: 1e-1
clip_grad: 1.0
initial_loss_scale: 4096
use_distributed_optimizer: true
tensor_model_parallel_size: 2
pipeline_model_parallel_size: 2
sequence_parallel: false
use_mcore_models: true
use_fused_rmsnorm: true
use_flash_attn: true
no_masked_softmax_fusion: true
no_gradient_accumulation_fusion: true
use_fused_swiglu: true
use_fused_rotary_pos_emb: true
bf16: true
seq_length: 4096
adam_beta1: 0.9
adam_beta2: 0.95
attention_dropout: 0.0
init_method_std: 0.01
hidden_dropout: 0.0
overlap_grad_reduce: true
overlap_param_gather: true
# data_args:
data_path: ./data/search/search_train
split: 100,0,0
no_shuffle: false
# ckpt_args:
no_load_optim: true
no_load_rng: true
no_save_optim: true
no_save_rng: true
seed: 1234
model: qwen25_0.5b
load: /root/autodl-tmp/qwen2.5-0.5b-mcore
save: /root/autodl-tmp/output-rl-0.5b-sft
# output_args:
log_interval: 1
save_interval: 5000
eval_interval: 5000
eval_iters: 0
log_throughput: true
qwen25_0.5b:
use_mcore_models: true
num_layers: 24
hidden_size: 896
ffn_hidden_size: 4864
num_attention_heads: 14
rotary_base: 1000000
max_position_embeddings: 32768
make_vocab_size_divisible_by: 1
padded_vocab_size: 151936
untie_embeddings_and_output_weights: true
add_qkv_bias: true
disable_bias_linear: true
group_query_attention: true
num_query_groups: 2
position_embedding_type: rope
normalization: RMSNorm
swiglu: true
attention_softmax_in_fp32: true
执行: sh examples/sft/sft_qwen25_0.5b.sh
报错:[rank0]: RuntimeError: Error(s) in loading state_dict for GPTModel:
[rank0]: Missing key(s) in state_dict: "output_layer.weight".
这个缺陷2月份已经有人提交,但未解决。MindSpeed-r1加载权重报错output_layer.weight key缺失 · Issue #IBNT8L · Ascend/MindSpeed-LLM - Gitee.com
3、GRPO
使用mindspeed-llm中微调好的单层R1作为推理模型。遇到如下报错:
(1)ttributeError: 'AscendQuantConfig' object has no attribute 'packed_modules_mapping'
参考:https://github.com/vllm-project/vllm-ascend/issues/420
建议升级到vllm-ascend RC2,注意原安装说明是有问题的,需要手工下载rc2文件,然后解压安装。
(2)KeyError: 'model.layers.0.self_attn.q_a_proj.weight'
File "/root/autodl-tmp/vllm-ascend-0.7.3rc2/vllm_ascend/quantization/quant_config.py", line 93, in get_quant_method
if self.is_layer_skipped_ascend(prefix,
File "/root/autodl-tmp/vllm-ascend-0.7.3rc2/vllm_ascend/quantization/quant_config.py", line 135, in is_layer_skipped_ascend
is_skipped = self.quant_description[prefix + '.weight'] == "FLOAT"
在config.json配置中,有如下配置:
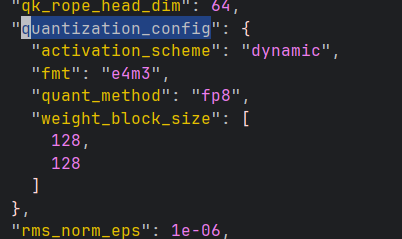
而在 /root/miniconda3/lib/python3.10/site-packages/vllm/entrypoints/llm.py中有提示:

因此去掉config.json中的相关配置即可。
(3)权重加载找不到目录:
if args.load_format == "megatron":
tp_rank = ps._TP.rank_in_group
weights_path = os.path.join(args.load, f"iter_0000100/mp_rank_{tp_rank:02}/model_optim_rng.pt")
这里格式如果设置为megatron,检查点文件需要严格匹配。
(4) File "/root/autodl-tmp/mindspeed-rl/mindspeed_rl/models/rollout/vllm_adapter/megatron_weight_loaders.py", line 101, in _get_model_weight_loader
[rank0]: raise ValueError(f"Model architectures {arch} are not supported for now. "
部分改动如下:
- config.json文件:
"auto_map": {
"AutoConfig": "configuration_deepseek.DeepseekV3Config"
去掉模型本地实现
},
"hidden_size": 1024,
"intermediate_size": 1024,
去掉quantization_config配置
- 修改mindspeed_rl\models\rollout\vllm_adapter\megatron_weight_loaders.py文件:
在这个配置中增加:
MODEL_MEGATRON_WEIGHT_LOADER_REGISTRY = {
"CustomDeepseekV3ForCausalLM": deepseek_megatron_weight_loader,
}
原因:vllm-ascend-0.7.3rc2分支中,这个提交https://github.com/vllm-project/vllm-ascend/pull/391/files,使用CustomDeepseekV3ForCausalLM覆盖了原实现。
ModelRegistry.register_model(
"DeepseekV3ForCausalLM",
"vllm_ascend.models.deepseek_v2:CustomDeepseekV3ForCausalLM")
4、FAQ
停止ray相关进程:ray stop
5、VLLM测试
(1)infer_vllm.py修改如下:
def chat_task(inference_engine, query):
conversation = [
{
"role": "user",
"content": query,
},
]
import time
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/llama3.2-1b")
start_time = time.time()
outputs = inference_engine.chat(conversation)
res = process_outputs(outputs)
out = tokenizer(query + res)
logger.info(f'out len: {len(out["input_ids"])}')
logger.info('Query: {}'.format(query))
logger.info('Responses:\n{}'.format(res))
logger.info('costs:{} s'.format(time.time() - start_time))
import time
start_time = time.time()
outputs = inference_engine.chat([conversation,conversation,conversation,conversation])
res = process_outputs(outputs)
out = tokenizer(query + res)
logger.info(f'out len: {len(out["input_ids"])}')
logger.info('Query: {}'.format(query))
logger.info('Responses:\n{}'.format(res))
logger.info('costs:{} s'.format(time.time() - start_time))
start_time = time.time()
outputs = inference_engine.chat(conversation)
res = process_outputs(outputs)
out = tokenizer(query + res)
logger.info(f'out len: {len(out["input_ids"])}')
logger.info('Query: {}'.format(query))
logger.info('Responses:\n{}'.format(res))
logger.info('costs:{} s'.format(time.time() - start_time))
def generate_task(inference_engine, query):
outputs = inference_engine.llm.generate(
prompts=[query],
sampling_params=inference_engine.sampling_params,
)
res = process_outputs(outputs)
logger.info('Query: {}'.format(query))
logger.info('Responses:\n{}'.format(res))(2)新增infer_vllm_llama32_1b.sh
#!/bin/bash
#export GLOO_SOCKET_IFNAME="Your SOCKET IFNAME"
#export TP_SOCKET_IFNAME="Your SOCKET IFNAME"
export CUDA_DEVICE_MAX_CONNECTIONS=1
GPUS_PER_NODE=1
MASTER_ADDR=localhost
MASTER_PORT=6001
NNODES=1
NODE_RANK="0"
DISTRIBUTED_ARGS="
--nproc_per_node $GPUS_PER_NODE \
--nnodes $NNODES \
--node_rank $NODE_RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT
"
INFER_ARGS="
--tokenizer-name-or-path /root/autodl-tmp/llama3.2-1b-tp1-pp1/ \
--load-format megatron \
--load /root/autodl-tmp/llama3.2-1b-tp1-pp1/ \
--tensor-parallel-size 1 \
--task chat \
--prompt-type-path ./configs/model/templates.json \
--prompt-type llama3
"
torchrun $DISTRIBUTED_ARGS cli/infer_vllm.py \
$INFER_ARGS \
--query "Write an essay about the importance of higher education." \
--distributed-backend nccl
(3)llama32_1b模型定义
llama32_1b:
use_mcore_models: true
sequence_parallel: true
use_flash_attn: true
use_rotary_position_embeddings: true
use_fused_rmsnorm: true
use_fused_swiglu: true
rope_scaling_type: llama3
rope_scaling_factor: 32.0
low_freq_factor: 1.0
high_freq_factor: 4.0
original_max_position_embeddings: 8192
max_position_embeddings: 8192
num_layers: 16
hidden_size: 2048
ffn_hidden_size: 8192
num_attention_heads: 32
group_query_attention: true
num_query_groups: 8
make_vocab_size_divisible_by: 1
padded_vocab_size: 128256
disable_bias_linear: true
attention_dropout: 0.0
init_method_std: 0.01
hidden_dropout: 0.0
position_embedding_type: rope
rotary_base: 500000
normalization: RMSNorm
norm_epsilon: 1e-5
swiglu: true
no_masked_softmax_fusion: true
attention_softmax_in_fp32: true
no_gradient_accumulation_fusion: true
bf16: true启动脚本: sh examples/infer/infer_vllm_llama32_1b.sh

















 260
260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









