






前言
本篇博客主要介绍卷积神经网络中的即插即用的模块。“即插即用的插件“意味着该插件能够快速复现,并且能够随时应用到神经网络中,容易植入,容易落地,真正做到“plug-and-play”。在之前的项目当中,使用yolov4已经涉及到一些模块,如channel attention、CBAM、SE等。本文除了介绍上述几种插件,还会介绍ASPP、Non-local等即插即用小模块。本篇博客主要参考:真正的即插即用!盘点11种CNN网络设计中精巧通用的“小”插件。
卷积神经网络设计技巧
卷积神经网络中,深度决定了网络的表达能力,网络越深,其学习能力越强。宽度(通道数、卷积核)决定了网络在某一层学到的信息量,因为卷积层能重组通道间的信息,这一操作能让有效信息量增大。感受野决定了网络在某一层看到多大范围,一般而言,最后一层一定至少要看到最大的有意义的物体,更大的感受野通常是无害的。在达到相同感受野的情况下,多层小卷积核的性能一定比大卷积核更好,因为多层小卷积核的非线性更强,而且有利于特征共享,如KaTeX parse error: Undefined control sequence: \timies at position 2: 7\̲t̲i̲m̲i̲e̲s̲ ̲7卷积核与两个KaTeX parse error: Undefined control sequence: \timies at position 2: 5\̲t̲i̲m̲i̲e̲s̲ ̲5的卷积核感受野相同,但是非线性能力后者优于前者。
分辨率很重要,尽量不要损失分辨率,为了保住分辨率,在使用下采样之前要保证在这一层上有足够的感受野,这个感受野是相对感受野,是指这一个下采样层相对于上一个下采样层的感受野,把两个下采样之间看成一个子网络的话,这个子网络必须得有一定的感受野才能将空间信息编码到下面的网络去,而具体需要多大的相对感受野,只能实验,一般说来,靠近输入层的层空间信息冗余度最高,所以越靠近输入层相对感受野应该越小。同时在靠近输入层的层,这里可以合成一个大卷积核来降低计算量。
这种矛盾决定了下面的做法:
前面几层下采样频率高一点,中间层下采样频率降低,并使用不下采样的方法提高深度。
网络能深则深,在保持比较小宽度的时候,要想办法加深网络,变深的过程中网络慢慢变胖。
使用小卷积核(不包括1x1,因为它对于增加感受野无意义),小卷积核有利于网络走向更深,并且有更好的识别鲁棒性,尤其是在分辨率更小的特征图上,因为卷积核的尺寸是相当于特征图的分辨率来说的,大特征图上偏大的卷积核其实也并不大。
下采样在网络前几层的密度大一些,(这样能尽可能用微弱精度损失换取速度提升) 越往后下采样的密度应该更小,最终能够下采样的最大深度,以该层的感受野以及数据集中最大的有意义物体尺寸决定(自然不可能让最大有意义的物体在某一层被下采样到分辨率小于1,但是网络依然可以work,只不过最后几层可能废弃了(要相信cnn的学习能力,因为最大不了它也能学出单位卷积,也就是只有中心元素不为0的卷积核),更准确的说这是最大感受野的极限,最大感受野应该覆盖数据集中最大有意义的物体)。
第一层下采样的时候大卷积核能尽可能保住分辨率(其实相当于合成了两三层小卷积核,另外,这和插值是类似的,类比于最近邻插值,双线性插值,双三次插值,这其实和感受野理论一致,更远的插值意味着更大的感受野)。
小插件
STN
STN出自论文:Spatial Transformer Networks。其主要架构如下图所示:
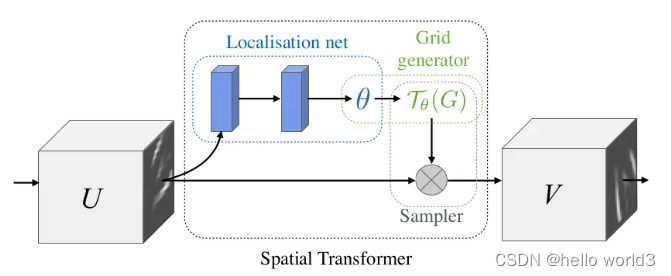
STN的思路是卷积神经网络具有平移不变性,另外还想让它具有其他不变性,如经过仿射变换的姿态不变性,位置不变性,光照不变性等,以此提高模型的泛化性能。提到卷积神经网络的平移不变性,也有一些说法证伪,说明神经网络不具有平移不变性,因为在执行卷积核池化后,下采样会破坏网络的平移不变性,使得网络不变性能力非常弱。
STN模块,显式将空间变换植入到网络当中,进而提高网络的旋转、平移、尺度等不变性。可以理解为“对齐”操作。每一个STN模块由Localisation net,Grid generator和Sampler三部分组成。Localisation net用于学习获取空间变换的参数。Grid generator用于坐标映射。Sampler用于像素的采集,是利用双线性插值的方式进行。STN的意义是能够把原始的图像纠正成为网络想要的理想图像,并且该过程为无监督的方式进行,也就是变换参数是自发学习获取的,不需要标注信息。该模块是一个独立模块,可以在CNN的任何位置插入。
ASPP
ASPP,即带有空洞卷积空间金字塔池化模块,采用不同的尺度(rate)进行空洞卷积,主要为了提高网络的感受野以及引入多尺度的信息。ASPP主要应用在语义分割Deeplab算法中,出自论文DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Conv。其结构如下图所示:
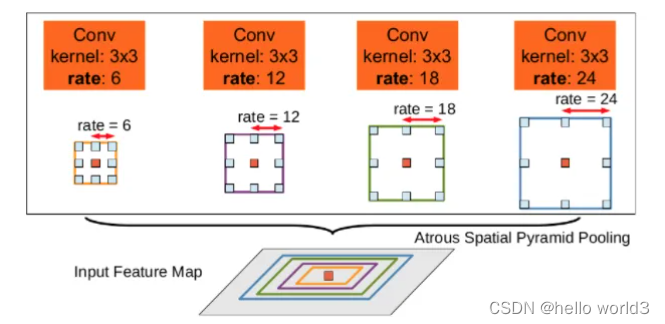
在语义分割任务中,通常面临的是分辨率较大的图片,这就要求我们的网络有足够的感受野来覆盖目标物体。对于CNN网络基本是靠卷积层的堆叠加上下采样操作来获取感受野的。本文的该模块可以在不改变特征图大小的同时控制感受野,这有利于提取多尺度信息。其中rate控制着感受野的大小,r越大感受野越大。
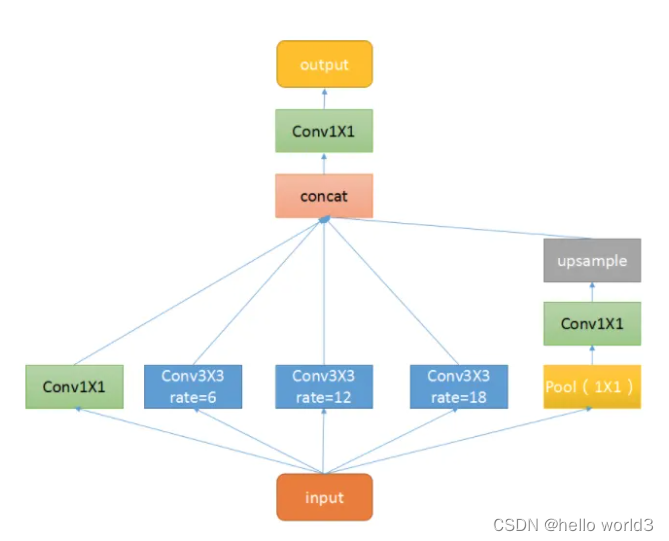
ASPP的结构类似Google net,主要包括以下几个部分:1. 一个全局平均池化层得到image-level特征,并进行1X1卷积,并双线性插值到原始大小;2. 一个1X1卷积层,以及三个3X3的空洞卷积;3. 将5个不同尺度的特征在channel维度concat在一起,然后送入1X1的卷积进行融合输出。
Non-local
Non-local模块出自论文Non-local Neural Networks
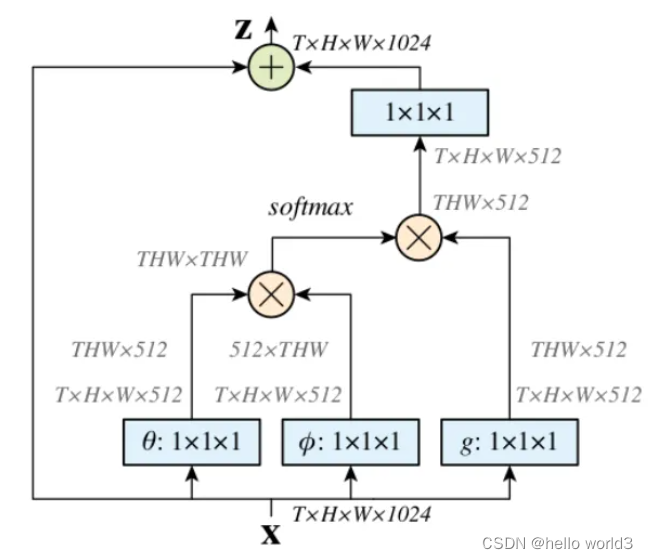
Non-Local是一种attention机制,也是一个易于植入和集成的模块。Local主要是针对感受野(receptive field)来说的,以CNN中的卷积操作和池化操作为例,它的感受野大小就是卷积核大小,而我们常用3X3的卷积层进行堆叠,它只考虑局部区域,都是local的运算。不同的是,non-local操作感受野可以很大,可以是全局区域,而不是一个局部区域。捕获长距离依赖(long-range dependencies),即如何建立图像上两个有一定距离的像素之间的联系,是一种注意力机制。所谓注意力机制就是利用网络生成saliency map,注意力对应的是显著性区域,是需要网络重点关注的区域。
- 首先分别对输入的特征图进行 1X1的卷积来压缩通道数,得到 θ \theta θ, ϕ \phi ϕ和 g g g特征。
- 通过reshape操作,转化三个特征的维度,然后对 θ \theta θ, ϕ \phi ϕ进行矩阵乘操作,得到类似协方差矩阵, 这一步为了计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系。
- 然后对自相关特征进行 Softmax 操作,得到0~1的weights,这里就是我们需要的 Self-attention系数。
- 最后将 attention系数,对应乘回特征矩阵g上,与原输入 feature map X 残差相加输出即可。
SE
SE模块其实是一种通道注意力机制。由于特征压缩和full connection的存在,其捕获通道注意力特征是具有全局信息的。而SE可以自适应地调整各通道的特征响应值,对通道间的内部依赖关系进行建模。SE的主要模块结构如下所示:
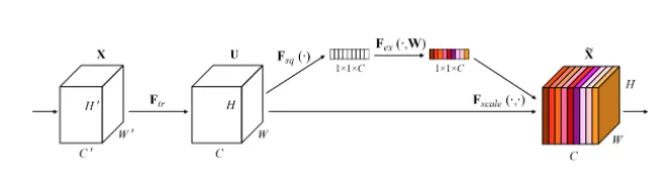
SE模块可以自适应的调整各通道的特征响应值,对通道间的内部依赖关系进行建模,有以下几个步骤:
- Squeeze:沿着空间维度进行特征压缩,将每个二维的特征通道变成一个数,是具有全局的感受野。
- Excitation:将每个特征生成一个权重,用来代表该特征通道的重要程度。
- Reweight:将Excitation输出的权重看作每个特征通道的重要性,通过相乘的方式作用于每一个通道上
CBAM
CBAM的结构如下图所示,他由两个部分组成:Channel Attention Module和Spatial Attention Module。
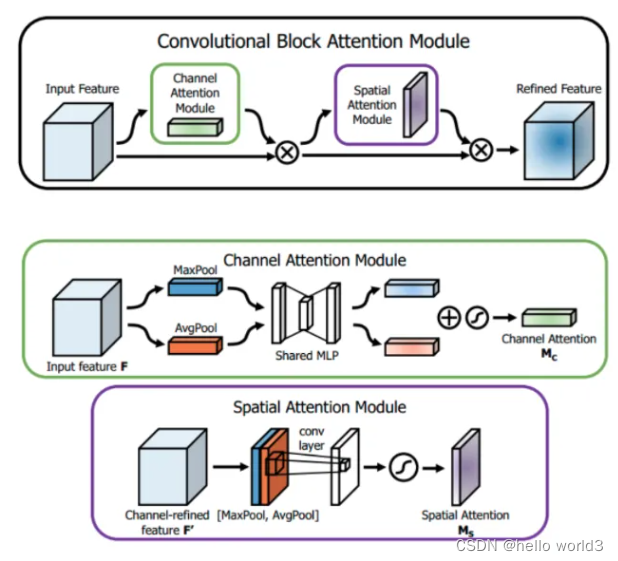
- Channel Attention Module:输入一个 H × W × C H\times W\times C H×W×C的特征 F F F,分别送进两个空间的全局平均池化核最大池化得到两个 1 × 1 × C 1\times 1\times C 1×1×C的通道描述。再将他们分别送进一个两层的神经网络,第一层的神经元的个数为 C r \frac{C}{r} rC,激活函数为Relu,第二层神经元的个数为C。这两层神经网络是共享的。然后再将得到两个特征相加后经过一个sigmoid激活函数得到权重系数 M c M_c Mc。最后将权重系统与原来的特征相乘即可得到缩放后的新特征。
- Spatial Attention Module:与通道注意力相似,对于 H × W × C H\times W\times C H×W×C的特征 F F F,先分别进行一个通道维度的平均池化和最大池化得到两个 H × W × 1 H\times W\times 1 H×W×1的通道描述,并将两个描述按照通道拼接在一起。然后经过 7 × 7 7\times7 7×7的卷积层,激活函数为sigmoid,得到权重 M s M_s Ms。最后将权重与特征 F F F进行相乘即可得到缩放后的新特征。
DCN v1&v2
变形卷积(Deformable Convolutional)出自v1: [Deformable Convolutional Networks]和v2: [Deformable ConvNets v2: More Deformable, Better Results],可以看作是变形+卷积两个部分。和传统的固定窗口的卷积相比,变形卷积可以有效地应对集合图形,因为它的局部感受野是可学习的,面向全图的。同时还提出Deformable ROI pooling,这两个方法都是增加额外偏移量的空间采样位置,不需要额外的监督,是自监督的过程。

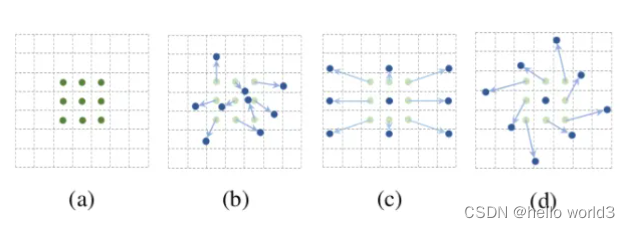
如下图所示,a为不同的卷积,b为变形卷积,深色的点为卷积核实际采样的位置,和“标准的”位置有一定的偏移。c和d为变形卷积的特殊形式,其中c为我们常见到的空洞卷积,d为具有学习旋转特性的卷积,也具备提升感受野的能力。
变形卷积和STN过程非常类似,STN是利用网络学习出空间变换的6个参数,对特征图进行整体变换,旨在增加网络对形变的提取能力。DCN是利用网络学习数整图offset,比STN的变形更“全面一点”。STN是仿射变换,DCN是任意变换。公式不贴了,可以直接看代码实现过程。
变形卷积具有V1和V2两个版本,其中V2是在V2的基础上进行改进,除了采样offset,还增加了采样权重。V2认为3X3采样点也应该具有不同的重要程度,因此该处理方法更具有灵活性和拟合能力。
BlurPool
BlurPool出自论文Making Convolutional Networks Shift-Invariant Again。基于滑动窗口的卷积操作是具有平移不变性的,因此也默认为CNN网络具有平移不变性或等变性,事实上真的如此吗?实践发现,CNN网络真的非常敏感,只要输入图片稍微改一个像素,或者平移一个像素,CNN的输出就会发生巨大的变化,甚至预测错误。这可是非常不具有鲁棒性的。一般情况下利用数据增强获取所谓的不变性。本文研究发现,不变性的退化根本原因就在于下采样,无论是Max Pool还是Average Pool,抑或是stride>1的卷积操作,只要是涉及步长大于1的下采样,均会导致平移不变性的丢失。具体示例如下图所示,仅仅平移一个像素,Max pool的结果就差距很大。
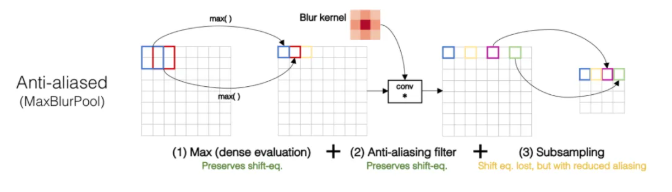
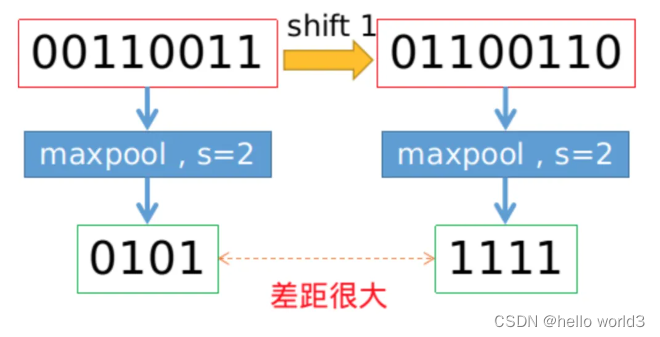
为了保持平移不变性,可以在下采样之前进行低通滤波。传统的max pool可以分解为两部分,分别是stride = 1的max + 下采样 。因此作者提出的MaxBlurPool = max + blur + 下采样来替代原始的max pool。实验发现,该操作虽然不能彻底解决平移不变性的丢失,但是可以很大程度上缓解。
RFB
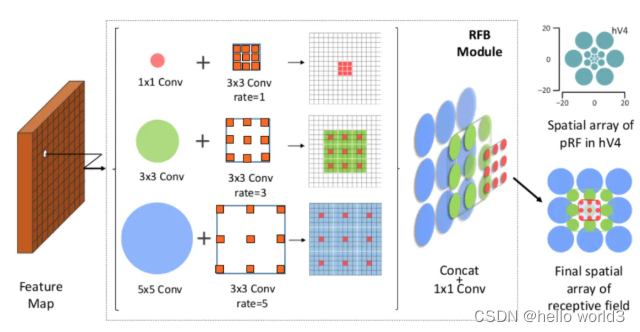
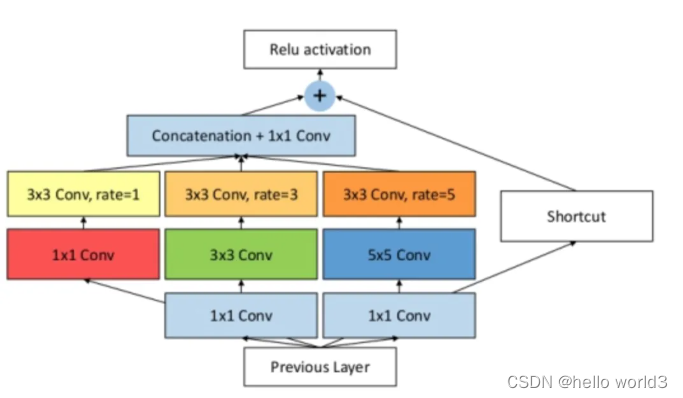
Receptive Field Block(RFB)出自Receptive Field Block Net for Accurate and Fast Object Detection。论文发现目标区域要尽量靠近感受野中心,这会有助于提升模型对小尺度空间位移的鲁棒性。因此受人类视觉RF结构的启发,本文提出了感受野模块(RFB),加强了CNN模型学到的深层特征的能力,使检测模型更加准确。RFB可以作为一种通用模块嵌入到绝大多数网路当中。下图可以看出其和inception、ASPP、DCN的区别,可以看作是inception+ASPP的结合。
ASFF
Adaptively Spatial Feature Fusion(ASFF)出自[Adaptively Spatial Feature Fusion](Adaptively Spatial Feature Fusion Learning Spatial Fusion for Single-Shot Object Detection)。
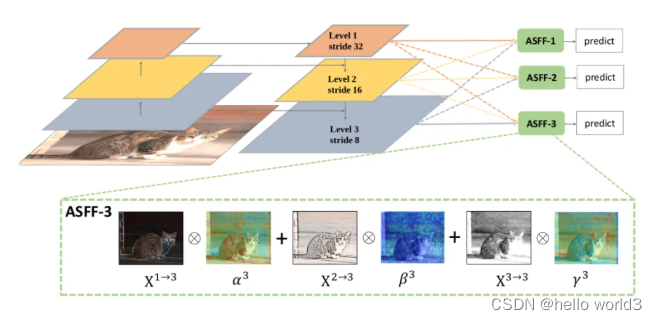
为了更加充分的利用高层语义特征和底层细粒度特征,很多网络都会采用FPN的方式输出多层特征,但是它们都多用concat或者element-wise这种融合方式,本论文认为这样不能充分利用不同尺度的特征,所以提出了Adaptively Spatial Feature Fusion,即自适应特征融合方式。FPN输出的特征图经过下面两部分的处理:
Feature Resizing:特征图的尺度不同无法进行element-wise融合,因此需要进行resize。对于上采样:首先利用1X1卷积进行通道压缩,然后利用插值的方法上采样特征图。对于1/2的下采样:利用stride=2的3X3卷积同时进行通道压缩和特征图缩小。对于1/4的下采样:在stride=2的3X3的卷积之前插入stride=2的maxpooling。
代码实现
关于这些模块的代码实现,详情可以参考我的github仓库:https://github.com/RyanCCC/CNN_Component,喜欢的可以给个star,非常感谢!















 1134
1134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









