







文章目录
前言
之前目标检测综述一文中详细介绍了目标检测相关的知识,本篇博客作为扩展补充,记录目前(2022)目标检测的最新进展,主要是在coco test-dev上霸榜且知名度较广的目标检测网络。具体详情可参考相关论文或者代码。
Swim Transformer V2
论文地址:Swin Transformer V2: Scaling Up Capacity and Resolution
代码地址:Swim Transformer V2 Code
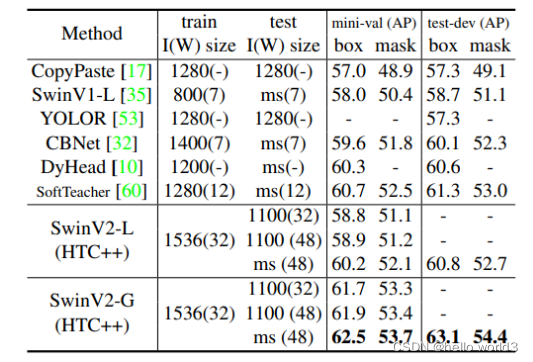
该方法展示了将Swim Transformer扩展到30亿个参数并使其能够使用高达1536输入尺寸的图像进行训练的sota探讨。通过扩大网络容量和分辨率,Swim Transformer在四个具有代表性的视觉基准上创造了记录:ImageNet-V2 图像分类的 84.0% top-1 准确率,COCO 对象检测的 63.1/54.4 box/mask mAP,ADE20K 语义分割的 59.9 mIoU, Kinetics-400 视频动作分类的 top-1 准确率为 86.8%。Swin Transformer V2使用的技术通常为扩大视觉模型,但它没有像 NLP 语言模型那样被广泛探索,部分原因在于训练和应用方面,存在以下困难:1)视觉模型经常面临大规模不样本不均衡的问题;2)许多下游视觉任务需要高分辨率图像或滑动窗口,目前尚不清楚如何有效地将低分辨率预训练的模型转换为更高分辨率的模型;3)当图像分辨率很高时,GPU 内存消耗也是一个问题。为了解决这些问题,该研究团队提出了几种技术,并通过使用 Swin Transformer 作为案例研究来说明:1)后归一化技术和缩放余弦注意方法来提高大型视觉模型的稳定性;2) 一种对数间隔的连续位置偏差技术,可有效地将在低分辨率图像和窗口上预训练的模型转移到其更高分辨率的对应物上。此外,团队分享了关键实现细节,这些细节可以显著节省 GPU 内存消耗,从而使使用常规 GPU 训练大型视觉模型的方案变得可行。
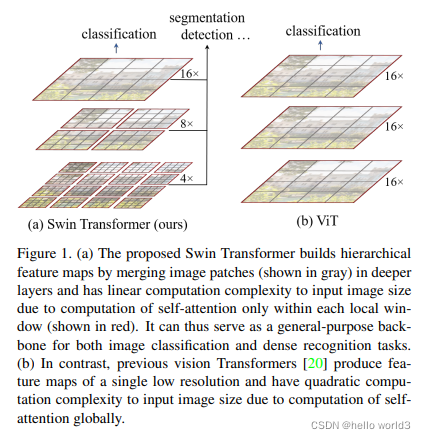
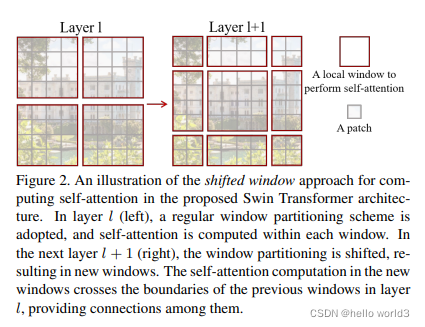
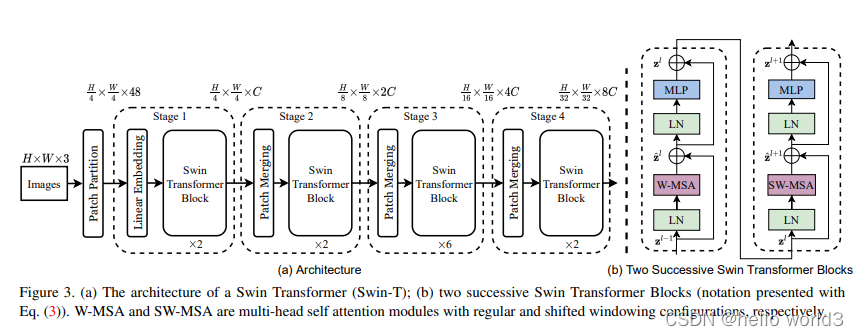
Swin Transformer
论文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
代码:Swin Transformer Code
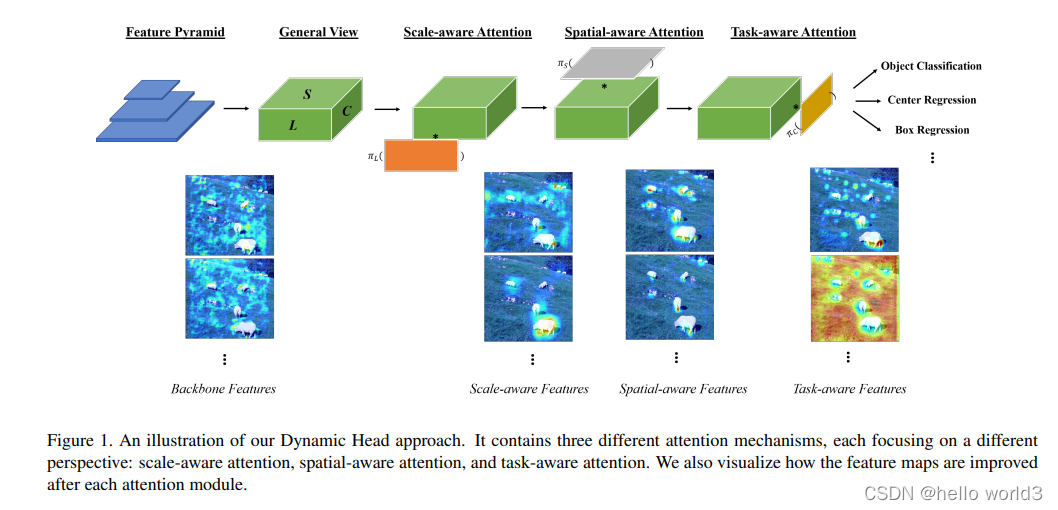
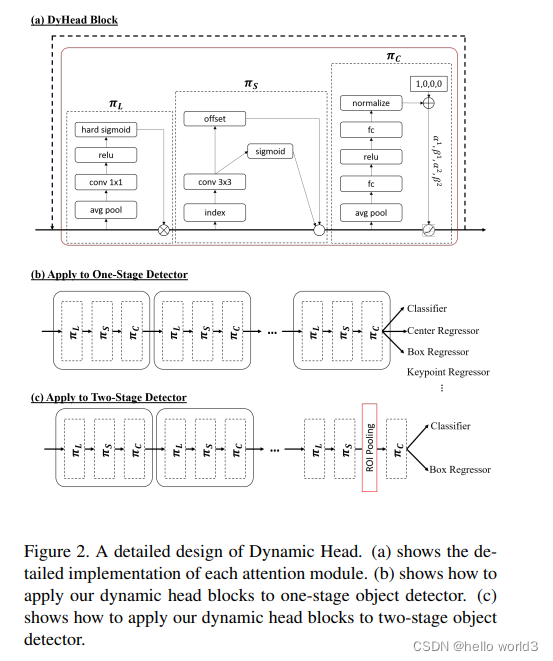
Dynamic Head
论文:Dynamic Head: Unifying Object Detection Heads with Attentions
代码:Dynamic Head Code

YOLOF
论文:You Only Look One-level Feature
代码:YOLOF Code
YOLOR
论文:You Only Learn One Representation: Unified Network for Multiple Tasks
代码:YOLOR Code
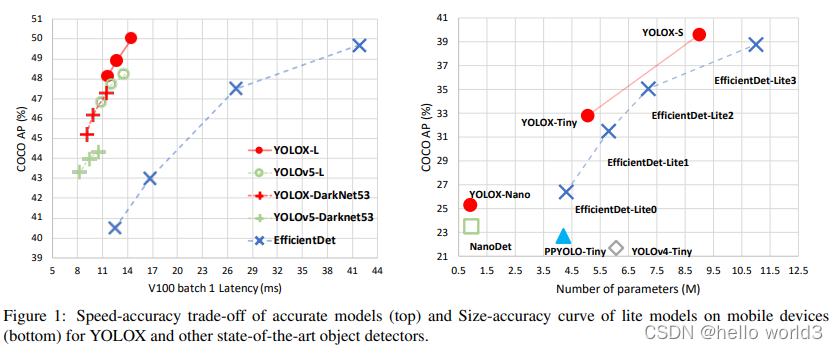
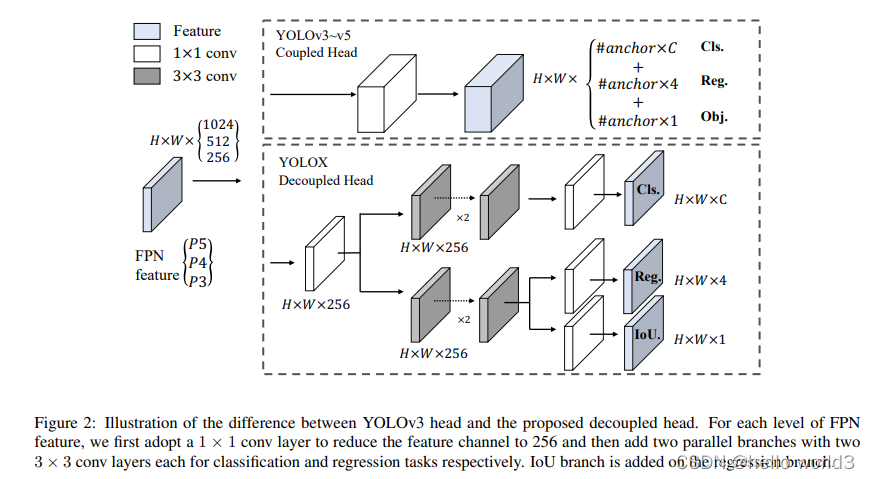
YOLOX
论文:YOLOX: Exceeding YOLO Series in 2021
代码:YOLOX Code
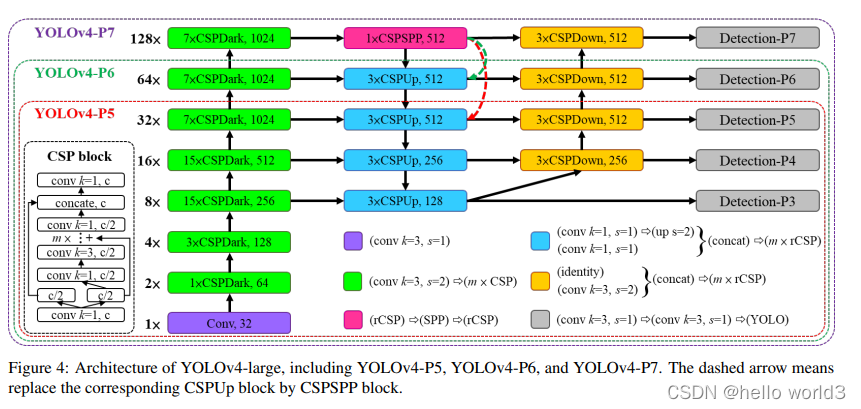
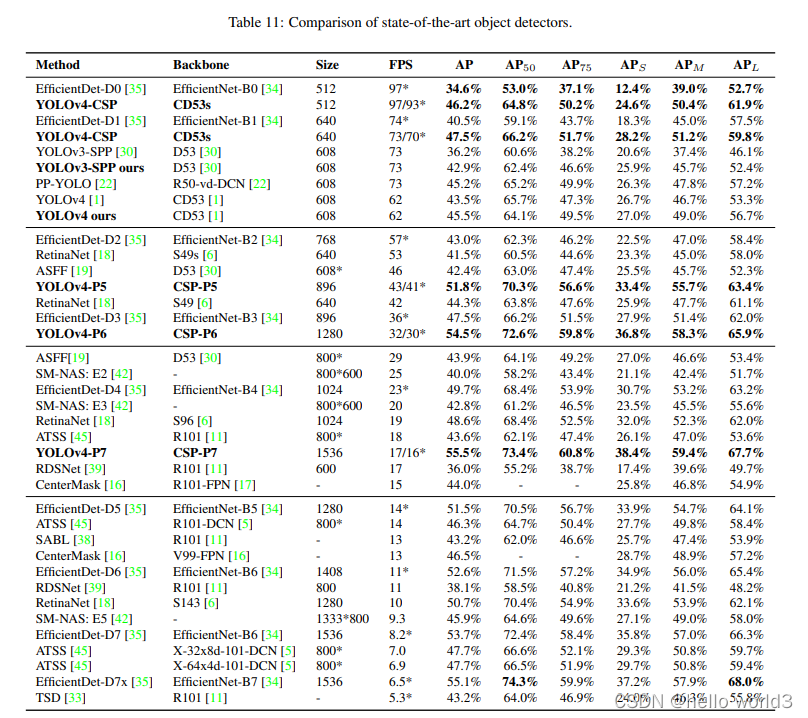
Scaled-YOLOv4
论文:Scaled-YOLOv4: Scaling Cross Stage Partial Network
代码:Scaled-YOLOv4 Code
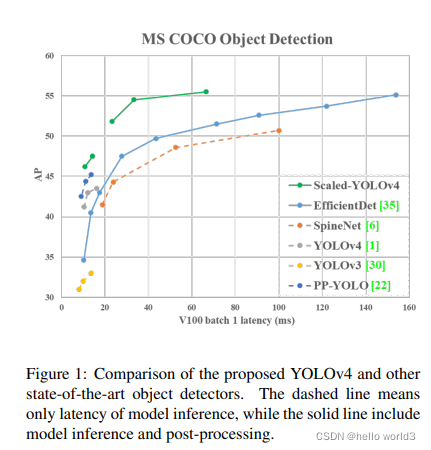
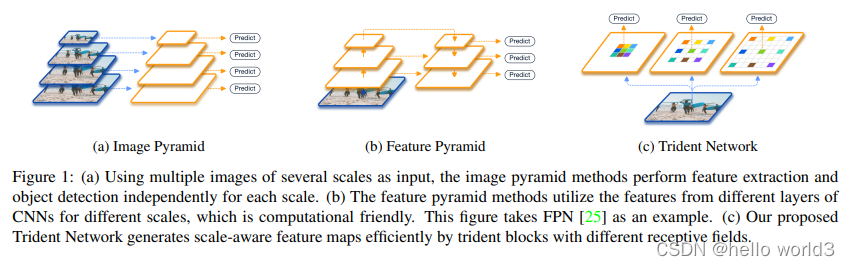
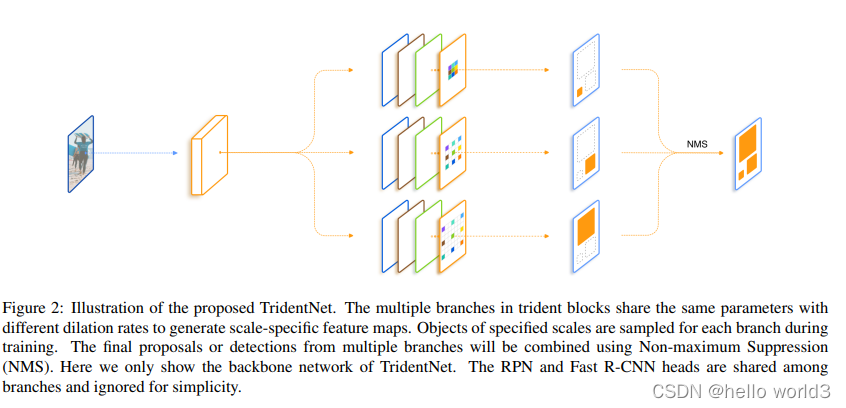
Scale-Aware Trident Networks
论文:Scale-Aware Trident Networks for Object Detection
代码:Scale-Aware Trident Networks Code
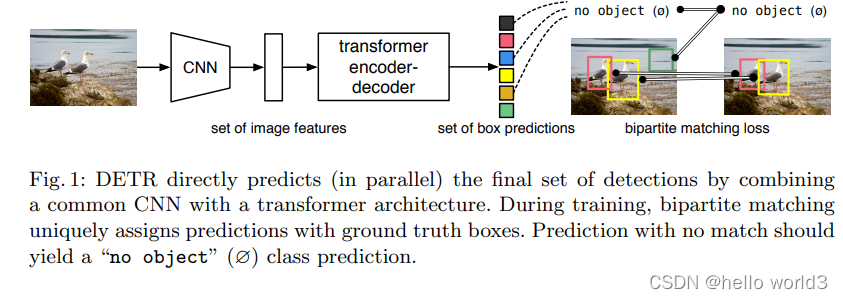
DETR
论文:End-to-End Object Detection with Transformers
代码:DETR Code

Dynamic R-CNN
论文:Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training
代码:Dynamic R-CNN Code



















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









