







MapReduce基本原理
MapReduce是一种需要在Hadoop集群上执行的分析程序,也就是说它可以分析的就是在HDFS上所保存的相关数据,在之前见到过一个单词统计程序,实际上现在也可以自己利用MapReduce来实现这样的单词统计程序。
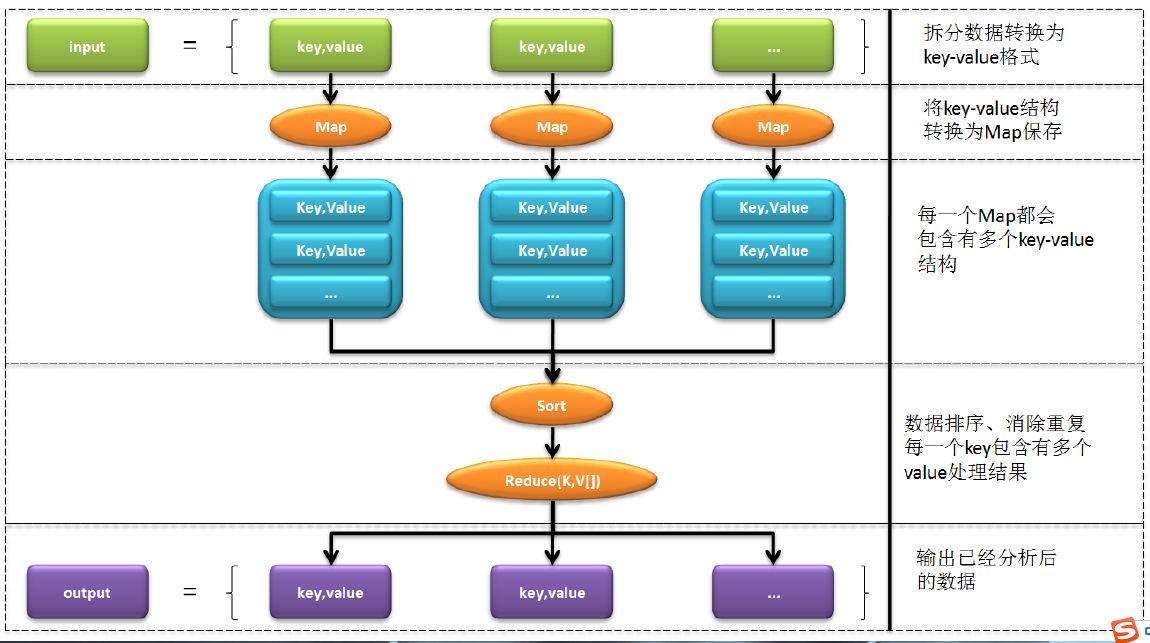
· 如果要想对数据进行分析,则需要有一个输入的数据信息存在,那么这个信息就要求保存在HDFS上;
在整个的处理过程里面,只有Map阶段以及Reduce阶段才需要开发人员进行具体的编写处理操作,而其它的开发步骤都会由Hadoop帮助用户自己完成,同时用户还需要去分配一个Job用于执行MapReduce。
在Java中编写Map处理
导入相应的Hadoop开发包
1、所有的Mapper的处理类都需要继承一个父类:org.apache.hadoop.mapreduce.Mapper,这个类的定义如下:
在通过HDFS读取数据的时候,每一次执行的Mapper接收的都是一行行的数据;
org.apache.hadoop.mapreduce.Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>具体参数的作用如下:
KEYIN:输入数据的KEY;
VALUEIN:表示真实输入的数据,现在所需要的内容;
KEYOUT:输出的Map中KEY类型;(Haddop中把字符串使用Text描述;)
VALUEOUT:输出的Map中的Value的类型;(Hadoop中把数字使用IntWritable类型描述)
private static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 读取每一行的数据,Map是根据换行作为读取的分割符;
String str = value.toString() ; // 取的每一行的内容
// 所有的单词要求按照空格进行拆分
String result [] = str.split(" "); // 按照空格拆分
// 将本行的数据变为一组Map的内容
for (int x = 0 ; x < result.length ; x ++) {
context.write(new Text(result[x]), new IntWritable(1)); // 将数据取出
}
}
}编写Reduce处理
对Map的数据进行再一次的处理,称为Reduce操作,而且一定要记住,在Map处理完成之后会存在有一个排序的操作形式,因为利用排序可以加快处理形式。
要想实现Reduce处理操作,那么一定要记住,需要继承一个父类: Reduce类定义:org.apache.hadoop.mapreduce.Reducer
private static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException,InterruptedException {
int sum = 0 ; // 统计总量
for (IntWritable wri : values) { // 取出所有的统计数据
sum += wri.get() ; // 进行数据的累加处理
}
context.write(new Text(key), new IntWritable(sum));
}
}定义Job
整个一次的MapReduce执行对于Hadoop而言都相当于启动了一个作业,也就是说在整个的作业的运行过程之中你需要明确的指定出本作业要使用的Map与Reduce程序的定义。
如果要想定义作业:org.apache.hadoop.mapreduce.Job;
public static void main(String[] args) throws Exception {
if (args.length != 2) { // 现在输入的参数个数不足,那么则应该退出程序
System.out.println("本程序的执行需要两个参数:HDFS输入路径 HDFS的输出路径");
System.exit(1); // 程序退出
}
Configuration conf = new Configuration() ; // 此时需要进行HDFS操作
String paths [] = new GenericOptionsParser(conf,args).getRemainingArgs() ; // 将输入的两个路径解析为HDFS的路径
// 需要定义一个描述作业的操作类
Job job = Job.getInstance(conf, "hadoop") ;
job.setJarByClass(WordCount.class); // 定义本次作业执行的类的名称
job.setMapperClass(WordCountMapper.class); // 定义本次作业完成所需要的Mapper程序类
job.setMapOutputKeyClass(Text.class); // 定义Map输出数据的Key的类型
job.setMapOutputValueClass(IntWritable.class); // 定义Map输出数据的Value的类型
job.setReducerClass(WordCountReducer.class); // 定义要使用的Reducer程序处理类
job.setOutputKeyClass(Text.class); // 最终输出统计结果的key的类型
job.setOutputValueClass(IntWritable.class); // 最终输出统计结果的value的类型
// 所有的数据都在HDFS上进行操作,那么就必须使用HDFS提供的程序进行数据的输入配置
FileInputFormat.addInputPath(job, new Path(paths[0])); // 定义输入的HDFS路径
FileOutputFormat.setOutputPath(job, new Path(paths[1]));// 定义统计结果的输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1); // 程序执行完毕后要进行退出
}如果要想执行定义好的作业不能够在本地上直接执行,一定要将程序变为jar文件发送到服务器(Hadoop)上执行。
将项目打包成.jar文件并上传至服务器中。
hadoop jar MapReduce.jar路径 要测试的文件路径 测试结果输出路径随后打开输出路径上的结果文件既可以观察统计结果。















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









