






逻辑回归通式定义如下:
{
p
(
z
i
)
=
1
1
+
e
−
z
i
z
i
=
θ
T
x
i
\begin{cases} p(z_i) = \frac {1}{1 + e^{-z_i}} \\ z_i = \theta^Tx_i \end{cases}
{p(zi)=1+e−zi1zi=θTxi
要想理解逻辑回归,我们需要看一下函数
p
p
p的图像,如下图:
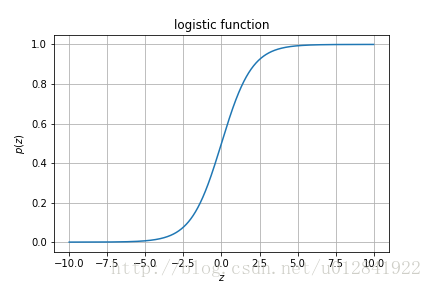
由图可知,在 z ∈ R z \in R z∈R的定义域中,函数 p p p将 z z z映射到 ( 0 , 1 ) (0, 1) (0,1)的值域中,其中 z = 0 z = 0 z=0时, p ( z ) = 0.5 p(z) = 0.5 p(z)=0.5。一种常见的对这个图的解释是 p ( x i ; θ ) = 1 1 + e − θ T x i p(x_i; \theta) = \frac {1}{1+e^{-\theta^Tx_i}} p(xi;θ)=1+e−θTxi1是事件 x i x_i xi发生的概率。
事件
x
i
x_i
xi发生与否其实也就是一个二分类问题。我们可以用标签
y
i
=
1
y_i = 1
yi=1表示事件
x
i
x_i
xi发生,标签
y
i
=
0
y_i = 0
yi=0表示事件
x
i
x_i
xi不发生。用函数
p
(
x
;
θ
)
p(x;\theta)
p(x;θ)表示事件
x
x
x发生的概率
P
r
(
Y
=
1
∣
X
=
x
)
Pr(Y=1 \vert X=x)
Pr(Y=1∣X=x)。因此,事件
x
x
x不发生的概率
P
r
(
Y
=
0
∣
X
=
x
)
Pr(Y=0 \vert X=x)
Pr(Y=0∣X=x)为
1
−
p
(
x
;
θ
)
1 - p(x;\theta)
1−p(x;θ)。我们可以用一个式子表示如上两种情况:
P
r
(
Y
=
y
i
∣
X
=
x
i
)
=
p
(
x
i
;
θ
)
y
i
(
1
−
p
(
x
i
;
θ
)
)
1
−
y
i
Pr(Y=y_i \vert X=x_i) = p(x_i; \theta)^{y_i} (1-p(x_i; \theta))^{1-y_i}
Pr(Y=yi∣X=xi)=p(xi;θ)yi(1−p(xi;θ))1−yi
从现在开始,我们应该对逻辑回归有了初步的认识。逻辑回归是一个分类算法,而非回归算法。本文主要分析其在二分类问题中的应用。逻辑回归以概率的方式来对数据进行分类。例如,设置阈值为 0.5 0.5 0.5,如果 P r ( Y = 1 ∣ X = x i ) ≥ 0.5 Pr(Y=1 \vert X=x_i) \ge 0.5 Pr(Y=1∣X=xi)≥0.5,则将数据 x i x_i xi标记为类 1 1 1,否则将其标记为类 0 0 0。 p ( x i ; θ ) = 0.5 p(x_i;\theta) = 0.5 p(xi;θ)=0.5其实就是一个超平面,平面之上的点组成 y i = 1 y_i = 1 yi=1的集合,平面之下的点组成 y i = 0 y_i = 0 yi=0的集合。总结一下我们的问题:已知 x i x_i xi和 y i y_i yi,求函数 p ( x i ; θ ) p(x_i; \theta) p(xi;θ)中的 θ \theta θ的取值。
首先,我先给出此问题的似然函数:
∏
i
=
1
m
P
r
(
Y
=
y
i
∣
X
=
x
i
)
\prod\limits_{i=1}^m Pr(Y=y_i \vert X=x_i)
i=1∏mPr(Y=yi∣X=xi)
为了理解这个最大似然估计函数,我们考虑一个简单的、却类似的问题。假设一个袋子里有若干颗白球和黑球,在10次有放回的抽取中,我抽到了8次黑球,2次白球。如何求袋子中黑白球的比例呢?我们可以利用最大似然估计:假设我抽取到黑球的概率为
p
p
p,那么我这次抽取得到8次黑球、2次白球的概率为:
P
=
p
8
∗
(
1
−
p
)
2
P = p^8*(1-p)^2
P=p8∗(1−p)2
我们用使这次抽取结果发生的概率 P P P最大化的 p ^ \hat p p^值去近似替代实际的 p p p值。
同样的道理,回到逻辑回归的问题中。我们要目前已知的标签集合
Y
Y
Y发生的概率最大化,求该情况下的
θ
\theta
θ的取值。因此:
L
(
θ
)
=
∏
i
=
1
m
P
r
(
Y
=
y
i
∣
X
=
x
i
)
=
∏
i
=
1
m
p
(
x
i
;
θ
)
y
i
(
1
−
p
(
x
i
;
θ
)
)
1
−
y
i
L(\theta) = \prod\limits_{i=1}^m Pr(Y=y_i \vert X=x_i) = \prod\limits_{i=1}^m p(x_i; \theta)^{y_i} (1-p(x_i; \theta))^{1-y_i}
L(θ)=i=1∏mPr(Y=yi∣X=xi)=i=1∏mp(xi;θ)yi(1−p(xi;θ))1−yi
对数似然函数为:
l
(
θ
)
=
log
(
L
(
θ
)
)
=
∑
i
=
1
m
log
[
p
(
x
i
;
θ
)
y
i
(
1
−
p
(
x
i
;
θ
)
)
1
−
y
i
]
=
∑
i
=
1
m
[
y
i
log
p
(
x
i
)
+
(
1
−
y
i
)
log
(
1
−
p
(
x
i
)
)
]
=
∑
i
=
1
m
[
log
(
1
−
p
(
x
i
)
)
+
y
i
(
log
p
(
x
i
)
−
log
(
1
−
p
(
x
i
)
)
)
]
=
∑
i
=
1
m
[
log
(
1
−
p
(
x
i
)
)
+
y
i
log
p
(
x
i
)
1
−
p
(
x
i
)
]
=
∑
i
=
1
m
[
log
(
1
−
1
1
+
e
−
θ
T
x
i
)
+
y
i
log
(
1
+
e
−
θ
T
x
i
)
−
1
1
−
(
1
+
e
−
θ
T
x
i
)
−
1
]
=
∑
i
=
1
m
[
log
e
−
θ
T
x
i
1
+
e
−
θ
T
x
i
+
y
i
log
1
(
1
+
e
−
θ
T
x
i
)
−
1
]
=
∑
i
=
1
m
[
log
1
e
θ
T
x
i
+
1
+
y
i
log
e
θ
T
x
i
]
=
∑
i
=
1
m
−
log
(
e
θ
T
x
i
+
1
)
+
∑
i
=
1
m
y
i
θ
T
x
i
\begin{aligned} & l(\theta) = \log(L(\theta)) = \sum\limits_{i=1}^m \log[p(x_i; \theta)^{y_i} (1-p(x_i; \theta))^{1-y_i}] \\ & = \sum\limits_{i=1}^m [y_i \log p(x_i) +(1-y_i)\log (1-p(x_i))] \\ & = \sum\limits_{i=1}^m [\log (1-p(x_i)) + y_i(\log p(x_i) - \log(1-p(x_i)))] \\ & = \sum\limits_{i=1}^m [\log (1-p(x_i)) + y_i\log \frac {p(x_i)}{1-p(x_i)}] \\ & = \sum\limits_{i=1}^m [\log (1-\frac {1}{1+e^{-\theta^Tx_i}}) + y_i\log \frac {(1+e^{-\theta^Tx_i})^{-1}}{1-(1+e^{-\theta^Tx_i})^{-1}}] \\ & = \sum\limits_{i=1}^m [\log \frac {e^{-\theta^Tx_i}}{1+e^{-\theta^Tx_i}} + y_i\log \frac {1}{(1+e^{-\theta^Tx_i}) -1}] \\ & = \sum\limits_{i=1}^m [\log \frac {1}{e^{\theta^Tx_i}+1} + y_i\log e^{\theta^Tx_i}] \\ & = \sum\limits_{i=1}^m -\log (e^{\theta^Tx_i}+1) + \sum\limits_{i=1}^m y_i\theta^Tx_i \\ \end{aligned}
l(θ)=log(L(θ))=i=1∑mlog[p(xi;θ)yi(1−p(xi;θ))1−yi]=i=1∑m[yilogp(xi)+(1−yi)log(1−p(xi))]=i=1∑m[log(1−p(xi))+yi(logp(xi)−log(1−p(xi)))]=i=1∑m[log(1−p(xi))+yilog1−p(xi)p(xi)]=i=1∑m[log(1−1+e−θTxi1)+yilog1−(1+e−θTxi)−1(1+e−θTxi)−1]=i=1∑m[log1+e−θTxie−θTxi+yilog(1+e−θTxi)−11]=i=1∑m[logeθTxi+11+yilogeθTxi]=i=1∑m−log(eθTxi+1)+i=1∑myiθTxi
求
l
(
θ
)
l(\theta)
l(θ)对
θ
j
\theta_j
θj的偏导数:
∂
l
(
θ
)
∂
θ
j
=
∂
θ
j
[
∑
i
=
1
m
−
log
(
e
θ
T
x
i
+
1
)
+
∑
i
=
1
m
y
i
θ
T
x
i
]
=
∑
i
=
1
m
−
e
θ
T
x
i
x
i
j
1
+
e
θ
T
x
i
+
∑
i
=
1
m
y
i
x
i
j
=
∑
i
=
1
m
[
y
i
−
e
θ
T
x
i
1
+
e
θ
T
x
i
]
x
i
j
=
∑
i
=
1
m
[
y
i
−
1
1
+
e
−
θ
T
x
i
]
x
i
j
=
∑
i
=
1
m
[
y
i
−
p
(
x
i
;
θ
)
]
x
i
j
\begin{aligned} & \frac {\partial l(\theta)}{\partial \theta_j} = \frac {\partial}{\theta_j} [\sum\limits_{i=1}^m -\log (e^{\theta^Tx_i}+1) + \sum\limits_{i=1}^m y_i\theta^Tx_i] \\ & = \sum\limits_{i=1}^m -\frac {e^{\theta^Tx_i}x_i^j}{1+e^{\theta^Tx_i}} + \sum\limits_{i=1}^m y_ix_i^j \\ & = \sum\limits_{i=1}^m[y_i - \frac {e^{\theta^Tx_i}}{1+e^{\theta^Tx_i}}]x_i^j \\ & = \sum\limits_{i=1}^m[y_i - \frac {1}{1+e^{-\theta^Tx_i}}]x_i^j \\ & = \sum\limits_{i=1}^m[y_i - p(x_i;\theta)]x_i^j \\ \end{aligned}
∂θj∂l(θ)=θj∂[i=1∑m−log(eθTxi+1)+i=1∑myiθTxi]=i=1∑m−1+eθTxieθTxixij+i=1∑myixij=i=1∑m[yi−1+eθTxieθTxi]xij=i=1∑m[yi−1+e−θTxi1]xij=i=1∑m[yi−p(xi;θ)]xij
最后,通过梯度上升求
l
(
θ
)
l(\theta)
l(θ)最大化时
θ
\theta
θ的近似解:
θ
j
:
=
θ
j
+
α
∂
l
(
θ
)
∂
θ
j
\theta_j := \theta_j + \alpha \frac {\partial l(\theta)}{\partial \theta_j}
θj:=θj+α∂θj∂l(θ)
将上式写成向量形式,即: θ = θ + α ▽ l ( θ ) \theta = \theta + \alpha \bigtriangledown l(\theta) θ=θ+α▽l(θ)。















 6393
6393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









