







目录
过拟合欠拟合
模型学习能力过强获取了特殊特征/学习能力低下
评估方法
引入测试集testing set,测试模型的评估能力,近似泛化误差。
将数据集拆分为训练集及测试集的常见方法
1.留出法(hold-out)
即将 数据集 拆分为互斥的两个集合 ,训练集比例在4/5~2/3 。
此外需要关注两个集合的数据类型分布比例要较为一致。
2.交叉验证法(cross validation)
将数据集分割为k个互斥的子集,且保证数据分布的一致性。取k-1个子集作为训练集,1个作为测试集。进行k次训练以及测试,返回结果的均值。也称k折交叉验证。 k 常取 10.
3.自助法(bootstrapping)
基于自助采样法。
对于包含m个样本的数据集D,进行m次有放回的随机取样copy,m次的copy结果形成数据集D1。
D中大约有0.368的样本不会出现在D1中。通常将D1作为训练集,将D-D1作为测试集。
故此可以有效的避免由于训练样本规模不同导致的误差。此法常用于小训练集。
性能度量
1.错误率
即错误分类的样本占据总样本的比例
2.精度
正确分类的样本占据总样本的比例
3.混淆矩阵(confusion mareix)

4.准确率(precision)

5.召回率(recall)

6.PR图

曲线的包含的面积越大 越说明模型的pr值双高 也就表明模型具有更好的性能。
7.平衡点(break-even point /BEP)
P=R时,取值较大的模型性能更优
8.F1度量
根据调和平均推导
此时对于PR的重要性,不做区分,认为两者一样重要

9.F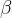 度量
度量
此为F1的一般形式,考虑PR的重要性偏好。

β值反映的是偏好情况,当两者不具有偏好区别时,β = 1,退化为F1 。
β > 1,认为召回率R具有更大的偏好。
β < 1,认为精确率P具有更大的偏好。
10.宏微F1
存在多个混淆矩阵时,进行综合考察,有两种做法。
第一种,分别算出PR ,取平均 ,得到的是宏P R F1。(macro-P...)
第二种,求出所有混淆矩阵的元素平均值,如TP平均,再基于平均值计算P R F1。得到的是微P R F1。(micro-P...)
11.ROC以及AUC
ROC
ROC为受试者工作特征曲线(receiver operating characteristic)
曲线的横纵坐标分别是FPR(False Positive Rate)和TPR(True Positive Rate)

曲线的绘制方式是,将分类阈值遍历每个样例的预测值,穷尽分类结果,每次得到的混淆矩阵都可以在ROC图中对应一个坐标。曲线并不视作函数,每个点位可以理解为一种分类器。也就是把各种不同阈值的分类情况表征在一张图中。
AUC(area under ROC curve)
即ROC曲线下的面积。
其值越大,表征模型的分类能力越强。如AUC = 1 时,无论设置什么阈值都能够正确分类。(实际不太可能)
12.代价敏感
针对不同类型的分类错误给予不同代价。
例如二分类:
| 真实类别 | 预测类别预测类别 | |
| 0类 | 1类 | |
| 0类 | 0 | cost01 |
| 1类 | cost10 | 0 |
由此可以构造损失函数,此处效果考虑的是 代价之间的比例 而不是 数值大小。















 833
833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









