







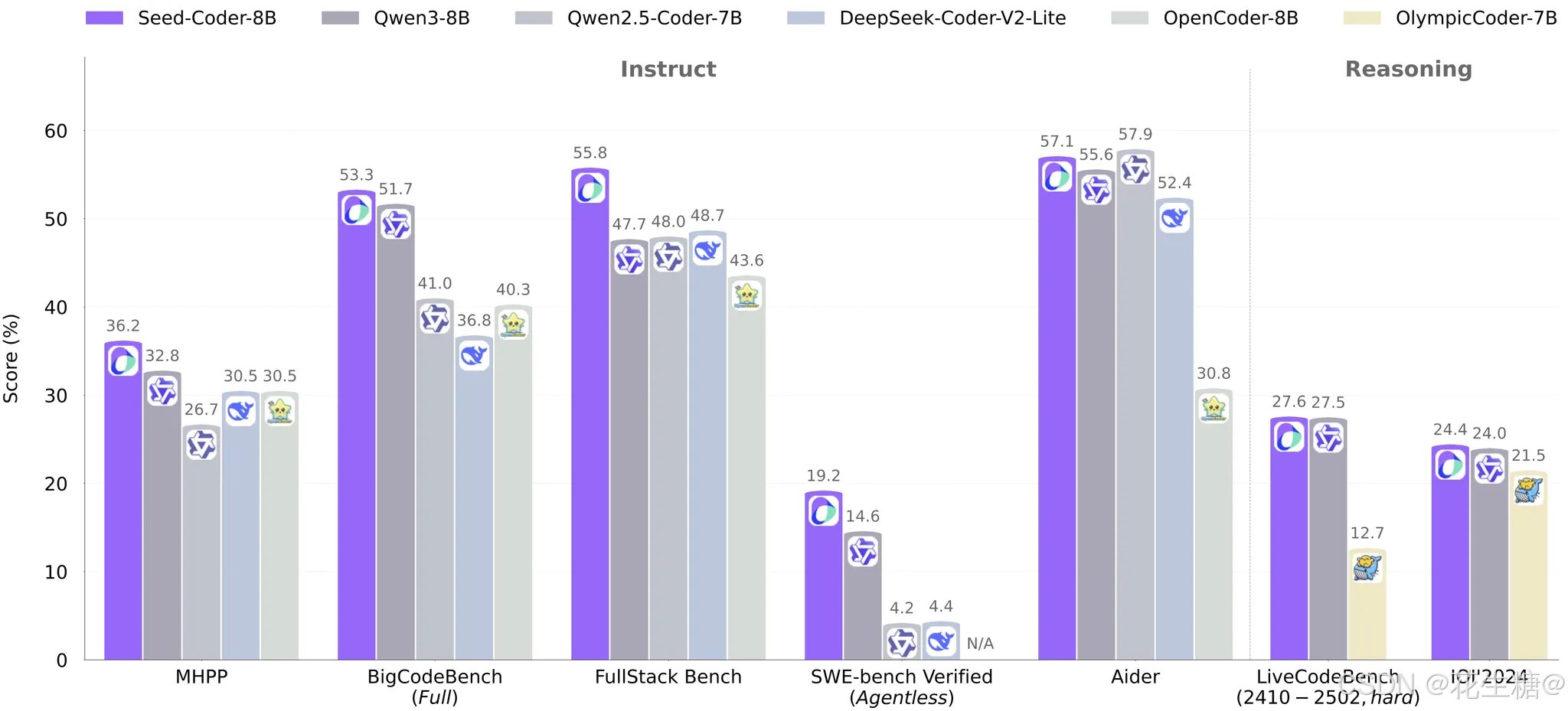
 字节跳动近期推出了新一代代码大模型 Seed-Coder,专为代码生成、补全、编辑及逻辑推理任务设计。该模型基于 8B 参数量 的架构,包含 Base、Instruct、Reasoning 三种变体,支持 32K 上下文长度,在性能上超越了 Qwen3-8B 和 Qwen2.5-Coder-7B 等竞品模型。Seed-Coder 的核心创新在于其 “以模型为中心的数据整理设计”,通过自动化筛选与处理代码数据,显著减少人工干预,提升数据处理效率与模型质量。该模型已开源至 GitHub 与 Hugging Face,开发者可直接部署或微调以适配各类代码场景。
字节跳动近期推出了新一代代码大模型 Seed-Coder,专为代码生成、补全、编辑及逻辑推理任务设计。该模型基于 8B 参数量 的架构,包含 Base、Instruct、Reasoning 三种变体,支持 32K 上下文长度,在性能上超越了 Qwen3-8B 和 Qwen2.5-Coder-7B 等竞品模型。Seed-Coder 的核心创新在于其 “以模型为中心的数据整理设计”,通过自动化筛选与处理代码数据,显著减少人工干预,提升数据处理效率与模型质量。该模型已开源至 GitHub 与 Hugging Face,开发者可直接部署或微调以适配各类代码场景。
核心亮点
1. 多模式变体,适配多样化需求
- Base 版本:专注于基础代码生成与补全,适用于通用编程任务(如函数实现、语法纠正)。
- Instruct 版本:优化指令跟随能力,支持复杂指令解析与多步骤代码生成(如“编写一个 Python 脚本,解析 JSON 文件并输出统计结果”)。
- Reasoning 版本:强化逻辑推理能力,适用于算法设计、调试建议及代码优化(如“分析以下代码的性能瓶颈并提出改进方案”)。
2. 32K 上下文长度,支持超长代码处理
- 长文档兼容:能够处理完整的大型代码库、技术文档或跨文件逻辑关系,避免传统模型因上下文截断导致的语义断裂问题。
- 多文件协同:通过上下文窗口整合多个文件内容,实现跨文件代码生成与依赖分析(例如根据
requirements.txt生成项目结构)。
3. 自动化数据整理,提升训练效率
- 模型驱动筛选:利用 Seed-Coder 本身作为数据筛选器,自动识别高质量代码片段(如去除低效代码、冗余注释),减少人工标注成本。
- 动态清洗流程:通过模型预处理阶段过滤噪声数据(如错误语法、过时 API 调用),确保训练数据的准确性与一致性。
4. 性能优势:超越主流代码模型
- 基准测试表现:在 HumanEval、MBPP、GSM8K 等代码生成与推理基准上,Seed-Coder 的准确率与代码通过率显著优于 Qwen3-8B 和 Qwen2.5-Coder-7B。
- 低延迟响应:优化推理引擎后,模型在生成复杂代码时仍能保持高吞吐量(如 0.8s/Token 的生成速度)。
技术架构解析
1. 模型设计
- 参数规模:8B 参数量,采用 Mixture-of-Experts(MoE)架构,在保证性能的同时降低计算资源消耗。
- 训练数据:基于字节内部代码仓库(如 GitHub、企业级项目)与公开代码数据集(如 CodeSearchNet、BigQuery)混合训练,覆盖多种编程语言(Python、Java、C++、JavaScript 等)。
2. 数据处理流程
- 原始数据收集:从代码仓库、论坛(如 Stack Overflow)、API 文档等渠道抓取代码片段与上下文描述。
- 模型预筛选:利用 Seed-Coder 的 Base 版本自动过滤低质量代码(如语法错误、重复内容)。
- 增强标注:对筛选后的数据进行语义增强(如添加注释、重构逻辑),生成高质量训练样本。
3. 推理优化
- 上下文压缩:通过滑动窗口机制动态调整上下文长度,确保关键代码段始终保留在模型视野内。
- 缓存加速:对高频代码模式(如标准库调用)进行缓存,减少重复计算。
典型应用场景
1. 开发者辅助工具
- 代码补全:在 IDE 中实时生成函数参数、循环结构或异常处理代码。
- 调试建议:分析错误日志并定位潜在问题(如“此段代码可能导致内存泄漏”)。
- 文档生成:自动生成 API 注释或模块说明文档。
2. 教育与培训
- 编程教学:为初学者提供分步代码示例与错误修正指导。
- 作业批改:自动评估学生代码的正确性与风格规范。
3. 自动化测试
- 单元测试生成:根据代码逻辑自动生成测试用例与边界条件验证。
- 性能优化:识别低效算法并提出替代方案(如将 O(n²) 算法替换为 O(n log n) 实现)。
部署与使用指南
1. 环境准备
- 硬件要求:建议使用 NVIDIA A100 或 H100 GPU,支持 8GB 显存的设备可运行量化版本。
- 依赖项:安装 PyTorch 2.1+、Transformers 4.36+、DeepSpeed 0.12+。
2. 快速部署
- 克隆项目:
git clone https://github.com/ByteDance-Seed/Seed-Coder.git cd Seed-Coder - 安装依赖:
pip install -r requirements.txt - 加载模型:
from transformers import AutoModelForCausalLM, AutoTokenizer model = AutoModelForCausalLM.from_pretrained("ByteDance-Seed/Seed-Coder-8B-Instruct") tokenizer = AutoTokenizer.from_pretrained("ByteDance-Seed/Seed-Coder-8B-Instruct")
3. 使用示例
prompt = """
# 任务:编写一个 Python 函数,计算列表中所有偶数的平方和。
def even_square_sum(numbers):
# TODO: 实现逻辑
pass
"""
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)) 未来展望
Seed-Coder 的发布标志着代码生成领域迈入新阶段,未来可能在以下方向进一步突破:
- 多模态扩展:结合图像、表格数据生成可视化代码(如根据图表生成 Matplotlib 代码)。
- 跨语言支持:强化对低资源语言(如 Rust、Go)的适配能力。
- 联邦学习:在保护用户隐私的前提下,通过分布式训练提升模型泛化能力。
结语
Seed-Coder 通过创新的数据处理机制与高性能架构,为开发者提供了更高效、精准的代码辅助工具。无论是日常编码、教育实践,还是自动化测试,它都能显著提升生产力。随着开源社区的贡献与技术迭代,Seed-Coder 有望成为代码生成领域的标杆模型。
🔗 GitHub 地址:https://github.com/ByteDance-Seed/Seed-Coder
📦 Hugging Face 模型页面:https://huggingface.co/ByteDance-Seed/Seed-Coder-8B-Instruct



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











