







近来趁项目间隔期,工作不是太多,也在利用空余时间把数据分析的完整流程用Python实现一遍,也恰好整理下这几年手头的一些资料,顺序可能比较乱,后期再慢慢调整。
数据的标准化(normalization)是将数据按照一定规则缩放,使之落入一个小的特定区间。这样去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是0-1标准化和Z标准化,当然,也有一些其他的标准化方法,用在不同场景,这里主要介绍几种常用的方法。
1、Min-Max标准化(Min-Max normalization)
也称离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
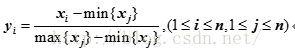
其中max{xj}为样本数据的最大值,min{ xj }为样本数据的最小值。这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
2、Z-score 标准化(zero-mean normalization)
也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:

其中x为所有样本数据的均值,s 为所有样本数据的标准差。
经过 Z-score 标准化后,各变量将有约一半观察值的数值小于0,另一半观察值的数值大于0,变量的平均数为0,标准差为1。经标准化的数据都是没有单位的纯数量。它是当前用得最多的数据标准化方法。如果特征非常稀疏,并且有大量的0(现实应用中很多特征都具有这个特点),Z-score 标准化的过程几乎就是一个除0的过程,结果不可预料。
3正则化(Normalization)
正则化的过程是将每个样本缩放到单位范数(每个样本的范数为1),如果后面要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。 Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(L1-norm,L2-norm)等于1。
p-范数的计算公式:

该方法主要应用在文本分类和聚类中。例如,对于两个TF-IDF向量的L2-norm进行点积,就可以得到这两个向量的余弦相似性。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









