






1、StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
中文标题:StableNormal:减少扩散方差以实现稳定且锐利的法线


简介:本文介绍了一种创新解决方案,旨在优化单目彩色输入(包括静态图片与动态视频)的高精度表面法向量预测,这一领域近期因采纳扩散先验而迎来重大突破。尽管前人研究已取得显著进展,但仍存在推理随机性与确定性任务本质之间的矛盾,加之繁复的整合步骤拖慢了整体效率。为克服这些挑战,我们提出StableNormal,一种旨在降低推理不确定性的方法,它生成精确且清晰的法向量预测,同时避免了额外的整合环节。StableNormal在恶劣成像环境(如极端光照条件、图像模糊及低质量输入)下展现出了卓越的适应能力,对于透明或反光表面以及复杂多物场景亦有出色表现。
具体而言,StableNormal采用自顶向下的策略,首先借助一步法向量估算器(YOSO)快速生成初步但可信的法向量预测,随后通过语义指导的细化流程(SG-DRN)对预测结果进行精炼,以恢复关键的几何细节。在诸如DIODE-indoor、iBims、ScannetV2和NYUv2等标准数据集上的实证分析,以及在表面重建与法向量增强等下游任务中的优异表现,均证明了StableNormal的有效性和竞争力。这些成果彰显了StableNormal在确保法向量预测既“稳定”又“精细”方面的独特优势,标志着利用扩散先验进行确定性估计的一次开创性尝试。
为了促进学术界与产业界的广泛应用,我们已在hf.co/Stable-X平台上开源了StableNormal的相关代码与模型,旨在推动该领域的进一步发展与创新。
2、FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models
中文标题:FreeTraj:视频扩散模型中的免调整轨迹控制


简介:扩散模型在视频生成领域的卓越表现,已点燃了研究界对生成进程中融入路径调节机制的热情。尽管当前学术探讨多聚焦于依托训练的策略,如条件适配器,然而我们认为,扩散模型内蕴的灵活性足以支撑起生成内容的精妙调控,而无需附加训练环节。本研究遂提出一创新框架,无需任何微调,即能通过精准指引噪声生成与注意力分配,实现视频生成路径的自主控制。
具体讲,我们的工作可归纳为三步走:首先,我们揭示并剖析了几项启发式的案例,阐述了初始噪声对生成物动态轨迹的塑造作用。继而,我们推出了FreeTraj——一款免调参方案,它巧妙地调整了噪声采样流程及注意力机制,从而达成了对视频生成路径的精确操控。更进一步,我们对FreeTraj进行了升级拓展,使其能够应对时长更久、尺寸更大的视频生成需求,同时保持路径可控这一核心优势。借助上述设计,用户享有双重选择:既可手工定制路径,亦可启用LLM轨迹规划器以自动化路径生成。经由一系列综合实验,我们确证了此方法在强化视频扩散模型路径调控能力上的卓著成效,为生成式视频技术的前沿探索注入了新活力。
3、Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
中文标题:Cambrian-1:完全开放、以视觉为中心的多模式法学硕士探索
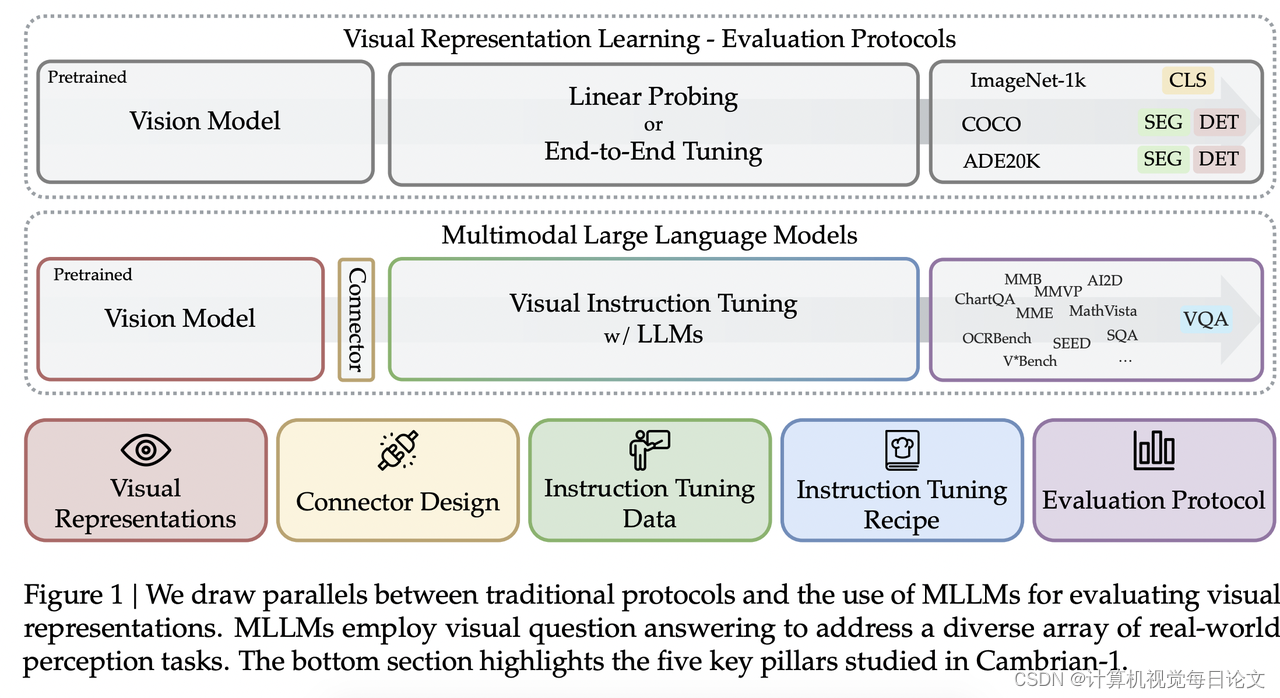
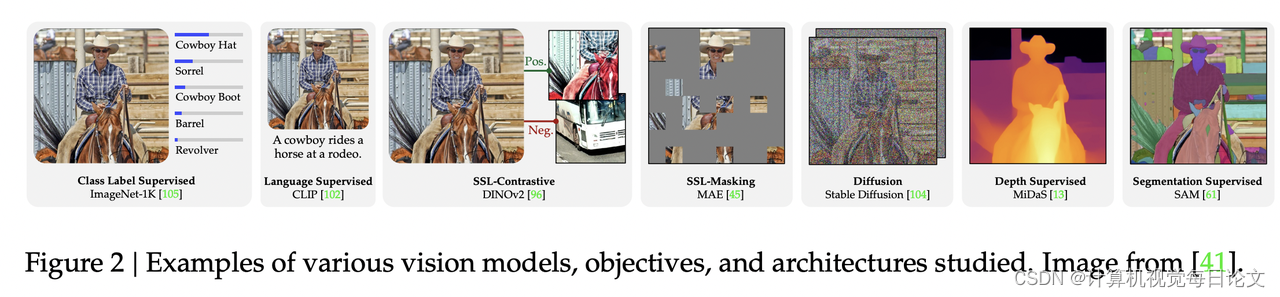
简介:本文献聚焦于Cambrian-1,一个视觉导向的多模态大型语言模型(MLLMs)系列。尽管强化的语言模型能显著提升多模态处理能力,视觉组件的设计决策却往往缺乏深入探究,与视觉表现学习领域的进展相脱节。这一鸿沟限制了模型在现实世界中对感官信息的精准理解。为填补此空白,本研究利用MLLMs与视觉引导微调作为桥梁,对一系列视觉表示进行评估,涵盖基于超自监督、强监督或二者结合的不同模型与架构,实验覆盖超过20种视觉编码器。我们深度剖析当前MLLM评估标准的局限性,解决跨任务结果整合与解析的难题,并引入一项全新的视觉导向基准——CV-Bench。为优化视觉理解,我们创新性提出空间视觉聚合器(SVA),一种动态、空间感知的连接机制,有效整合高分辨率视觉特征与MLLMs,同时精简令牌数量。此外,我们还探讨了从公开资源中筛选高质量视觉引导微调数据的方法,强调数据源平衡与分布多样性的重要性。综上所述,Cambrian-1不仅在性能上达到业界领先水平,更作为一份全面、开放的MLLMs视觉引导微调指南。我们分享模型权重、源代码、辅助工具、数据集以及详细的微调与评估流程。我们期待这一成果能够激发并加速多模态系统与视觉表现学习领域的革新与发展。
















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









